Knative para Anthos es una plataforma de desarrollo serverless flexible para entornos híbridos y multinube. Knative para Anthos es la oferta de Knative gestionada y totalmente compatible con Google.
Utiliza la integración de Datadog Google Cloud Platform para recopilar métricas de Knative para Anthos.
Configuración
Recopilación de métricas
Instalación
Si aún no lo has hecho, configura la integración de Google Cloud Platform.
Si ya estás autenticando tus servicios de Knative para Anthos con Workload Identity, entonces no se necesitan más pasos.
Si no has habilitado Workload Identity, debes migrar para utilizar Workload Identity y empezar a recopilar métricas de Knative. Esto implica vincular una cuenta de servicio de Kubernetes a una cuenta de servicio de Google y configurar cada servicio del que quieres recopilar métricas para que utilice Workload Identity.
Para obtener instrucciones detalladas de configuración, consulta Identidad de cargas de trabajo de Google Cloud.
Recopilación de logs
Knative for Anthos expone logs de servicio.
Los logs de Knative pueden recopilarse con Google Cloud Logging y enviarse a un trabajo de Dataflow a través de un tema Cloud Pub/Sub. Si aún no lo has hecho, configura el registro con la plantilla de Datadog Dataflow.
Una vez hecho esto, exporta tus logs de Google Cloud Run desde Google Cloud Logging a Pub/Sub:
Ve a Knative para Anthos, haz clic en los servicios que desees y navega hasta la pestaña Logs.
Haz clic en View in Logs Explorer (Ver en el Explorador de logs) para ir a la Página de generación de logs de Google Cloud.
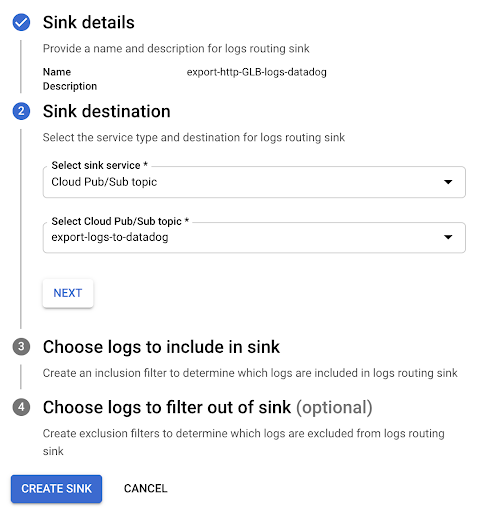
Haz clic en Create sink (Crear sumidero) y asigna al sumidero el nombre correspondiente.
Elige “Cloud Pub/Sub” como destino y selecciona el Pub/Sub creado a tal efecto. Nota: El Pub/Sub puede estar ubicado en un proyecto diferente.
Haz clic en Create (Crear) y espera a que aparezca el mensaje de confirmación.
Datos recopilados
Métricas
| |
|---|
gcp.knative.eventing.broker.event_count
(count) | Número de eventos recibidos por un broker. |
gcp.knative.eventing.trigger.event_count
(count) | Número de eventos recibidos por un activador. |
gcp.knative.eventing.trigger.event_dispatch_latencies.avg
(gauge) | Promedio de tiempo empleado en enviar un evento a un suscriptor de activación.
Se muestra en milisegundos |
gcp.knative.eventing.trigger.event_dispatch_latencies.p99
(gauge) | Percentil 99 del tiempo empleado en enviar un evento a un suscriptor de activación.
Se muestra en milisegundos |
gcp.knative.eventing.trigger.event_dispatch_latencies.p95
(gauge) | Percentil 95 del tiempo empleado en enviar un evento a un suscriptor de activación.
Se muestra en milisegundos |
gcp.knative.eventing.trigger.event_processing_latencies.avg
(gauge) | Promedio de tiempo empleado en procesar un evento antes de que se envíe a un suscriptor de activación.
Se muestra en milisegundos |
gcp.knative.eventing.trigger.event_processing_latencies.p99
(gauge) | Percentil 99 del tiempo empleado en procesar un evento antes de que se envíe a un suscriptor de activación.
Se muestra en milisegundos |
gcp.knative.eventing.trigger.event_processing_latencies.p95
(gauge) | Percentil 95 del tiempo empleado en procesar un evento antes de que se envíe a un suscriptor de activación.
Se muestra en milisegundos |
gcp.knative.serving.activator.request_count
(count) | El número de solicitudes que se dirigen al activador.
Se muestra como solicitud |
gcp.knative.serving.activator.request_latencies.avg
(gauge) | Media de los tiempos de solicitud de servicio en milisegundos para las solicitudes que pasan por el activador.
Se muestra en milisegundos |
gcp.knative.serving.activator.request_latencies.p99
(gauge) | Percentil 99 de los tiempos de solicitud de servicio en milisegundos para las solicitudes que pasan por el activador.
Se muestra en milisegundos |
gcp.knative.serving.activator.request_latencies.p95
(gauge) | Percentil 95 de los tiempos de solicitud de servicio en milisegundos para las solicitudes que pasan por el activador.
Se muestra en milisegundos |
gcp.knative.serving.autoscaler.actual_pods
(gauge) | Número de pods asignados actualmente. |
gcp.knative.serving.autoscaler.desired_pods
(gauge) | Número de pods que el autoescalador quiere asignar. |
gcp.knative.serving.autoscaler.panic_mode
(gauge) | Se establece en 1 si el autoescalador está en modo pánico para la revisión, en caso contrario 0. |
gcp.knative.serving.autoscaler.panic_request_concurrency
(gauge) | Promedio de concurrencia de solicitudes observado por pod durante la ventana de autoescalado de pánico más corta.
Se muestra como solicitud |
gcp.knative.serving.autoscaler.requested_pods
(gauge) | Número de pods de autoescalador solicitados a Kubernetes. |
gcp.knative.serving.autoscaler.stable_request_concurrency
(gauge) | Promedio de concurrencia de solicitudes observado por pod durante la ventana estable de autoescalado.
Se muestra como solicitud |
gcp.knative.serving.autoscaler.target_concurrency_per_pod
(gauge) | La concurrencia media deseada de solicitudes por pod durante la ventana estable de autoescalado.
Se muestra como solicitud |
gcp.knative.serving.revision.request_count
(count) | El número de solicitudes que llegan a la revisión.
Se muestra como solicitud |
gcp.knative.serving.revision.request_latencies.avg
(gauge) | Media de los tiempos de solicitud de servicio en milisegundos para las solicitudes que llegan a la revisión.
Se muestra en milisegundos |
gcp.knative.serving.revision.request_latencies.p99
(gauge) | Percentil 99 de los tiempos de solicitud de servicio en milisegundos para las solicitudes que llegan a la revisión.
Se muestra en milisegundos |
gcp.knative.serving.revision.request_latencies.p95
(gauge) | Percentil 95 de los tiempos de solicitud de servicio en milisegundos para las solicitudes que llegan a la revisión.
Se muestra en milisegundos |
Eventos
La integración de Knative para Anthos no incluye ningún evento.
Checks de servicio
La integración de Knative para Anthos no incluye ningún check de servicio.
Solucionar problemas
¿Necesitas ayuda? Ponte en contacto con el servicio de asistencia de Datadog.
Referencias adicionales
Más enlaces, artículos y documentación útiles: