L’APM Datadog vous permet de créer des dashboards en fonction des priorités de votre entreprise et des métriques qui vous importent :
Vous pouvez créer des widgets sur ces dashboards afin de suivre vos métriques d’infrastructure traditionnelles, vos métriques de log et vos métriques custom, telles que la charge mémoire du host, conjointement à vos métriques APM critiques mesurant le débit, la latence et le taux d’erreur de façon à mettre toutes ces données en corrélation.
Il est également possible de suivre la latence de l’expérience utilisateur pour les clients et les transactions critiques tout en surveillant les performances de votre serveur Web principal en prévision d’un événement majeur, tel que le 1er jour des soldes.
Dans ce guide, vous découvrirez comment procéder pour ajouter des métriques de trace à un dashboard, les corréler avec vos métriques d’infrastructure, puis exporter une requête Analytics. L’ajout de widgets à un dashboard peut se faire de trois façons différentes :
Ouvrez la page contenant la liste des services et sélectionnez le service web-store.
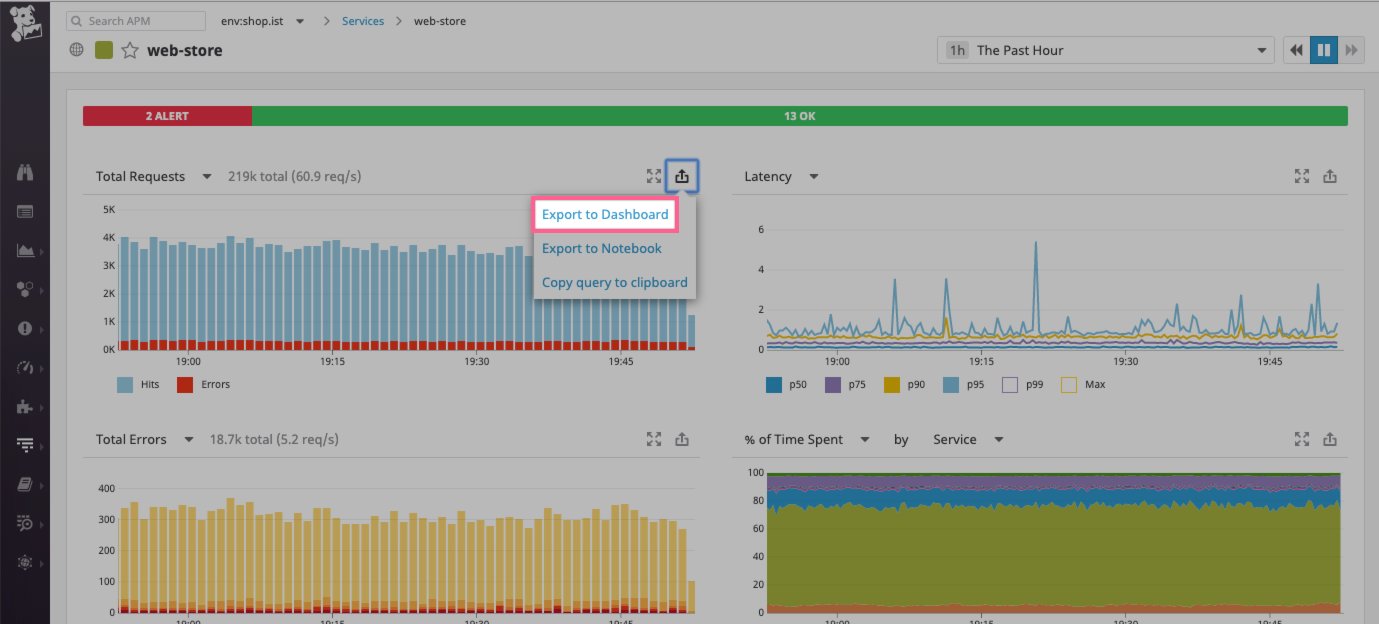
Recherchez le graphique Total Requests et cliquez sur le bouton export en haut à droite afin de sélectionner Export to Dashboard. Cliquez sur New Timeboard.
Cliquez sur View Dashboard dans le message de réussite.
Dans le nouveau dashboard, le graphique Hit/error count on service correspondant au service web-store est maintenant disponible. Il affiche le débit global du service ainsi que le nombre total d’erreurs détectées.
Remarque : vous pouvez cliquer sur l’icône en forme de crayon pour modifier ce graphique et voir les métriques exactes utilisées.
Cliquez sur Add graph dans le carré d’espace réservé au sein du dashboard, puis faites glisser une Timeseries vers cet espace.
Vous accédez alors à l’écran de modification des widgets du dashboard. Celui-ci vous permet de représenter comme bon vous semble les métriques de votre choix. Consultez la documentation relative au widget Série temporelle pour en savoir plus.
Cliquez sur la case system.cpu.user et sélectionnez la métrique et les paramètres qui vous intéressent. Cet exemple utilise les paramètres suivants :
| Paramètre | Valeur | Description |
|---|
metric | trace.rack.requests.errors | Le nombre total de requêtes Ruby Rack ayant généré une erreur. |
from | service:web-store | Dans cet exemple de pile, le service principal est un service Ruby à partir duquel proviennent toutes les informations présentées sur le graphique. |
sum by | http.status_code | Permet de présenter les données en fonction des codes de statut http. |
Cette présentation n’est qu’un exemple parmi bien d’autres options possibles. Il convient de noter que toutes les métriques qui commencent par trace. contiennent des informations sur l’APM. Consultez la documentation sur les métriques de l’APM pour en savoir plus.
Faites glisser d’autres séries temporelles vers le carré d’espace réservé
Dans cet exemple, deux métriques distinctes sont représentées sur un graphique : une métrique trace.* et une métrique runtime.*. Lorsqu’elles sont visualisées côte à côte, ces métriques vous permettent de mettre en corrélation les informations sur vos requêtes avec celles sur les performances d’exécution du code. Les pics de latence étant parfois liés à une augmentation du nombre de threads, nous allons représenter la latence d’un service en même temps que le nombre de threads :
Commencez par ajouter la métrique trace.rack.requests.errors au widget :
| Paramètre | Valeur | Description |
|---|
metric | trace.rack.request.duration.by.service.99p | Le 99e centile de latence des requêtes au sein de notre service. |
from | service:web-store | Dans cet exemple de pile, le service principal est un service Ruby à partir duquel proviennent toutes les informations présentées sur le graphique. |
Cliquez ensuite sur Graph additional: Metrics pour ajouter une autre métrique sur le graphique :
| Paramètre | Valeur | Description |
|---|
metric | runtime.ruby.thread_count | Nombre de threads mesuré par les métriques runtime Ruby. |
from | service:web-store | Dans cet exemple de pile, le service principal est un service Ruby à partir duquel proviennent toutes les informations présentées sur le graphique. |
Avec ces paramètres, il est possible de déterminer si un pic de latence est lié à une hausse du nombre de threads Ruby, ce qui expliquerait immédiatement la cause de la latence et permettrait ainsi de résoudre rapidement le problème.
Accédez à Analytics.
Cet exemple illustre la marche à suivre pour mesurer la latence au sein d’une application, en classant les résultats par marchand afin d’identifier les 10 marchands qui présentent la latence la plus élevée. Depuis l’écran Analytics, exportez le graphique vers le dashboard et affichez-le dans celui-ci :
Revenez à votre dashboard.
Plusieurs widgets sont désormais visibles, vous permettant ainsi d’analyser en détail l’application aussi bien d’un point de vue technique que commercial. Il ne s’agit toutefois que d’une possibilité parmi tant d’autres : il est possible d’ajouter des métriques d’infrastructure, d’utiliser un autre type de visualisation ou encore d’ajouter des calculs et des projections.
Le dashboard vous permet également de visualiser les événements associés.
Cliquez sur le bouton Search Events or Logs et recherchez un flux d’événements pertinent. Remarque : Ansible est utilisé dans cet exemple. Il se peut que votre flux d’événements soit différent.
Les événements qui se sont produits récemment (dans Datadog ou dans des services externes comme Ansible, Chef, etc.) s’affichent alors au sein du dashboard : ceux-ci comprennent notamment les déploiements, les tâches terminées ou les alertes de monitors. Ces événements peuvent être corrélés avec les métriques représentées dans le dashboard.
Enfin, assurez-vous d’utiliser les template variables. Ces dernières correspondent à un ensemble de valeurs qui permettent à chaque utilisateur de contrôler les widgets d’un dashboard de façon dynamique, sans avoir à modifier les widgets eux-mêmes.
Cliquez sur Add Template Variables dans la zone de configuration. Cliquez sur Add Variable +, nommez la template variable et choisissez le tag que la variable doit contrôler.
Dans cet exemple, une template variable associée au tag Region est ajoutée pour surveiller le comportement des données du dashboard au sein de us-east1 et de europe-west-4, nos deux principales zones d’activité.
Vous pouvez maintenant ajouter cette template variable à chaque graphique :
Lorsque vous modifiez la valeur dans la zone de configuration, toutes les valeurs sont mises à jour dans le dashboard :
Tirez parti de ces fonctionnalités pour mettre en œuvre les trois piliers de la visibilité de Datadog et profiter d’une visibilité optimale sur toutes vos métriques. Un dashboard simple peut être transformé en outil tout-en-un puissant qui vous permettra de surveiller efficacement votre organisation :