概要
Datadog ログ管理は、ログの収集、処理、アーカイブ、探索、監視を行うため、システムの問題を可視化することができます。しかし、ログから適切なレベルの可視性を得ることは難しく、また、ログのスループットが大きく変動し、予期せぬリソースの使用を引き起こす可能性があります。
Therefore, this guide walks you through various Log Management best practices and account configurations that provide you flexibility in governance, usage attribution, and budget control. More specifically, how to:
また、このガイドでは、ログの使用量を監視する方法について、以下のように説明します。
If you want to transform your logs or redact sensitive data in your logs before they leave your environment, see how to aggregate, process, and transform your log data with Observability Pipelines.
ログアカウント構成
ログセグメンテーションのための複数のインデックスを設定する
異なる保持期間や 1 日の割り当て、使用量の監視、請求のためにログをセグメント化したい場合は、複数のインデックスを設定します。
例えば、7 日間だけ保持する必要があるログと、30 日間保持する必要があるログがある場合、複数のインデックスを使用して、2 つの保持期間ごとにログを分離することができます。
複数のインデックスを設定するには
- ログインデックスに移動します。
- New Index または Add a new index をクリックします。
- インデックスの名前を入力します。
- このインデックスに入れたいログにフィルターをかけるための検索クエリを入力します。
- 1 日にインデックス内に保存されるログの数を制限するために、1 日の割り当てを設定します。
- これらのログを保持する期間を設定します。
- Save をクリックします。
インデックスに 1 日の割り当てを設定すると、新しいログソースが追加されたとき、または開発者が意図せずにログレベルをデバッグモードに変更したときに、請求の超過を防止するのに役立ちます。過去 24 時間以内に 1 日の割り当てのパーセンテージに達したときにアラートを発するようにモニターを設定する方法については、[インデックスが 1 日の割り当てに達した場合のアラート(#alert-on-indexes-reaching-their-daily-quota)を参照してください。
Set up storage for long-term retention
If you want to retain logs for an extended time while maintaining querying speeds similar to Standard Indexing, configure Flex Logs. This tier is best suited for logs that require longer retention and occasionally need to be queried urgently. Flex Logs decouples storage from compute costs so you can cost effectively retain more logs for longer without sacrificing visibility. Logs that need to be frequently queried should be stored in standard indexes.
長期保存のための複数のアーカイブを設定する
If you want to store your logs for longer periods of time, set up Log Archives to send your logs to a storage-optimized system, such as Amazon S3, Azure Storage, or Google Cloud Storage. When you want to use Datadog to analyze those logs, use Log RehydrationTM to capture those logs back in Datadog. With multiple archives, you can both segment logs for compliance reasons and keep rehydration costs under control.
高価なリハイドレートを管理するために最大スキャンサイズを設定する
一度にリハイドレートできるログの容量の上限を設定します。アーカイブの設定時に、リハイドレートのためにスキャンできるログデータの最大容量を定義することができます。詳しくは、最大スキャンサイズを定義するを参照してください。
カスタムロールの RBAC を設定する
Datadog のデフォルトロールは 3 つあります。Admin、Standard、および Read-only です。また、独自の権限セットを持つカスタムロールを作成することも可能です。例えば、意図しないコスト上昇を避けるために、インデックス保持ポリシーの変更をユーザーに制限するロールを作成することができます。同様に、ログのパース構成を変更できるユーザーを制限して、明確に定義されたログの構造や形式が不要に変更されるのを避けることができます。
権限を持つカスタムロールを設定するには
- Datadog に Admin としてログインします。
- Organization Settings > Roles に移動します。
- カスタムロールを有効にするには、左上の歯車をクリックし、Enable をクリックします。
- 有効にしたら、New Role をクリックします。
- 新しいロールの名前を入力します。
- ロールの権限を選択します。これにより、ログのリハイドレートやログベースのメトリクス作成など、特定のアクションへのアクセスを制限することができます。詳細については、ログ管理の権限を参照してください。
- Save をクリックします。
See How to Set Up RBAC for Logs for a step-by-step guide on how to set up and assign a role with specific permissions for an example use case.
ログの使用量を監視する
以下を設定することで、ログの使用量を監視することができます。
予期せぬログトラフィックの急増に対するアラート
ログ使用量メトリクス
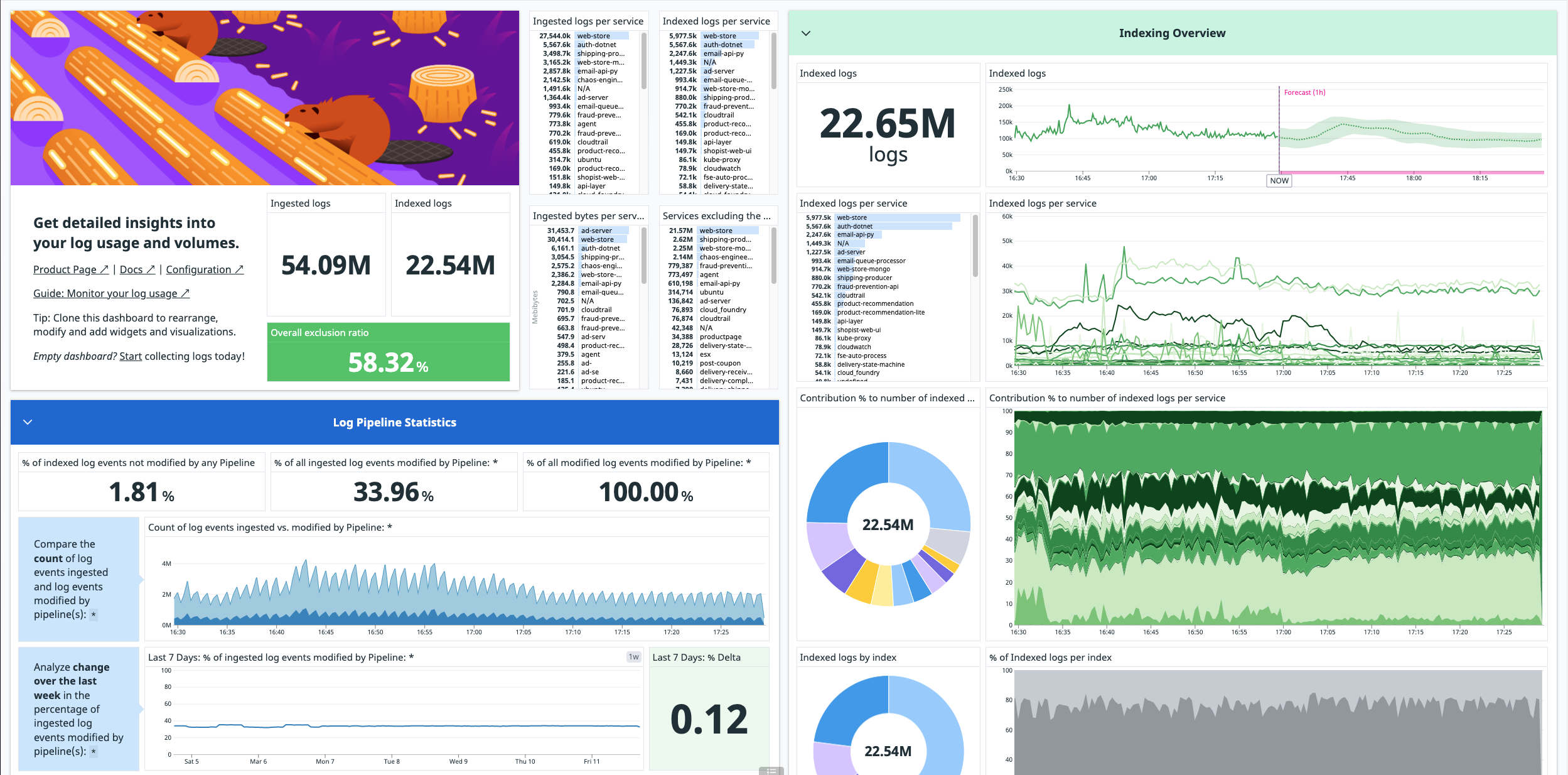
デフォルトで、ログ使用量メトリクスは取り込まれたログ、取り込まれたバイト数、インデックス化されたログの追跡に利用できます。このメトリクスは無料で利用でき、15 か月間保存できます。
datadog.estimated_usage.logs.ingested_bytesdatadog.estimated_usage.logs.ingested_events
使用量メトリクスを使った異常検出モニターの作成手順については、異常検出モニターを参照してください。
注: Datadog では、メトリクスサマリーページの datadog.estimated_usage.logs.ingested_bytes の単位を byte とすることを推奨しています。
異常検出モニター
異常検出モニターを作成し、予期せぬログのインデックス化の急増にアラートを出します。
- Monitors > New Monitor の順に移動し、Anomaly を選択します。
- Define the metric セクションで、
datadog.estimated_usage.logs.ingested_events メトリクスを選択します。 - In the from field, add the
datadog_is_excluded:false tag to monitor indexed logs and not ingested ones. - sum by フィールドに、
service と datadog_index タグを追加し、特定のサービスが急増したり、いずれかのインデックスでログの送信を停止した場合に通知されるようにします。 - アラート条件は、ユースケースに合わせて設定してください。例えば、評価された値が予想される範囲外である場合にアラートを出すようにモニターを設定します。
- 通知のタイトルと、アクションを指示するメッセージを追加します。例えば、これはコンテクストリンク付きの通知です。
An unexpected amount of logs has been indexed in the index: {{datadog_index.name}}
1. [Check Log patterns for this service](https://app.datadoghq.com/logs/patterns?from_ts=1582549794112&live=true&to_ts=1582550694112&query=service%3A{{service.name}})
2. [Add an exclusion filter on the noisy pattern](https://app.datadoghq.com/logs/pipelines/indexes)
- Create をクリックします。
インデックス化されたログボリュームが指定されたしきい値を超えた場合のアラート
インフラストラクチャー (例えば、service、availability-zone など) の任意のスコープでインデックス化されたログボリュームが予期せず増加した場合にアラートを出すようにモニターをセットアップします。
- ログエクスプローラーに移動します。
- 監視したいログボリュームをキャプチャするインデックス名 (例:
index:main) を含む検索クエリを入力します。 - Download as CSV の横の下矢印をクリックし、Create monitor を選択します。
- group by フィールドにタグ (例:
host、services など) を追加します。 - ユースケースに応じた Alert threshold を入力します。オプションで、Warning threshold を入力します。
- 通知のタイトルを追加します。例:
Unexpected spike on indexed logs for service {{service.name}}
- メッセージを追加します。例:
The volume on this service exceeded the threshold. Define an additional exclusion filter or increase the sampling rate to reduce the volume.
- Create をクリックします。
月初からのインデックス化ログ量に関するアラート
datadog_is_excluded:false でフィルターした datadog.estimated_usage.logs.ingested_events メトリクスを活用してインデックス化ログのみをカウントし、メトリクスモニター累積ウィンドウで月初からのカウントをモニターします。
Alert on indexes reaching their daily quota
Set up a daily quota on indexes to prevent indexing more than a given number of logs per day. If an index has a daily quota, Datadog recommends that you set the monitor that notifies on that index’s volume to alert when 80% of this quota is reached within the past 24 hours.
1 日の割り当てに達すると、イベントが生成されます。デフォルトでは、これらのイベントはインデックス名を持つ datadog_index タグを持っています。したがって、このイベントが生成されたら、datadog_index タグに ファセットを作成して、datadog_index を group by ステップで使用して、複数アラートモニターをセットアップできるようにします。
To set up a monitor to alert when the daily quota is reached for an index:
- Monitors > New Monitor の順に移動し、Event をクリックします。
- Define the search query セクションに
source:datadog "daily quota reached" と入力します。 - Add
datadog_index to the group by field. It automatically updates to datadog_index(datadog_index). The datadog_index(datadog_index) tag is only available when an event has already been generated. - Set alert conditions セクションで、
above or equal to を選択し、Alert threshold に 1 を入力します。 - Add a notification title and message in the Configure notifications and automations section. The Multi Alert button is automatically selected because the monitor is grouped by
datadog_index(datadog_index). - Save をクリックします。
これは、Slack での通知の例です。
推定使用量ダッシュボードを確認する
ログの取り込みを開始すると、ログ使用量メトリクスをまとめたすぐに使えるダッシュボードが自動的にアカウントにインストールされます。
注: このダッシュボードで使用されるメトリクスは推定であるため、正式な請求対象の数値とは異なる場合があります。
このダッシュボードを見つけるには、Dashboards > Dashboards List に移動し、Log Management - Estimated Usage を検索します。
大量ログの除外フィルターを設定する
使用量モニターがアラートを出す場合、除外フィルターを設定したり、サンプリングレートを上げてボリュームを減らしたりすることができます。設定方法については、除外フィルターを参照してください。また、ログパターンを使用して、大量のログをグループ化して識別することができます。次に、ログパターンのサイドパネルで、Add Exclusion Filter をクリックして、これらのログのインデックス化を停止するフィルターを追加します。
除外フィルターを使用している場合でも、ログベースのメトリクスを使用して、すべてのログデータの傾向や異常を視覚化することができます。詳しくは、取り込んだログからメトリクスを生成するを参照してください。
個人識別情報 (PII) 検出のための機密データスキャナーを有効にする
If you want to prevent data leaks and limit non-compliance risks, use Sensitive Data Scanner to identify, tag, and optionally redact or hash sensitive data. For example, you can scan for credit card numbers, bank routing numbers, and API keys in your logs, APM spans, and RUM events, See Sensitive Data Scanner on how to set up scanning rules to determine what data to scan.
注: 機密データスキャナーは、別途課金対象製品です。
ユーザーのアクティビティを確認するための監査証跡を有効にする
インデックスの保持を変更したのは誰か、除外フィルターを修正したのは誰かなど、ユーザーのアクティビティを確認したい場合は、監査証跡を有効にしてこれらのイベントを確認します。利用可能なプラットフォームおよび製品固有のイベントのリストについては、監査証跡のイベントを参照してください。監査証跡を有効にして構成するには、監査証跡のドキュメントの手順に従います。
Note: Audit Trail is a separate billable product.
その他の参考資料