Overview
Use an integration monitor to check if an installed integration is running. For more detailed monitoring, a metric monitor can be used to gauge specific information about an integration.
Monitor creation
To create an integration monitor in Datadog:
- Use the main navigation: Monitors –> New Monitor –> Integration.
- Search for an integration or select it from the list or images.
Integration metric
Create an integration metric monitor by following the instructions in the metric monitor documentation. Using the integration metric monitor type ensures the monitor can be selected by the integration monitor type facet on the Manage Monitors page.
Note: To configure an integration monitor, ensure that the integration submits metrics or service checks.
Pick a check
If there is only one check for the integration, no selection is necessary. Otherwise, select the check for your monitor.
Pick monitor scope
Select the scope to monitor by choosing host names, tags, or choose All Monitored Hosts. If you need to exclude certain hosts, use the second field to list names or tags.
- The include field uses
AND logic. All listed host names and tags must be present on a host for it to be included. - The exclude field uses
OR logic. Any host with a listed host name or tag is excluded.
Set alert conditions
In this section, choose between a Check Alert or Cluster Alert:
A check alert tracks consecutive statuses submitted per check grouping and compares it to your thresholds.
Set up the check alert:
Trigger a separate alert for each <GROUP> reporting your check.
Check grouping is specified either from a list of known groupings or by you. For integration monitors, the per-check grouping is explicitly known. For example, the Postgres integration is tagged with db, host, and port.
Trigger the alert after selected consecutive failures: <NUMBER>
Each check run submits a single status of OK, WARN, CRITICAL, or UNKNOWN. Choose how many consecutive runs with the CRITICAL status trigger a notification. For example, your database might have a single blip where connection fails. If you set this value to > 1, the blip is ignored but a problem with more than one consecutive failure triggers a notification.
If the integration check reports an UNKNOWN status, choose Do not notify or Notify for Unknown status.
If enabled, a state transition to UNKNOWN triggers a notification. In the monitor status page, the status bar of a group in UNKNOWN state uses NODATA grey. The overall status of the monitor stays in OK.
Resolve the alert after selected consecutive successes: <NUMBER>
Choose how many consecutive runs with the OK status resolve the alert.
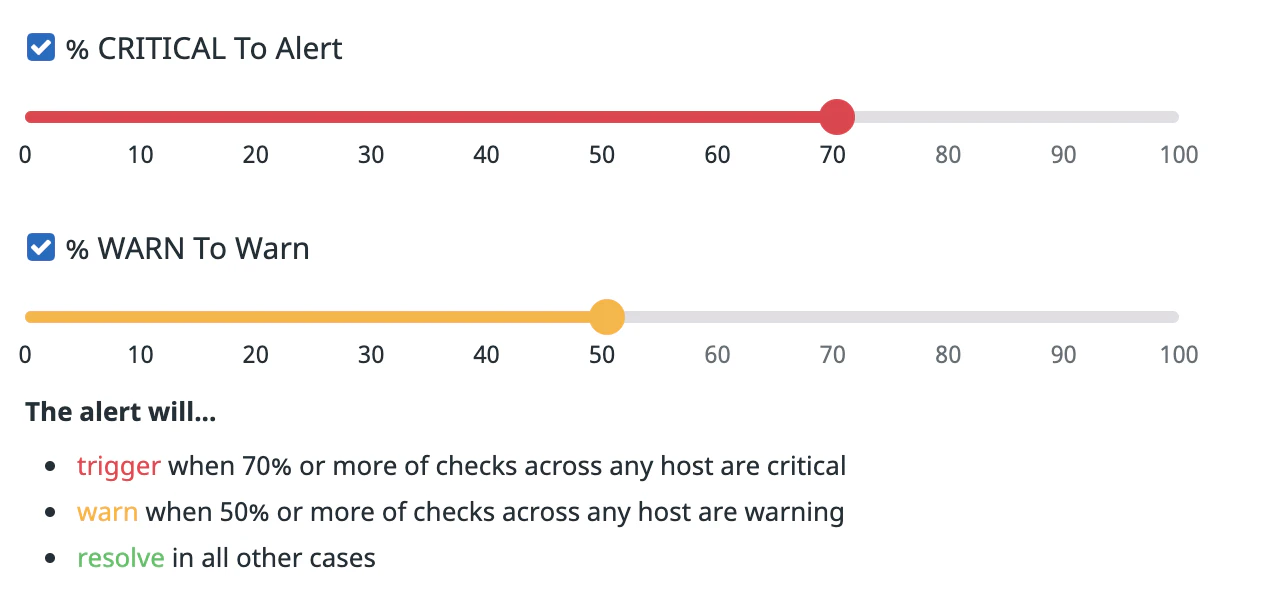
A cluster alert calculates the percent of checks in a given status and compares it to your thresholds.
Set up a cluster alert:
Decide whether or not to group your checks according to a tag. Ungrouped calculates the status percentage across all sources. Grouped calculates the status percentage on a per group basis.
Select the percentage for the alert threshold.
Each check tagged with a distinct combination of tags is considered to be a distinct check in the cluster. Only the status of the last check of each combination of tags is taken into account in the cluster percentage calculation.
For example, a cluster check monitor grouped by environment can alert if more that 70% of the checks on any of the environments submit a CRITICAL status, and warn if more that 50% of the checks on any of the environments submit a WARN status.
Advanced alert conditions
See the Monitor configuration documentation for information on No data, Auto resolve, and New group delay options.
Notifications
For detailed instructions on the Configure notifications and automations section, see the Notifications page.
Further Reading
Additional helpful documentation, links, and articles: