Para empezar a configurar un monitor, debes hacer lo siguiente:
- Definir la consulta de búsqueda: crea una consulta para contar eventos, medir métricas, agrupar por una o varias dimensiones, etc.
- Establecer las condiciones de alerta: configura los umbrales de alertas y avisos, los intervalos de evaluación y las opciones de alerta avanzadas.
- Configurar notificaciones y automatizaciones: escribe un título y un mensaje de notificación personalizados con variables. Elige cómo se envían las notificaciones a tus equipos (correo electrónico, Slack o PagerDuty). Incluye automatizaciones de flujo de trabajo o casos en la notificación de alerta.
- Define notificaciones de permisos y auditoría: Configura controles de acceso granulares y designa roles y usuarios específicos que puedan editar un monitor. Habilita las notificaciones de auditoría para alertar si se modifica un monitor.
Definir la consulta de búsqueda
Para aprender a crear una consulta de búsqueda, consulta las páginas de documentación para cada uno de los tipos de monitores. El gráfico de vista previa situado sobre los campos de búsqueda se actualiza a medida que vas modificando tu consulta.
Definir condiciones de alerta
Las condiciones de alerta varían en función del tipo de monitor. Puedes configurar los monitores para que activen una alerta si el valor de la consulta traspasa un umbral o si un determinado número de checks consecutivos falla.
- Enviar una alerta cuando las variables
average, max, min o sum de la métrica tengan un valor above, above or equal to, below o below or equal to con respecto al umbral- durante los últimos
5 minutes, 15 minutes, 1 hour, o custom para fijar un valor entre 1 minuto y 48 horas (1 mes para los monitores de métrica)
Método de agregación
La consulta devuelve una serie de puntos. Sin embargo, el monitor solo necesita un único valor para compararlo con el umbral, por lo que debe reducir los datos del intervalo de evaluación a un solo valor.
| Opción | Descripción |
|---|
| average | Se hace una media para obtener un único valor que se compara con el umbral. Esta opción añade la función avg() a la consulta de tu monitor. |
| max | Si uno de los valores de la serie supera el umbral, se genera una alerta. Esta opción añade la función max() a la consulta de tu monitor.* |
| min | Si todos los puntos del intervalo de evaluación para tu consulta superan el umbral, se envía una alerta. Esta opción añade la función min() a la consulta de tu monitor.* |
| sum | Si la suma de todos los puntos de la serie supera el umbral, se envía una alerta. Esta opción añade la función sum() a la consulta de tu monitor. |
* Estas descripciones de máximo y mínimo suponen que el monitor alerta cuando la métrica está por encima del umbral. Para los monitores que alertan cuando están por debajo del umbral, el comportamiento de máximo y mínimo se invierte. Para obtener más ejemplos, consulta la guía Agregadores de monitores.
Nota: Existen diferentes comportamientos cuando se utiliza as_count(). Consulta as_count() en Evaluaciones de monitores para obtener más detalles.
Intervalo de evaluación
Un monitor se puede evaluar utilizando intervalos continuos o fijos. Los intervalos continuos funcionan mejor para consultas que necesitan examinar datos históricos, como “¿Cuál es la suma de los datos disponibles hasta este momento concreto?”. Los intervalos fijos son mejores para responder preguntas que no necesitan este contexto, por ejemplo “¿Cuál es la media de los últimos N puntos de datos?”.
La figura a continuación ilustra la diferencia entre los intervalos continuos y los intervalos fijos.
Intervalos fijos
Una ventana temporal móvil tiene un tamaño fijo y desplaza su punto de inicio a lo largo del tiempo. Los monitores pueden retroceder hasta los últimos 5 minutes, 15 minutes, 1 hour o hasta una ventana temporal personalizada de hasta 1 mes.
Nota: Los monitores de logs tienen una ventana temporal móvil máxima de 2 days.
Intervalos continuos
Un intervalo continuo tiene un punto de inicio fijo y se repite a lo largo del tiempo. Los monitores son compatibles con tres intervalos de este tipo:
Current hour: un intervalo de una hora como máximo que comienza en el minuto que elijas. Por ejemplo, monitoriza la cantidad de llamadas que recibe un endpoint HTTP en una hora comenzando por el minuto 0.
Current day: Una ventana temporal con un máximo de 24 horas que comienza a una hora y minuto configurables de un día. Por ejemplo, monitoriza una cuota diaria de índices de logs utilizando la ventana temporal current day y dejando que comience a las 14:00 UTC.
Current month: Mira hacia atrás en el mes actual que comienza en un día configurable del mes a una hora y minuto configurables. Esta opción representa una ventana temporal del mes hasta la fecha y sólo está disponible para los monitores de métricas.
Un intervalo fijo se reinicia cuando se alcanza su tramo (span) temporal máximo. Por ejemplo, un intervalo fijo de current month se reinicia el primer día de cada mes a medianoche UTC. Alternativamente, un intervalo continuo de current hour, que comienza en el minuto 30, se reinicia cada hora. Por ejemplo, a las 6:30, 7:30 y 8:30.
Frecuencia de evaluación
La frecuencia de evaluación define con qué frecuencia Datadog lanza una consulta al monitor. En la mayoría de configuraciones, la frecuencia de evaluación es 1 minute, lo que quiere decir que cada minuto, el monitor consulta la fecha seleccionada durante el [intervalo de evaluación configurado] y compara el valor acumulado con los umbrales que tengas definidos.
Por defecto, las frecuencias de evaluación dependen del intervalo de evaluación que se utilice. Un intervalo más largo resulta en frecuencias de evaluación más bajas. La siguiente tabla ilustra cómo se controla la frecuencia de evaluación mediante intervalos más largos:
| Rangos de evaluación | Frecuencia de evaluación |
|---|
| intervalo < 24 horas | 1 minuto |
| 24 horas <= intervalo < 48 horas | 10 minutos |
| intervalo >= 48 horas | 30 minutos |
La frecuencia de evaluación también puede configurarse para que el estado de alerta del monitor se compruebe diaria, semanal o mensualmente. En esta configuración, la frecuencia de evaluación ya no depende del intervalo de evaluación, sino del horario configurado.
Para obtener más información, consulta la guía sobre cómo Personalizar las frecuencias de evaluación del monitor.
Umbrales
Usa los umbrales para definir un valor numérico a partir del cual se activará una alerta. En función de la métrica que elijas, el editor muestra la unidad utilizada (byte, kibibyte, gibibyte, etc).
Datadog dispone de dos tipos de notificaciones (alerta y advertencia). Los monitores se recuperan automáticamente en función del umbral de alerta o advertencia, pero se pueden especificar condiciones adicionales. Para obtener más información sobre los umbrales de recuperación, consulta ¿Qué son los umbrales de recuperación?. Por ejemplo, si un monitor alerta cuando la métrica está por encima de 3 y no se especifican los umbrales de recuperación, el monitor se recupera una vez que el valor de la métrica vuelve a estar por debajo de 3.
| Opción | Descripción |
|---|
| Alert threshold (obligatorio) | El valor que se utiliza para activar una notificación de alerta. |
| Warning threshold | El valor que se utiliza para activar una notificación de aviso. |
| Alert recovery threshold | Un umbral opcional para indicar una condición adicional que envía una alerta cuando el monitor se recupera. |
| Warning recovery threshold | Un umbral opcional para indicar una condición adicional que envía un aviso cuando el monitor se recupera. |
Si modificas un umbral, la vista previa del gráfico en el editor muestra un marcador indicando el punto de corte.
Nota: Cuando introduces valores decimales para los umbrales, si el valor es <1, añade un 0 antes del número. Por ejemplo, usa 0.5, no .5.
Una alerta de check hace un seguimiento de los estados consecutivos enviados por cada grupo de check y los compara con tus umbrales. Configura una alerta de check para:
Activa la alerta después de un número de fallos consecutivos: <NUMBER>
Cuando se ejecuta el check, envía un estado de OK, WARN o CRITICAL. Elige cuántas veces tiene que darse un estado WARN y CRITICAL para que se envíe una notificación. Por ejemplo, pongamos que se produce un error puntual en tu proceso y falla la conexión. Si tienes este valor establecido como > 1, el fallo se ignorará, pero si el error se da más veces, se activará el envío de una notificación.
Resolver la alerta después de una cantidad consecutiva determinada de intentos sin errores: <NUMBER>
Configura cuántas veces tiene que darse el estado OK para que se resuelva la alerta.
Consulta la documentación sobre los monitores de check de proceso, check de integración y check personalizado para obtener más información sobre cómo configurar alertas de checks.
Condiciones de alerta avanzadas
Sin datos
Las notificaciones en caso de que falten datos son útiles si se espera que una métrica siempre envíe datos en condiciones normales. Por ejemplo, si un host con el Agent instalado debe estar siempre disponible, la métrica system.cpu.idle no debería dejar de enviar datos.
En este caso, deberías activar el envío de notificaciones en caso de que dejen de recibirse esos datos. Las siguientes secciones te explican cómo proceder en cada caso particular.
Nota: El monitor debe poder evaluar los datos antes de enviar una alerta sobre la falta de datos. Por ejemplo, si creas un monitor para service:abc y los datos de ese service no se están enviando, el monitor no enviará las alertas.
Si los datos faltan durante N minutos, selecciona una de estas opciones del menú desplegable:
Evaluate as zero / Show last known statusShow NO DATAShow NO DATA and notifyShow OK.
El comportamiento seleccionado se aplicará cuando la consulta de un monitor no devuelva ningún dato. A diferencia de la opción Do not notify, el intervalo de ausencia de datos no se puede configurar.
| Opción | Estado y notificaciones del monitor |
|---|
Evaluate as zero | Un resultado vacío se sustituye por cero y se compara con los umbrales de alerta o aviso. Por ejemplo, si el umbral de alerta se define como > 10, un cero no activará esa condición y el estado del monitor se configura como OK. |
Show last known status | Se configura el último estado conocido de un grupo o un monitor. |
Show NO DATA | El estado del monitor se configura como NO DATA. |
Show NO DATA and notify | El estado del monitor se configura como NO DATA y se envía una notificación. |
Show OK | El monitor se resuelve y el estado se define como OK. |
Las opciones Evaluate as zero y Show last known status se muestran en función del tipo de consulta:
- Evaluate as zero: esta opción está disponible para monitores que utilizan consultas
Count sin la función default_zero(). - Show last known status: esta opción está disponible para monitores que usan consultas distintas de
Count, por ejemplo Gauge, Rate y Distribution, así como consultas Count con default_zero().
Resolución automática
[Never], After 1 hour, After 2 hours y así sucesivamente. resuelve automáticamente este evento a partir de un estado activado.
La resolución automática se aplica cuando se dejan de enviar datos. Los monitores no se resuelven automáticamente si tienen un estado ALERT o WARN y los datos siguen enviándose. En este caso, puedes utilizar la función de renotificación para que el equipo sepa que hay algún problema sin resolver.
En el caso de las métricas que envían datos de forma periódica, tiene sentido que las alertas se resuelvan automáticamente una vez transcurrido un tiempo determinado. Por ejemplo, si tienes una métrica de contador que solo envía datos cuando se registra un log de un error, la alerta no se resuelve nunca porque la métrica nunca envía 0 errores. En este caso, puedes configurarla para que se resuelva después de un tiempo determinado de inactividad en la métrica. Nota: Si un monitor se resuelve de forma automática y el valor de la consulta no está dentro del umbral de recuperación en la siguiente evaluación, activará una nueva alerta.
En la mayoría de los casos esta configuración no es útil porque sólo se desea que una alerta se resuelva después de que se haya solucionado realmente. Así que, en general, tiene sentido dejarlo como [Never] para que las alertas sólo se resuelvan cuando métrica esté por encima o por debajo del umbral establecido.
Duración de retención de un grupo
Puede eliminar el grupo del estado Monitor después de N horas de falta de datos. El plazo puede ser como mínimo de 1 hora y como máximo de 72 horas. Para la alerta múltiple monitors, seleccione Eliminar el grupo no informante después de N (length of time).
Igual que la opción de resolución automática, la opción de retención del grupo se aplica cuando ya no se envían datos. Controla cuánto tiempo conserva el grupo el estado del monitor una vez que los datos dejan de enviarse. Por omisión, un grupo mantiene el estado durante 24 horas y luego se excluye. La hora de inicio de la retención del grupo y la opción de resolución automática son idénticas siempre y cuando la consulta del monitor no devuelva ningún dato.
El uso de la duración de retención de un grupo puede resultar útil cuando:
- Quieres excluir un grupo justo cuando deje de enviar datos o poco después.
- Quieres que el grupo conserve el estado del monitor todo el tiempo que tardes en solucionar los problemas.
Nota: Para configurar el tiempo de retención de un grupo, debes utilizar un monitor de alertas múltiples compatible con la opción On missing data, por ejemplo, monitores de análisis de trazas (traces) APM, logs de auditoría, pipelines de CI, seguimiento de errores, logs y RUM.
Retraso para los nuevos grupos
Retrasa el comienzo de la evaluación de los nuevos grupos durante N segundos.
Este tiempo corresponde con la duración (en segundos) después de la que se debe empezar a enviar las alertas. Permite que los nuevos grupos se carguen y se inicien las aplicaciones. Su valor debe ser un número entero positivo.
Por ejemplo, si utilizas una arquitectura contenorizada, el retraso para los nuevos grupos evita que los grupos del monitor que pertenezcan a contenedores se activen debido a un alto uso de los recursos o a una alta latencia cuando se crea un nuevo contenedor. El retraso se aplica a todos los grupos nuevos (con una antigüedad inferior a 24 horas) y de forma predeterminada es de 60 segundos.
La opción está disponible en la modalidad de alerta múltiple.
Retraso de la evaluación
Datadog recomienda un retraso de 15 minutos en el caso de métricas en la nube que reponen proveedores de servicio. Además, si utilizas una fórmula de división, un retraso de 60 segundos resulta útil para garantizar que el monitor evalúa valores completos. Consulta los tiempos de retraso estimados en la página
Tiempo de respuesta de las métricas en la nube.
Retraso de la evaluación N segundos.
El tiempo (en segundos) que se retrasa la evaluación. Debe ser un número entero positivo. De esta forma, si el retraso se configura en 900 segundos (15 minutos), la evaluación se realiza durante los últimos 5 minutes. Si se configura la evaluación de los datos para las 7:00, el monitor la hará de 6:40 a 6:45. El retraso máximo que puedes configurar es de 86 400 segundos (24 horas).
Configurar notificaciones y automatizaciones
Configura tus mensajes de notificación para que incluyan la información que más te interesa. Especifica a qué equipos se van a enviar estas alertas así como para qué atributos se deben enviar.
Mensaje
Usa esta sección para configurar las notificaciones que recibe tu equipo y cómo enviarlas:
Para obtener más información sobre las opciones de configuración para los mensajes de notificación, consulta Notificaciones de alerta.
- Utiliza el menú desplegable Tags (etiquetas) para asociar tags (etiquetas) a tu monitor.
- Utilzae el menú desplegable Equipos para asociar equipos a tu monitor.
- Selecciona una Priority (Prioridad).
Establecer la agregación de alertas
Las alertas se agrupan automáticamente en función de la agregación seleccionada para la consulta (por ejemplo, avg by servicio). Si la consulta no tiene ningún agrupamiento, aparece de modo predeterminado Simple Alert. Si la consulta está agrupada por alguna dimensión, el agrupamiento cambia a Multi Alert.
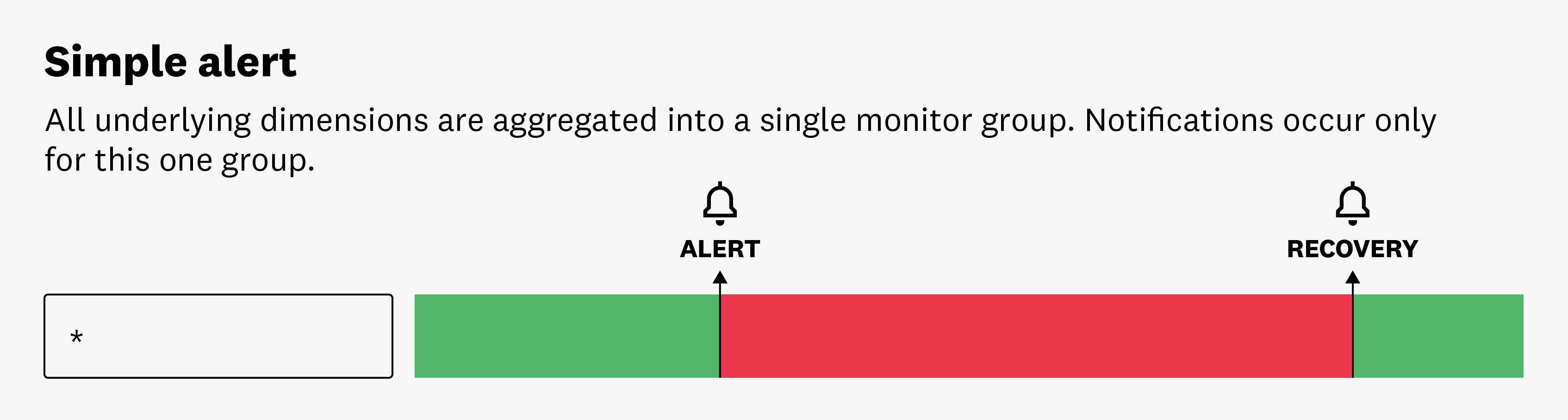
Alerta única
Simple Alert activa una notificación agregando todas las fuentes de información. Recibirás una alerta cuando el valor agregado cumpla las condiciones establecidas. Por ejemplo, puedes configurar un monitor para que te notifique si el uso medio de la CPU de todos los servidores supera un determinado umbral. Si se alcanza ese umbral, recibirás una única notificación, independientemente del número de servidores individuales que hayan alcanzado el umbral. Esto puede ser útil para la monitorización de tendencias o comportamientos generales del sistema.
Alerta múltiple
Un monitor Multi Alert activa notificaciones individuales para cada entidad de un monitor que alcance el umbral de alerta.
Por ejemplo, al configurar un monitor para que te notifique si la latencia P99, agregada por servicio, supera un determinado umbral, recibirías una alerta independiente por cada servicio individual cuya latencia P99 superase el umbral de alerta. Esto puede ser útil para identificar y tratar casos específicos de problemas del sistema o de la aplicación. Te permite rastrear problemas en un nivel más detallado.
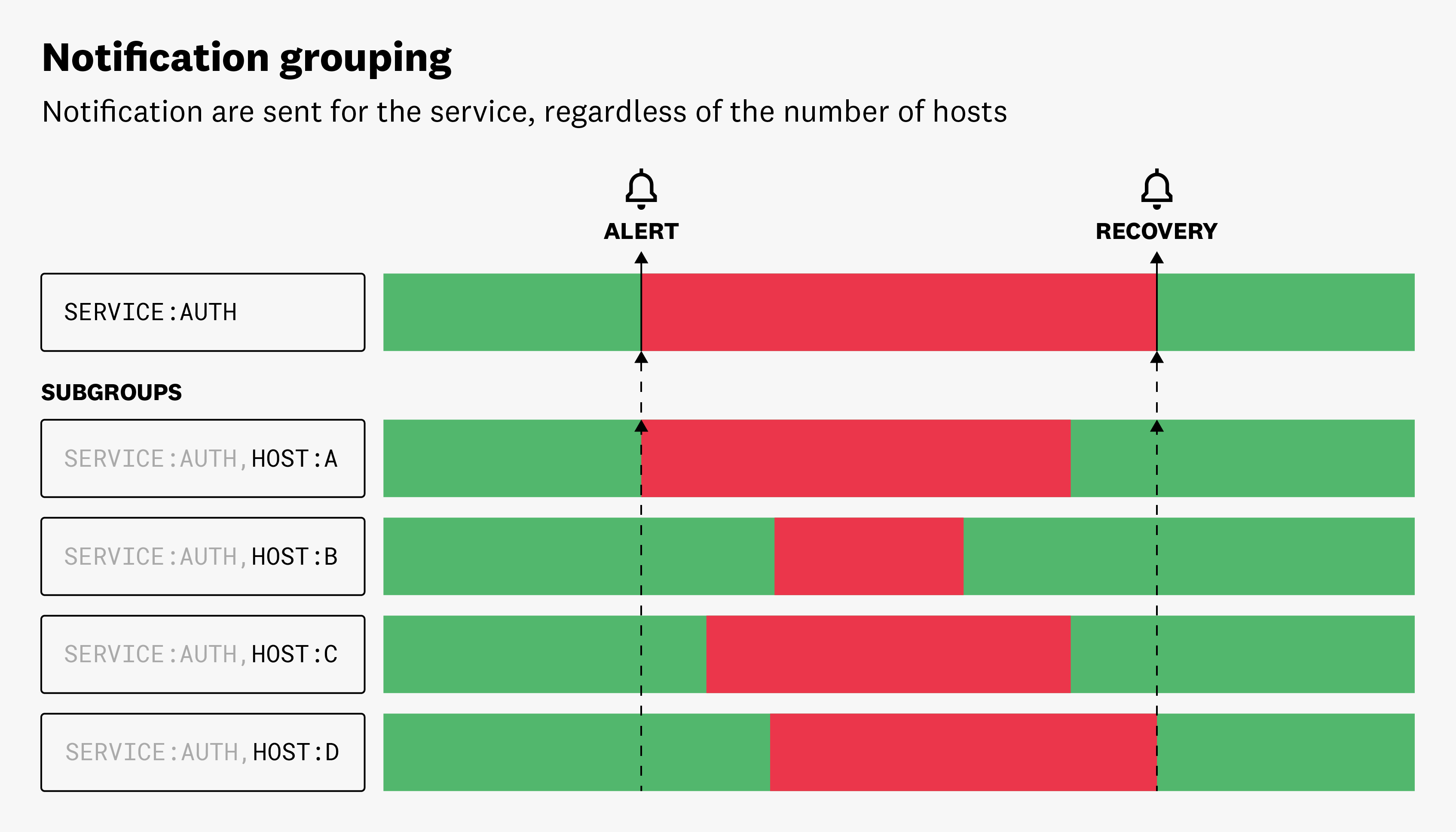
Agrupamiento de notificaciones
Cuando Monitorización de un gran grupo de entidades, las alertas múltiples pueden dar lugar a ruidos monitors. Para mitigar esto, personalice qué dimensiones activan las alertas. Esto reduce el ruido y le permite centrarse en las alertas que más importan. Por ejemplo, usted está Monitorización del uso medio de CPU de todos sus hosts. Si agrupa su consulta por service y host pero sólo desea que se envíen alertas una vez por cada atributo service que alcance el umbral, elimine el atributo host de sus opciones de multialerta y reduzca el número de notificaciones que se envían.
Al agregar notificaciones en el modo Multi Alert, las dimensiones que no se agregan pasan a ser Sub Groups en la interfaz de usuario.
Nota: Si su métrica sólo está informando por host sin service etiquetar , no es detectado por el Monitor. métricas con ambos host y service etiquetas (tags) son detectados por el Monitor.
Si configuras tags (etiquetas) o dimensiones en tu consulta, estos valores están disponibles para cada grupo evaluado en la alerta múltiple para completar dinámicamente notificaciones con un contexto útil. Consulta Variables de atributos y tags (etiquetas) para aprender a hacer referencia a los valores de las tags (etiquetas) en el mensaje de notificación.
| Agrupar por | Modalidad de alerta única | Modalidad de alerta múltiple |
|---|
| (todo) | Un único grupo activa una única notificación | N/A |
| 1 or more dimensions | Se envía una notificación si uno o más grupos cumplen las condiciones de la alerta | Se envía una notificación por cada grupo que cumpla las condiciones de alerta |
Permisos
Todos los usuarios pueden ver todos los monitores, independientemente del equipo o rol al que estén asociados. De modo predeterminado, sólo los usuarios asociados a roles con el Permiso de escritura de monitores pueden editar monitores. Los Roles de administrador y estándar de Datadog tienen el permiso de escritura de monitores de modo predeterminado. Si tu organización utiliza Roles personalizados, otros roles personalizados pueden tener el permiso de escritura de monitores. Para obtener más información sobre la configuración de RBAC para monitores y la migración de monitores de la configuración bloqueada al uso de restricciones de roles, consulta la guía sobre Cómo configurar RBAC para monitores.
Puedes restringir aún más tu monitor especificando un lista de equipos, roles o usuarios con permiso para editarlo. De modo predeterminado, el creador del monitor tiene derechos de edición sobre el monitor. Editar incluye cualquier actualización de la configuración del monitor, eliminar el monitor y silenciar el monitor durante cualquier periodo de tiempo.
Nota: Las limitaciones se aplican tanto en la interfaz de usuario como en la API.
Controles de acceso detallados
Utiliza controles de acceso granular para limitar los equipos, funciones o usuarios que pueden editar un monitor:
- Al editar o configurar un monitor, busca la sección Definir permisos y notificaciones de auditoría.
- Haz clic en Edit Access (Editar acceso).
- Haz clic en Restrict Access (Restringir el acceso).
- El cuadro de diálogo se actualiza para mostrar que los miembros de tu organización tienen por omisión el permiso de acceso Viewer (Visualización).
- Utiliza el menú desplegable para seleccionar uno o varios equipos, roles o usuarios que puedan editar el monitor.
- Haz clic en Add (Añadir).
- El cuadro de diálogo se actualiza para indicar que el rol que has seleccionado tiene el permiso Editor (Edición).
- Haz clic en Done (Listo).
Nota: Para mantener tu acceso de edición al monitor, el sistema requiere que incluyas al menos un rol o equipo del que seas miembro antes de guardar.
Para restablecer el acceso general a un monitor con acceso restringido, sigue los steps (UI) / pasos que se indican a continuación:
- Mientras visualiza un monitor, haz clic en el menú desplegable Más.
- Selecciona Permissions (Permisos).
- Haz clic en Restore Full Access (Restablecer acceso completo).
- Haz clic en Save (Guardar).
Referencias adicionales
Más enlaces, artículos y documentación útiles: