Prácticas recomendadas para la gestión de logs
Datadog Log Management recopila, procesa, archiva, explora y monitoriza tus logs para que puedas visualizar los problemas de tu sistema. Sin embargo, puede ser difícil obtener el nivel adecuado de visibilidad de tus logs y el rendimiento de los logs puede variar mucho, lo que crea un uso inesperado de los recursos.
Por tal motivo, esta guía te mostrará varias prácticas recomendadas para la gestión de logs y configuraciones de cuenta que te brindan flexibilidad para la gestión, la atribución de uso y el control del presupuesto. Más concretamente, verás cómo puedes:
Esta guía también explica cómo puedes monitorizar el uso de logs:
Si quieres transformar tus logs u ocultar datos confidenciales en tus logs antes de que abandonen tu entorno, consulta cómo puedes agregar, procesar y transformar tus datos de logs con pipelines de observabilidad.
Configuración de la cuenta de logs
Configurar varios índices para la segmentación de logs
Configura varios índices si deseas segmentar tus logs para diferentes periodos de retención o cuotas diarias, monitorización de uso y facturación.
Por ejemplo, si tienes logs que sólo deben conservarse durante 7 días, mientras que otros deben conservarse durante 30 días, utiliza varios índices para separar los logs según los dos periodos de conservación.
Para configurar varios índices:
- Ve a Índices de logs.
- Haz clic en New Index (Nuevo índice) o en Add a new index (Añadir un nuevo índice).
- Introduce un nombre para el índice.
- Introduce la consulta de búsqueda para filtrar los logs que quieres tener en este índice.
- Establece la cuota diaria para limitar el número de logs que se almacenan en un índice por día.
- Establece el periodo durante el cual queres conservar estos logs.
- Haz clic en Save (Guardar).
Establecer cuotas diarias en tus índices puede ayudar a evitar excesos en la facturación cuando se añaden nuevos orígenes de logs o si un desarrollador cambia involuntariamente los niveles de gestión de logs al modo de depuración. Consulta Alerta de índices que alcanzan su cuota diaria para conocer cómo configurar una monitorización que avise cuando se alcanza un porcentaje de la cuota diaria dentro de las últimas 24 horas.
Configurar el almacenamiento para una retención prolongada
Si deseas retener logs durante un tiempo prolongado mientras mantienes velocidades de consulta similares a las de la indexación estándar, configura Flex Logs. Este nivel es el más adecuado para logs, que requiere una retención más prolongada y ocasionalmente necesita consultas urgentes. Flex Logs desvincula los costos de almacenamiento de los de cálculo, por lo que puedes retener de forma rentable más logs durante más tiempo sin sacrificar la visibilidad. Los logs que deben consultarse con frecuencia deben almacenarse en índices estándar.
Crear varios archivos para el almacenamiento a largo plazo
Si quieres almacenar tus logs durante periodos de tiempo más prolongados, configura Archivos de logs para enviar tus logs a un sistema optimizado para el almacenamiento, como Amazon S3, Azure Storage o Google Cloud Storage. Cuando quieras utilizar Datadog para analizar esos logs, utiliza Log RehydrationTM para recuperar esos logs de nuevo en Datadog. Con varios archivos, puedes segmentar logs por motivos de cumplimiento y mantener un control sobre los costes de recuperación.
Configura el tamaño máximo de escaneado para gestionar las costosas rehidrataciones
Establece un límite para el volumen de logs que pueden recuperarse al mismo tiempo. Al configurar un archivo, puedes definir el volumen máximo de datos de logs que se pueden analizar para su recuperación. Para obtener más información, consulta Definir el tamaño máximo de análisis.
Configurar el control de acceso basado en roles (RBAC) para roles personalizados
Existen tres roles predeterminados de Datadog: Administrador, Estándar y Solo lectura. También puedes crear roles personalizados con conjuntos de permisos únicos. Por ejemplo, puedes crear un rol que restrinja la modificación de las políticas de conservación de índices para los usuarios, a fin de evitar picos de costes no deseados. Del mismo modo, puedes restringir quién puede modificar las configuraciones de análisis de logs para evitar cambios no deseados en formatos y estructuras bien definidos de logs.
Para configurar roles personalizados con permisos:
- Inicia sesión en Datadog como administrador.
- Ve a Organization Settings > Roles (Parámetros de organización > Roles).
- Para habilitar los roles personalizados, haz clic en el engranaje de la parte superior izquierda y, a continuación, en Enable (Habilitar).
- Una vez habilitados, haz clic en New Role (Nuevo rol).
- Introduce un nombre para el nuevo rol.
- Selecciona los permisos para el rol. Esto te permite restringir el acceso a determinadas acciones, como la recuperación de logs y la creación de métricas basadas en logs. Para obtener más información, consulta los permisos de Log Management.
- Haz clic en Save (Guardar).
Consulta Cómo configurar el control de acceso basado en roles (RBAC) para logs para obtener una guía paso a paso sobre cómo configurar y asignar un rol con permisos específicos para un ejemplo de caso de uso.
Monitorizar el uso de logs
Puedes monitorizar el uso de logs configurando lo siguiente:
Alertas para picos inesperados de tráfico de logs
Métricas de uso de logs
Por defecto, las métricas de uso de logs están disponibles para realizar un seguimiento del número de logs consumidos, bytes consumidos y logs indexados. Estas métricas son gratuitas y se conservan durante 15 meses:
datadog.estimated_usage.logs.ingested_bytesdatadog.estimated_usage.logs.ingested_events
Consulta Monitores para la detección de anomalías para conocer cómo puedes crear monitores de anomalías utilizando métricas de uso.
Nota: Datadog recomienda establecer la unidad en byte para datadog.estimated_usage.logs.ingested_bytes en la página de resumen de métricas:
Monitores de detección de anomalías
Crea un monitor para la detección de anomalías a fin de alertar sobre cualquier pico inesperado de indexación de logs:
- Ve a Monitors > New Monitor (Monitores > Nuevo monitor) y selecciona Anomaly (Anomalía).
- En la sección Define the metric (Definir la métrica), selecciona la métrica
datadog.estimated_usage.logs.ingested_events. - En el campo from (de), añade la etiqueta (tag)
datadog_is_excluded:false para monitorizar los logs indexados y no los consumidos. - En el campo sum by (sumar por), añade las etiquetas
service y datadog_index para recibir una notificación si un servicio específico se dispara o deja de enviar logs en cualquier índice. - Configura las condiciones de alerta para que coincidan con tu caso de uso. Por ejemplo, configura el monitor para que alerte si los valores evaluados están fuera de un rango esperado.
- Añade un título para la notificación y un mensaje con instrucciones para actuar. Por ejemplo, esta es una notificación con enlaces contextuales:
An unexpected amount of logs has been indexed in the index: {{datadog_index.name}}
1. [Check Log patterns for this service](https://app.datadoghq.com/logs/patterns?from_ts=1582549794112&live=true&to_ts=1582550694112&query=service%3A{{service.name}})
2. [Add an exclusion filter on the noisy pattern](https://app.datadoghq.com/logs/pipelines/indexes)
- Haz clic en Create (Crear).
Alerta cuando un volumen de logs indexados supera un umbral especificado
Configura un monitor para alertar si un volumen de logs indexados en cualquier contexto de tu infraestructura (por ejemplo, service, availability-zone, etc.) está aumentando inesperadamente.
- Ve al Explorador de logs.
- Introduce una consulta de búsqueda que incluya el nombre del índice (por ejemplo,
index:main) para capturar el volumen de logs que quieres monitorizar. - Haz clic en More… (Más) y selecciona Create monitor (Crear monitor).
- Añade etiquetas (por ejemplo, servicios
host, , etc.) al campo group by (agrupar por). - Completa Alert threshold (Umbral de alerta) para tu caso de uso. Opcionalmente, completa Warning threshold (Umbral de alerta).
- Añade un título de notificación, por ejemplo:
Unexpected spike on indexed logs for service {{service.name}}
- Añade un mensaje, por ejemplo:
The volume on this service exceeded the threshold. Define an additional exclusion filter or increase the sampling rate to reduce the volume.
- Haz clic en Create (Crear).
Alerta sobre el volumen de logs indexados desde principios de mes
Aproveche la métrica datadog.estimated_usage.logs.ingested_events filtrada en datadog_is_excluded:false para contar solo los logs indexados y la ventana acumulativa de monitor (noun) de métricas para monitorizar el número desde principios de mes.
Alertas de índices que alcanzan su cuota diaria
Establece una cuota diaria en los índices para evitar indexar más de un número determinado de logs al día. Si un índice tiene una cuota diaria, Datadog recomienda que se configure el monitor que notifica sobre el volumen de ese índice para alertar cuando se alcance el 80% de esta cuota en las últimas 24 horas.
Se genera un evento cuando se alcanza la cuota diaria. Estos eventos tienen la tag (etiqueta) datadog_index que incluye el nombre del índice. Por lo tanto, cuando se haya generado este evento, puedes crear una faceta en la tag (etiqueta) datadog_index, de modo que puedas utilizar datadog_index en el step (UI) / paso (generic) group by para configurar un monitor (noun) de varias alertas.
Para configurar un monitor que alerte cuando se alcanza la cuota diaria para un índice:
- Ve a Monitors > New Monitor (Monitores > Nuevo monitor) y selecciona Event (Evento).
- Introduce:
source (fuente):datadog datadog_index:* "daily quota reached" en la sección Define the search query (Definir la consulta de búsqueda). Incluye datadog_index:* para asegurarte de que solo se seleccionen los eventos relacionados con el índice. - En el campo Count of (Número de), añade
datadog_index para agrupar por índice. Esto actualiza la consulta de modo que se lea Show Count of * by datadog_index (datadog_index). - Para Evaluate the query over (Evaluar la consulta sobre), selecciona current day (día actual). Para Starting at (Iniciar a las), selecciona la hora a la que se reinician los índices. Esto mantiene el monitor (noun) en estado de alerta hasta el reinicio de la cuota. Este es un ejemplo de cómo se ve la consulta de búsqueda cuando se define en Datadog:
- En la sección Set alert conditions (Establecer condiciones de alerta), selecciona
above or equal to e introduce 1 para Alert threshold (Umbral de alerta). - Añade un título de notificación y un mensaje en la sección Configure notifications and automations (Configurar notificaciones y automatizaciones). El botón Multi Alert (Alerta múltiple) se selecciona automáticamente porque el monitor está agrupado por
datadog_index(datadog_index). - Haz clic en Save (Guardar).
Nota: La tag (etiqueta) datadog_index(datadog_index) solo está disponible cuando ya se ha generado un evento.
Este es un ejemplo del aspecto de la notificación en Slack:
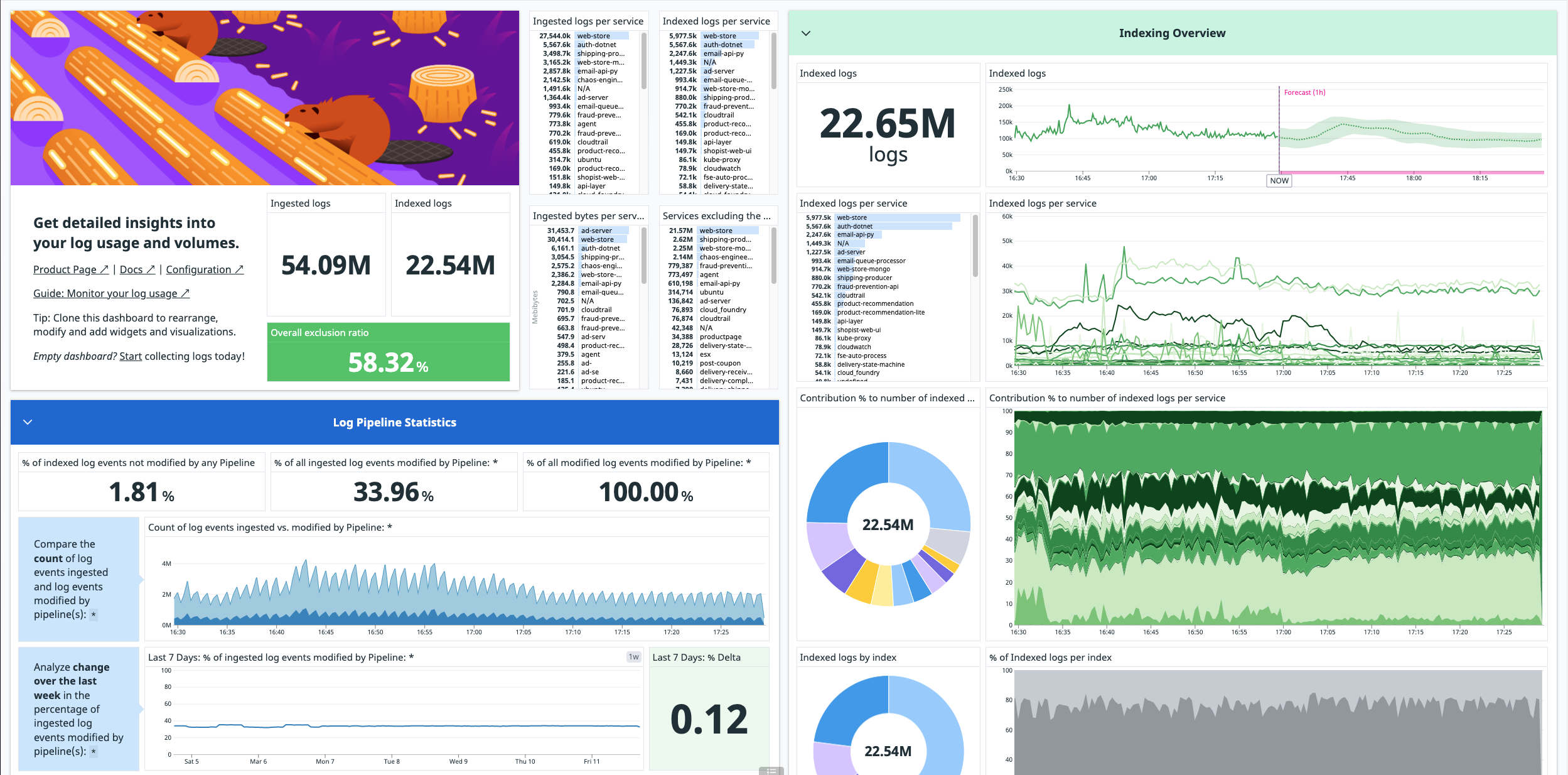
Revisar el dashboard de uso estimado
Una vez que empieces a consumir logs, se instalará automáticamente en tu cuenta un dashboard listo para utilizar que resume las métricas del uso de logs.
Nota: Las métricas utilizadas en este dashboard son estimaciones y pueden diferir de las cifras de facturación oficiales.
Para encontrar este dashboard, ve a Dashboards > Dashboards List (Dashboards > Listas de dashboards) y busca Log Management - Estimated Usage (Log Management - Uso estimado).
Establecer filtros de exclusión en logs de gran volumen
Cuando haya alertas de los monitores de uso, puedes configurar filtros de exclusión y aumentar la frecuencia de muestreo para reducir el volumen. Consulta Filtros de exclusión para saber cómo configurarlos. También puedes utilizar Patrones de logs para agrupar e identificar logs de gran volumen. A continuación, en el panel lateral del patrón de logs, haz clic en Add Exclusion Filter (Añadir filtro de exclusión) para añadir un filtro que impida la indexación de esos logs.
Incluso si utilizas filtros de exclusión, puedes visualizar tendencias y anomalías sobre todos tus datos de logs, utilizando las métricas basadas en logs. Para obtener más información, consulta Generar métricas a partir de logs consumidos.
Si deseas evitar fugas de datos y limitar los riesgos de incumplimiento, utiliza Sensitive Data Scanner para identificar, etiquetar y, opcionalmente, redactar o aplicar hash a los datos confidenciales. Por ejemplo, puedes buscar números de tarjetas de crédito, números de ruta bancaria y claves de API en tus logs, spans (tramos) de APM y eventos de RUM. Consulta Sensitive Data Scanner para saber cómo configurar reglas de análisis para determinar qué datos analizar.
Nota: Sensitive Data Scanner es un producto que se factura por separado.
Habilitar Audit Trail para ver las actividades de los usuarios
Si quieres ver las actividades de los usuarios, como quién ha cambiado las opciones de conservación de un índice o quién ha modificado un filtro de exclusión, habilita Audit Trail para ver estos eventos. Consulta Eventos de Audit Trail para obtener una lista de los eventos específicos de plataformas y productos que están disponibles. Para habilitar y configurar Audit Trail, sigue los pasos que se indican en la documentación de Audit Trail.
Nota: Audit Trail es un producto que se factura por separado.
Referencias adicionales
Más enlaces, artículos y documentación útiles: