概要
モニターの構成を開始するには、以下を完了します。
- Define the search query: Construct a query to count events, measure metrics, group by one or several dimensions, and more.
- **アラート条件を設定します。**アラートと警告のしきい値、評価タイムフレームを定義し、高度なアラートオプションを構成します。
- Configure notifications and automations: Write a custom notification title and message with variables. Choose how notifications are sent to your teams (email, Slack, or PagerDuty). Include workflow automations or cases in the alert notification.
- Define permissions and audit notifications: Configure granular access controls and designate specific roles and users who can edit a monitor. Enable audit notifications to alert if a monitor is modified.
検索クエリを定義する
検索クエリの作成方法については、個々のモニタータイプページを参照してください。検索クエリを定義すると、検索フィールドの上のプレビューグラフが更新されます。
アラートの条件を設定する
アラート条件は、モニタータイプによって異なります。クエリ値がしきい値を超えた場合、または特定の数の連続したチェックが失敗した場合にトリガーするようにモニターを構成します。
- メトリクスの
average、max、min、sum が - しきい値に対して
above、above or equal to、below、below or equal to になったらトリガーします - 過去
5 minutes、15 minutes、1 hour、または custom に 1 分~48 時間 (メトリクスモニターに対して 1 か月) の値を設定します
集計の方法
クエリは一連のポイントを返しますが、しきい値と比較するには単一の値が必要です。モニターは、評価ウィンドウのデータを単一の値に減らす必要があります。
| オプション | 説明 |
|---|
| 平均 | 系列の平均値が算出され、単一の値が生成されます。この値がしきい値と比較されます。このオプションは、モニタークエリに avg() 関数を追加します。 |
| 最大 | 生成された系列で、どれか一つの値がしきい値を超えたら、アラートがトリガーされます。これは、max() 関数をモニタークエリに追加します。* |
| 最小 | クエリの評価ウィンドウ内のすべてのポイントがしきい値を超えたら、アラートがトリガーされます。これは、min() 関数をモニタークエリに追加します。* |
| 合計 | 系列内のすべてのポイントの合計値がしきい値から外れている場合に、アラートがトリガーされます。このオプションは、モニタークエリに sum() 関数を追加します。 |
* These descriptions of max and min assume that the monitor alerts when the metric goes above the threshold. For monitors that alert when below the threshold, the max and min behavior is reversed. For more examples, see the Monitor aggregators guide.
Note: There are different behaviors when utilizing as_count(). See as_count() in Monitor Evaluations for details.
評価ウィンドウ
モニターは、累積タイムウィンドウまたはローリングタイムウィンドウを使用して評価することができます。累積タイムウィンドウは、「この時点までのすべてのデータの合計は?」のような歴史的な文脈を必要とする質問に最も適しています。ローリングタイムウィンドウは、「直近の N データポイントの平均は?」のような、このコンテキストを必要としない質問に答えるのに最適な方法です。
下図は、累積タイムウィンドウとローリングタイムウィンドウの違いを示しています。
ローリングタイムウィンドウ
ローリングタイムウィンドウは、サイズが固定で、時間の経過とともに開始点が移動します。モニターは、5 minutes、15 minutes、1 hour またはカスタムで指定したタイムウィンドウを振り返ることができます。
累積タイムウィンドウ
累積タイムウィンドウは、開始点が固定され、時間の経過とともに拡大します。モニターは 3 つの異なる累積タイムウィンドウをサポートしています。
Current hour: 構成可能な分単位で開始する最大1時間のタイムウィンドウです。例えば、HTTP エンドポイントが 0 分から 1 時間の間に受けたコールの量を監視します。
Current day: A time window with a maximum of 24 hours starting at a configurable hour and minute of a day. For example, monitor a daily log index quota by using the current day time window and letting it start at 2:00pm UTC.
Current month: Looks back at the current month starting on a configurable day of the month at a configurable hour and minute. This option represents a month-to-date time window and is only available for metric monitors.
累積タイムウィンドウは、その最大タイムスパンに達した後リセットされます。例えば、current month を見る累積タイムウィンドウは、毎月 1 日の午前 0 時 (UTC) にリセットされます。あるいは、current hour の累積タイムウィンドウは、30 分から始まり、1 時間ごとにリセットされます。例えば、午前 6 時 30 分、午前 7 時 30 分、午前 8 時 30 分です。
評価頻度
評価頻度は、Datadog がモニタークエリを実行する頻度を定義します。ほとんどの構成では、評価頻度は 1 minute で、これは 1 分ごとにモニターが選択したデータを選択した評価ウィンドウにクエリして、定義したしきい値と集計値を比較することを意味します。
デフォルトで、評価頻度は使用されている評価ウィンドウに依存します。ウィンドウを長くすると、評価頻度が低くなります。以下の表は、タイムウィンドウを大きくすることで評価頻度がどのように制御されるかを示しています。
| 評価ウィンドウの範囲 | 評価頻度 |
|---|
| ウィンドウ < 24 時間 | 1 分 |
| 24 時間 <= ウィンドウ < 48 時間 | 10 分 |
| ウィンドウ >= 48 時間 | 30 分 |
評価頻度は、モニターのアラート条件を毎日、毎週、毎月チェックするように構成することもできます。この構成では、評価頻度はもはや評価ウィンドウに依存せず、構成されたスケジュールに依存します。
詳しくは、モニター評価頻度のカスタマイズ方法のガイドをご覧ください。
しきい値
しきい値には、アラートをトリガーする数値を設定します。メトリクスに何を選ぶかによって、エディターに表示される単位 (byte、kibibyte、gibibyte など) が変わります。
Datadog has two types of notifications (alert and warning). Monitors recover automatically based on the alert or warning threshold but additional conditions can be specified. For additional information on recovery thresholds, see What are recovery thresholds?. For example, if a monitor alerts when the metric is above 3 and recovery thresholds are not specified, the monitor recovers once the metric value goes back below 3.
| オプション | 説明 |
|---|
| アラートしきい値 (必須) | アラートの通知のトリガーに使用される値 |
| 警告しきい値 | 警告の通知のトリガーに使用される値 |
| アラート回復しきい値 | アラートのリカバリに対する追加条件を示すしきい値 (任意) |
| 警告回復しきい値 | 警告のリカバリに対する追加条件を示すしきい値 (任意) |
しきい値を変更すると、エディター内でプレビューグラフにカットオフポイントを示すマーカーが表示されます。
メモ: しきい値を小数で入力する際、値が <1 の場合は先頭に 0 を付けます。たとえば、.5 ではなく 0.5 としてください。
チェックアラートは、各チェックグループにつき、送信されたステータスを連続的にトラックし、しきい値と比較します。チェックアラートを次のように設定します。
何回連続して失敗したらアラートをトリガーするか、回数 <数値> を選択します。
各チェックは OK、WARN、CRITICAL のいずれか 1 つのステータスを送信します。WARN と CRITICAL ステータスが連続して何回送信されたら通知をトリガーするか選択します。たとえば、プロセスで接続に失敗する異常が 1 回発生したとします。値を > 1 に設定した場合、この異常は無視されますが、2 回以上連続で失敗した場合は通知をトリガーします。
何回連続して成功したらアラートを解決するか、回数 <数値> を選択します。
何回連続して OK ステータスが送信されたらアラートを解決するか、回数を選択します。
チェックアラートの構成の詳細については、プロセスチェック、インテグレーションチェック、カスタムチェックモニターのドキュメントを参照してください。
高度なアラート条件
No Data
正常な状態で、メトリクスが常にデータを報告するようにするには、「データなし」通知を利用すると便利です。たとえば、Agent を使用しているホストが継続的に稼働している必要がある場合、system.cpu.idle メトリクスがデータを常に報告することが期待されます。
この場合、データ欠落の通知を有効にする必要があります。以下のセクションでは、各オプションでこれを実現する方法を説明します。
注: 欠落したデータに対してアラートを出す前に、モニターはデータを評価できなければなりません。例えば、service:abc のモニターを作成し、その service からのデータが報告されていない場合、モニターはアラートを送信しません。
If you are monitoring a metric over an auto-scaling group of hosts that stops and starts automatically, notifying for no data produces a lot of notifications. In this case, you should not enable notifications for missing data. This option does not work unless it is enabled at a time when data has been reporting for a long period.
| オプション | 説明 | 注 |
|---|
| Do not notify if data is missing | No notification is sent if data is missing | Simple Alert: the monitor skips evaluations and stays green until data returns that would change the status from OK
Multi Alert: if a group does not report data, the monitor skips evaluations and eventually drops the group. During this period, the bar in the results page stays green. When there is data and groups start reporting again, the green bar shows an OK status and backfills to make it look like there was no interruption. |
| Notify if data is missing for more than N minutes. | You are notified if data is missing. The notification occurs when no data was received during the configured time window. | Datadog recommends that you set the missing data window to at least two times the evaluation period. |
N 分のデータがない場合、ドロップダウンメニューからオプションを選択します。
Evaluate as zero / Show last known statusShow NO DATAShow NO DATA and notifyShow OK
選択された動作は、モニターのクエリがデータを返さなかったときに適用されます。Do not notifyオプションとは異なり、データ欠落ウィンドウは構成できません。
| オプション | モニターステータスと通知 |
|---|
Evaluate as zero | 空の結果はゼロに置き換えられ、アラート/警告のしきい値と比較されます。例えば、警告しきい値が > 10 に設定されている場合、ゼロはその状態をトリガーせず、モニターのステータスは OK に設定されます。 |
Show last known status | グループまたはモニターの最後の既知のステータスが設定されます。 |
Show NO DATA | モニターステータスが NO DATA に設定されます。 |
Show NO DATA and notify | モニターステータスが NO DATA に設定され、通知が送信されます。 |
Show OK | モニターは解決され、ステータスは OK に設定されます。 |
Evaluate as zero と Show last known status のオプションが、クエリの種類に応じて表示されます。
- Evaluate as zero: このオプションは、
default_zero() 関数がない Count クエリを使用するモニターに使用できます。 - Show last known status: このオプションは
Count 以外のクエリタイプ、例えば Gauge、Rate、Distribution を使用しているモニター、および default_zero() を持つ Count クエリで利用できます。
Auto resolve
[Never], After 1 hour, After 2 hours and so on. automatically resolve this event from a triggered state.
自動解決は、データが送信されなくなったときに機能します。データがまだ報告されている場合、モニターは、ALERT または WARN 状態から自動解決されません。データがまだ送信されている場合は、再通知機能を利用して、問題が解決されていないことをチームに知らせることができます。
メトリクスが定期的に報告を行う場合に、トリガーされたアラートを一定の期間の後に自動で解決したいことがあります。たとえば、エラーのログだけを報告するカウンターがある場合、エラーの数が 0 であれば報告が行われないため、アラートがいつまでも解決しません。このような場合、メトリクスからの報告がないまま一定の期間が経過したらアラートを解決するように設定できます。注: モニターがアラートを自動で解決し、次回の評価でクエリーの値がリカバリのしきい値を満たしていない場合、モニターはもう一度アラートをトリガーします。
In most cases this setting is not useful because you only want an alert to resolve after it is actually fixed. So, in general, it makes sense to leave this as [Never] so alerts only resolve when the metric is above or below the set threshold.
グループ保持時間
You can drop the group from the monitor status after N hours of missing data. The length of time can be at minimum 1 hour, and at maximum 72 hours. For multi alert monitors, select Remove the non-reporting group after N (length of time).
自動解決オプションと同様に、グループの保持は、データが送信されなくなったときに機能します。このオプションは、データが報告されなくなった後、グループがモニターのステータスに保持される時間を制御します。デフォルトでは、グループはドロップされる前に 24 時間ステータスを保持します。グループ保持の開始時間と自動解決オプションは、モニタークエリがデータを返さないとすぐに 同一 になります。
グループ保持時間を定義するユースケースとしては、以下のようなものがあります。
- データが報告されなくなった直後に、グループをドロップしたい場合
- トラブルシューティングのために通常かかる時間と同じだけ、グループのステータスを維持したい場合
注: グループ保持時間オプションは、On missing data オプションをサポートするマルチアラートモニターを必要とします。これらのモニタータイプは、APM トレース分析、監査ログ、CI パイプライン、エラー追跡、イベント、ログ、および RUM モニターです。
新しいグループ遅延
新しいグループの評価開始を N 秒遅らせます。
アラートを開始する前に待機する時間 (秒単位)。新しく作成されたグループが起動し、アプリケーションが完全に起動できるようにします。これは負でない整数である必要があります。
たとえば、コンテナ化されたアーキテクチャを使用している場合、グループ遅延を設定すると、新しいコンテナが作成されたときのリソース使用量や待ち時間が長いために、コンテナを対象とするモニターグループがトリガーされなくなります。遅延はすべての新しいグループ (過去 24 時間に表示されていない) に適用され、デフォルトは 60 秒です。
このオプションは、マルチアラートモードで使用できます。
Evaluation Delay
Datadog では、サービスプロバイダーによってバックフィルされるクラウドメトリクスに対して 15 分の遅延を推奨しています。さらに、除算式を使用する場合、モニターが完全な値で評価されるようにするために、60 秒の遅延が有効です。遅延時間の目安については、
クラウドメトリクスの遅延ページを参照してください。
評価を N 秒遅らせます。
評価を遅らせる時間 (秒単位)。負以外の整数を指定してください。たとえば、遅延を 900 秒 (15 分) に、モニターが評価を行う期間を直前の 5 minutes に、時刻を 7:00 に設定すると、モニターは 6:40 から 6:45 までのデータを評価します。構成可能な評価遅延の最大値は 86400 秒 (24 時間) です。
通知と自動化の構成
通知メッセージを構成して、最も関心のある情報を含めることができます。アラートを送信するチームと、アラートをトリガーする属性を指定します。
メッセージ
このセクションを使用して、チームへの通知を構成し、これらのアラートを送信する方法を構成します。
通知メッセージの構成オプションの詳細については、アラート通知を参照してください。
メタデータを追加する
- Use the Tags dropdown to associate tags with your monitor.
- Use the Teams dropdown to associate teams with your monitor.
- Priority を選択します。
Set alert aggregation
アラートは、クエリを定義する際に group by の手順で選択したグループに応じて自動的にグループ化されます。クエリにグループ化がない場合、デフォルトで Simple Alert (シンプルアラート) でグループ化されます。クエリがディメンションでグループ化されている場合は、Multi Alert (マルチアラート) でグループ化されます。
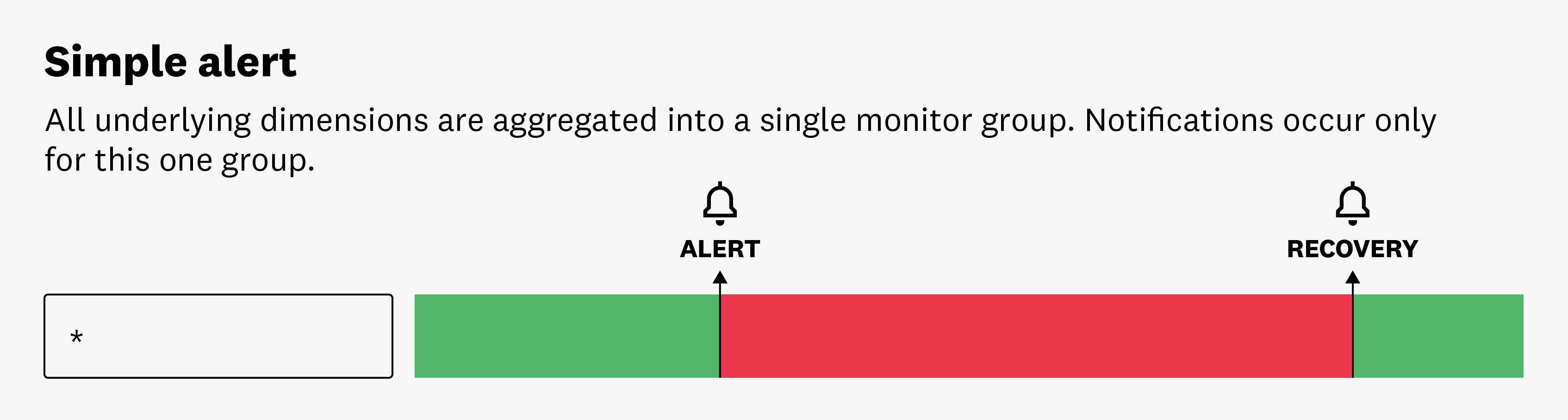
シンプルアラート
Simple Alert モードは、すべてのレポートソースを集計して通知をトリガーします。集計された値が設定された条件を満たすと、1 つのアラートを受け取ります。例えば、全サーバーの平均 CPU 使用率があるしきい値を超えた場合に通知するようにモニターを設定するとします。そのしきい値を満たした場合、しきい値を満たした個々のサーバーの数に関係なく、1 つの通知を受け取ります。これは、システムの大まかな傾向や動作を監視するのに便利です。
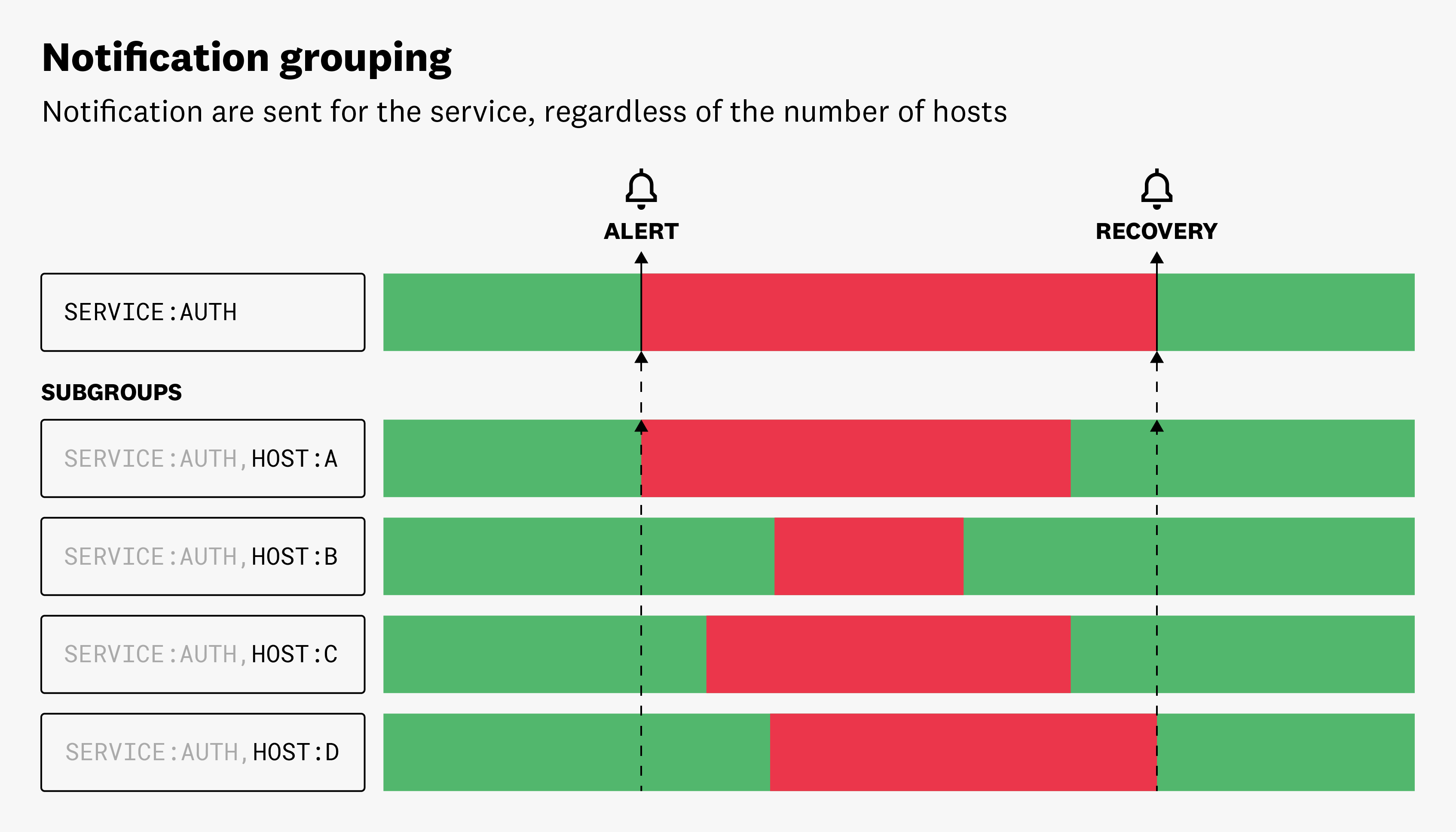
マルチアラート
Multi Alert モニターは、アラートしきい値を満たしたモニター内の各エンティティに対して個別の通知をトリガーします。
例えば、サービスごとに集計された P99 レイテンシーがあるしきい値を超えた場合に通知するようにモニターを設定する場合、P99 レイテンシーがアラートしきい値を超えた個々のサービスごとに別々のアラートを受け取ることになります。これは、システムまたはアプリケーションの問題の特定のインスタンスを特定し、対処するのに便利です。より詳細なレベルで問題を追跡することができます。
エンティティの大規模なグループを監視する場合、マルチアラートではノイズの多いモニターになる可能性があります。これを軽減するには、どのディメンションがアラートをトリガーするかをカスタマイズします。これにより、ノイズを減らし、最も重要なアラートに集中することができます。例えば、全ホストの平均 CPU 使用率を監視しているとします。クエリを service と host でグループ化したが、しきい値を満たした各 service 属性に対してアラートを一度送信したいだけの場合は、マルチアラートオプションから host 属性を削除すれば、送信される通知の数を減らすことができます。
Multi Alert モードで通知を集計する場合、集計されないディメンションは UI で Sub Groups になります。
注: service タグがなく、host タグだけが報告されているメトリクスは、モニターによって検出されません。host と service の両方のタグを持つメトリクスは、モニターによって検出されます。
If you configure tags or dimensions in your query, these values are available for every group evaluated in the multi alert to dynamically fill in notifications with useful context. See Attribute and tag variables to learn how to reference tag values in the notification message.
| グループ化 | シンプルアラートモード | マルチアラートモード |
|---|
| (すべて) | 1 つの通知をトリガーする 1 つの単一グループ | N/A |
| 1 つ以上のディメンション | 1 つ以上のグループがアラート条件を満たす場合の 1 つの通知 | アラート条件を満たすグループごとに 1 つの通知 |
権限
All users can view all monitors, regardless of the team or role they are associated with. By default, only users attached to roles with the Monitors Write permission can edit monitors. Datadog Admin Role and Datadog Standard Role have the Monitors Write permission by default. If your organization uses Custom Roles, other custom roles may have the Monitors Write permission. For more information on setting up RBAC for Monitors and migrating monitors from the locked setting to using role restrictions, see the guide on How to set up RBAC for Monitors.
You can further restrict your monitor by specifying a list of teams, roles, or users allowed to edit it. The monitor’s creator has edit rights on the monitor by default. Editing includes any updates to the monitor configuration, deleting the monitor, and muting the monitor for any amount of time.
注: 制限は UI と API の両方に適用されます。
きめ細かなアクセス制御
Use granular access controls to limit the teams, roles, or users that can edit a monitor:
- While editing or configuring a monitor, find the Define permissions and audit notifications section.
- Click Edit Access.
- Restrict Access をクリックします。
- ダイアログボックスが更新され、組織のメンバーはデフォルトで Viewer アクセス権を持っていることが表示されます。
- Use the dropdown to select one or more teams, roles, or users that may edit the monitor.
- Add をクリックします。
- ダイアログボックスが更新され、選択したロールに Editor 権限があることが表示されます。
- Done をクリックします。
Note: To maintain your edit access to the monitor, the system requires you to include at least one role or team that you are a member of before saving.
To restore general access to a monitor with restricted access, follow the steps below:
- While viewing a monitor, click the More dropdown menu.
- Permissions を選択します。
- Restore Full Access をクリックします。
- Save をクリックします。
参考資料