概要
Knative for Anthos は、ハイブリッドおよびマルチクラウド環境のための柔軟なサーバーレス開発プラットフォームです。Knative for Anthos は、Knative サービスをフルサポートする、Google のマネージドサービスです。
Datadog Google Cloud Platform インテグレーションを使用して、Knative for Anthos からメトリクスを収集できます。
セットアップ
メトリクスの収集
インストール
Google Cloud Platform インテグレーションをまだセットアップしていない場合は、最初にセットアップします。
Workload Identity を使用してすでに Knative for Anthos サービスを認証している場合は、他に必要な操作はありません。
Workload Identity を有効にしていない場合、Knative メトリクスの収集には Workload Identity を使用するよう変更する必要があります。これには、Kubernetes サービスアカウントと Google サービスアカウントのバインディングと、Workload Identity を使用してメトリクスを回収する各サービスの構成が含まれます。
セットアップの詳しい手順については、Google Cloud Workload Identity をご覧ください。
ログ収集
Knative for Anthos はサービスログを公開します。
Knative のログは Google Cloud Logging で収集し、Cloud Pub/Sub トピックを通じて Dataflow ジョブに送信することができます。まだの場合は、Datadog Dataflow テンプレートでロギングをセットアップしてください。
これが完了したら、Google Cloud Run のログを Google Cloud Logging から Pub/Sub へエクスポートします。
Knative for Anthos へ移動し、希望するサービスをクリックして Logs タブを開きます。
View in Logs Explorer をクリックして Google Cloud Logging Page へ移動します。
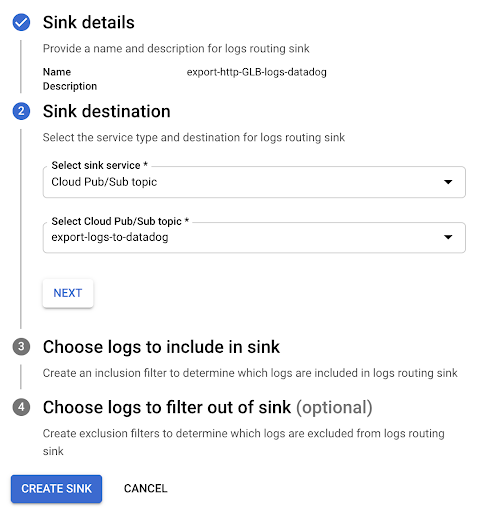
シンクを作成し、シンクに適宜名前を付けます。
エクスポート先として「Cloud Pub/Sub」を選び、その目的で作成された Pub/Sub を選択してください。注: この Pub/Sub は別のプロジェクトに置くこともできます。
作成をクリックし、確認メッセージが表示されるまで待ちます。
収集データ
メトリクス
イベント
Knative for Anthos インテグレーションには、イベントは含まれません。
サービスチェック
Knative for Anthos インテグレーションには、サービスのチェック機能は含まれません。
トラブルシューティング
ご不明な点は、Datadog のサポートチームまでお問い合わせください。
その他の参考資料