Présentation
Knative for Anthos est une plateforme flexible de développement sans serveur pour les environnements hybrides et multicloud. Knative for Anthos est l’offre Knative gérée par Google et entièrement compatible.
Utilisez l’intégration Datadog/Google Cloud Platform pour recueillir des métriques de Knative for Anthos.
Implémentation
Collecte de métriques
Installation
Si vous ne l’avez pas déjà fait, configurez d’abord l’intégration Google Cloud Platform.
Si vous authentifiez déjà vos services Knative for Anthos à l’aide de Workload Identity, aucune étape supplémentaire n’est requise.
Si vous n’avez pas activé Workload Identity, vous devez adopter Workload Identity afin de commencer à recueillir des métriques Knative. Pour y parvenir, vous devez lier un compte de service Kubernetes à un compte de service Google et configurer Workload Identity pour chaque service à partir duquel vous souhaitez recueillir des métriques.
Pour obtenir des instructions de configuration détaillées, consultez la section Utiliser Workload Identity de la documentation Google Cloud.
Collecte de logs
Knative for Anthos expose des logs de service. Les logs Knative peuvent être recueillis avec Google Cloud Logging et envoyés à un Cloud Pub/Sub via un redirecteur Push HTTP. Si vous ne l’avez pas déjà fait, configurez le Cloud Pub/Sub à l’aide d’un redirecteur Push HTTP.
Une fois cette opération effectuée, exportez vos logs Google Cloud Run depuis Google Cloud Logging vers le Pub/Sub :
Accédez à Knative for Anthos, cliquez sur les services de votre choix, puis accédez à l’onglet Logs.
Cliquez sur View in Logs Explorer pour accéder à la page Google Cloud Logging.
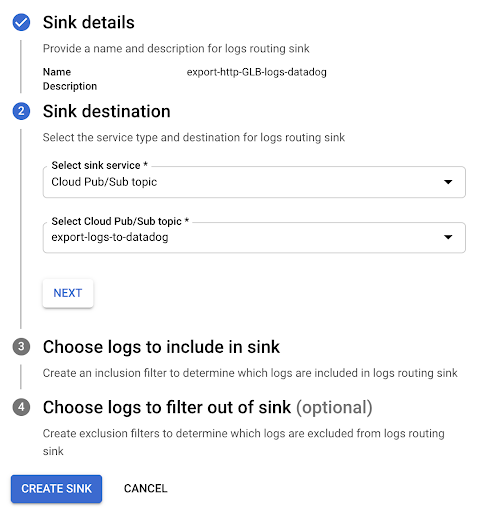
Cliquez sur Create Sink et nommez le récepteur.
Choisissez Cloud Pub/Sub comme destination et sélectionnez le Pub/Sub créé à cette fin. Remarque : le Pub/Sub peut se situer dans un autre projet.
Cliquez sur Create et attendez que le message de confirmation s’affiche.
Données collectées
Métriques
Événements
L’intégration Knative for Anthos n’inclut aucun événement.
Checks de service
L’intégration Knative for Anthos n’inclut aucun check de service.
Dépannage
Besoin d’aide ? Contactez l’assistance Datadog.
Pour aller plus loin
Documentation, liens et articles supplémentaires utiles: