Datadog automatically parses JSON-formatted logs. For other formats, Datadog allows you to enrich your logs with the help of Grok Parser.
The Grok syntax provides an easier way to parse logs than pure regular expressions. The Grok Parser enables you to extract attributes from semi-structured text messages.
Grok comes with reusable patterns to parse integers, IP addresses, hostnames, etc. These values must be sent into the grok parser as strings.
You can write parsing rules with the %{MATCHER:EXTRACT:FILTER} syntax:
Matcher: A rule (possibly a reference to another token rule) that describes what to expect (number, word, notSpace, etc.).
Extract (optional): An identifier representing the capture destination for the piece of text matched by the Matcher.
Filter (optional): A post-processor of the match to transform it.
Example for a classic unstructured log:
john connected on 11/08/2017
With the following parsing rule:
MyParsingRule %{word:user} connected on %{date("MM/dd/yyyy"):date}
After processing, the following structured log is generated:
Note:
If you have multiple parsing rules in a single Grok parser:
Only one can match any given log. The first one that matches, from top to bottom, is the one that does the parsing.
Each rule can reference parsing rules defined above itself in the list.
You must have unique rule names within the same Grok parser.
The rule name must contain only: alphanumeric characters, _, and .. It must start with an alphanumeric character.
Properties with null or empty values are not displayed.
You must define your parsing rule to match the entire log entry, as each rule applies from the beginning to the end of the log.
Certain logs can produce large gaps of whitespace. Use \n and \s+ to account for newlines and whitespace.
Matcher and filter
Grok parsing features available at query-time (in Log Workspaces and in the Log Explorer) support a limited subset of matchers (data, integer, notSpace, number, and word) and filters (number and integer).
The following full set of matchers and filters are specific to ingest-timeGrok Parser functionality.
Here is a list of all the matchers and filters natively implemented by Datadog:
Matches and parses a Boolean, optionally defining the true and false patterns (defaults to true and false, ignoring case).
numberStr
Matches a decimal floating point number and parses it as a string.
number
Matches a decimal floating point number and parses it as a double precision number.
numberExtStr
Matches a floating point number (with scientific notation support) and parses it as a string.
numberExt
Matches a floating point number (with scientific notation support) and parses it as a double precision number.
integerStr
Matches an integer number and parses it as a string.
integer
Matches an integer number and parses it as an integer number.
integerExtStr
Matches an integer number (with scientific notation support) and parses it as a string.
integerExt
Matches an integer number (with scientific notation support) and parses it as an integer number.
word
Matches a word, which starts with a word boundary; contains characters from a-z, A-Z, 0-9, including the _ (underscore) character; and ends with a word boundary. Equivalent to \b\w+\b in regex.
doubleQuotedString
Matches a double-quoted string.
singleQuotedString
Matches a single-quoted string.
quotedString
Matches a double-quoted or single-quoted string.
uuid
Matches a UUID.
mac
Matches a MAC address.
ipv4
Matches an IPV4.
ipv6
Matches an IPV6.
ip
Matches an IP (v4 or v6).
hostname
Matches a hostname.
ipOrHost
Matches a hostname or IP.
port
Matches a port number.
data
Matches any string including spaces and newlines. Equivalent to .* in regex. Use when none of above patterns is appropriate.
number
Parses a match as double precision number.
integer
Parses a match as an integer number.
boolean
Parses ’true’ and ‘false’ strings as booleans ignoring case.
nullIf("value")
Returns null if the match is equal to the provided value.
json
Parses properly formatted JSON.
rubyhash
Parses a properly formatted Ruby hash such as {name => "John", "job" => {"company" => "Big Company", "title" => "CTO"}}
useragent([decodeuricomponent:true/false])
Parses a user-agent and returns a JSON object that contains the device, OS, and the browser represented by the Agent. Check the User Agent processor.
querystring
Extracts all the key-value pairs in a matching URL query string (for example, ?productId=superproduct&promotionCode=superpromo).
decodeuricomponent
Decodes URI components. For instance, it transforms %2Fservice%2Ftest into /service/test.
Parses a string sequence of tokens and returns it as an array. See the list to array example.
url
Parses a URL and returns all the tokenized members (domain, query params, port, etc.) in a JSON object. More info on how to parse URLs.
Advanced settings
At the bottom of your Grok processor tiles, there is an Advanced Settings section:
Parsing a specific text attribute
Use the Extract from field to apply your Grok processor on a given text attribute instead of the default message attribute.
For example, consider a log containing a command.line attribute that should be parsed as a key-value. You could parse this log as follows:
Using helper rules to factorize multiple parsing rules
Use the Helper Rules field to define tokens for your parsing rules. Helper rules help you to factorize Grok patterns across your parsing rules. This is useful when you have several rules in the same Grok parser that use the same tokens.
Example for a classic unstructured log:
john id:12345 connected on 11/08/2017 on server XYZ in production
Use the following parsing rule:
MyParsingRule %{user} %{connection} %{server}
With the following helpers:
user %{word:user.name} id:%{integer:user.id}
connection connected on %{date("MM/dd/yyyy"):connect_date}
server on server %{notSpace:server.name} in %{notSpace:server.env}
This is the key-value core filter: keyvalue([separatorStr[, characterAllowList[, quotingStr[, delimiter]]]]) where:
separatorStr: defines the separator between key and values. Defaults to =.
characterAllowList: defines extra non-escaped value chars in addition to the default \\w.\\-_@. Used only for non-quoted values (for example, key=@valueStr).
delimiter: defines the separator between the different key values pairs (for example, |is the delimiter in key1=value1|key2=value2). Defaults to (normal space), , and ;.
Use filters such as keyvalue to more-easily map strings to attributes for keyvalue or logfmt formats:
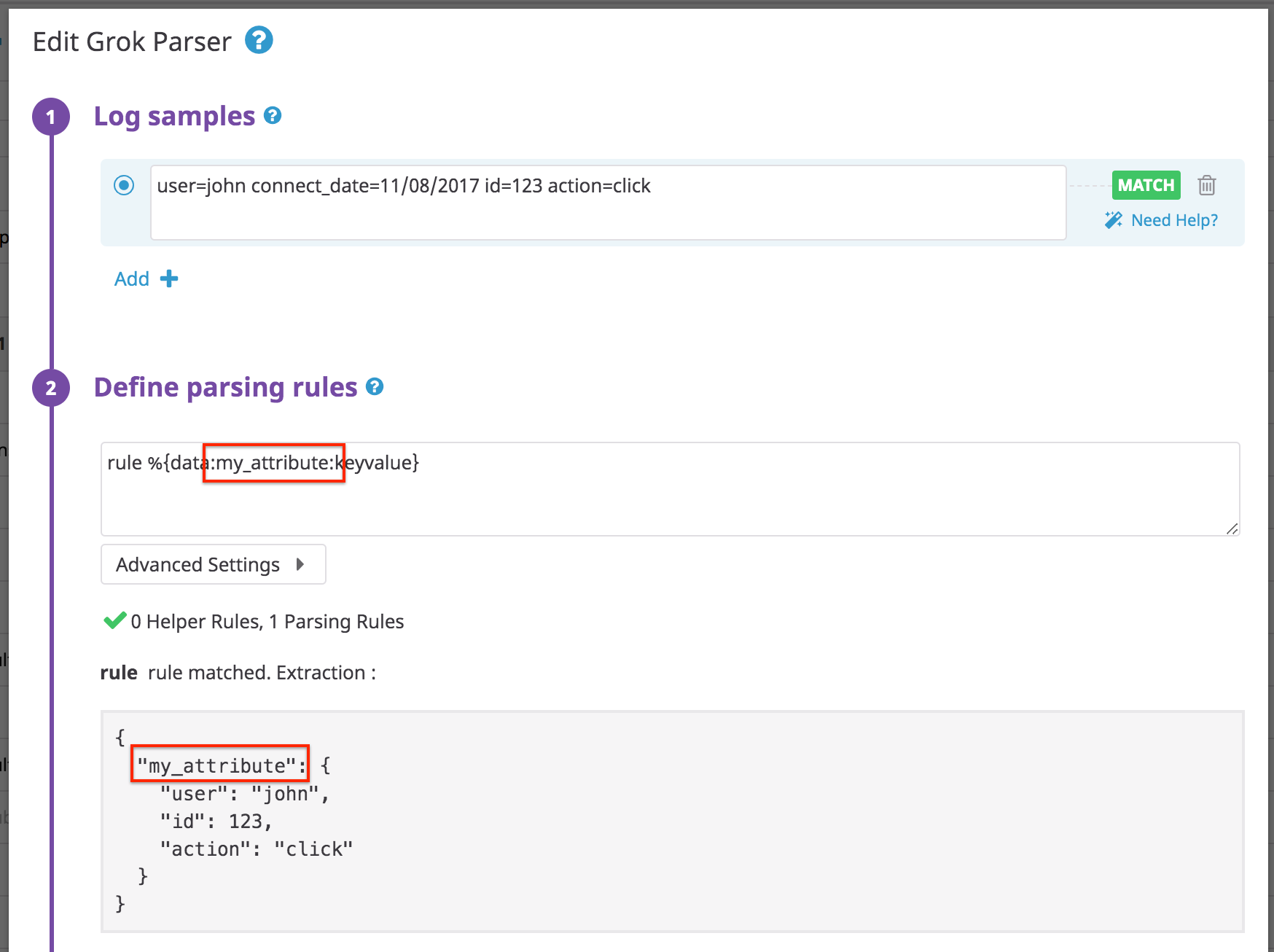
You don’t need to specify the name of your parameters as they are already contained in the log.
If you add an extract attribute my_attribute in your rule pattern you will see:
If = is not the default separator between your key and values, add a parameter in your parsing rule with a separator.
Log:
user: john connect_date: 11/08/2017 id: 123 action: click
Rule:
rule %{data::keyvalue(": ")}
If logs contain special characters in an attribute value, such as / in a url for instance, add it to the allowlist in the parsing rule:
Multiple QuotingString example: When multiple quotingstring are defined, the default behavior is replaced with a defined quoting character.
The key-value always matches inputs without any quoting characters, regardless of what is specified in quotingStr. When quoting characters are used, the characterAllowList is ignored as everything between the quoting characters is extracted.
Empty values (key=) or null values (key=null) are not displayed in the output JSON.
If you define a keyvalue filter on a data object, and this filter is not matched, then an empty JSON {} is returned (for example, input: key:=valueStr, parsing rule: rule_test %{data::keyvalue("=")}, output: {}).
Defining "" as quotingStr keeps the default configuration for quoting.
Parsing dates
The date matcher transforms your timestamp in the EPOCH format (unit of measure millisecond).
1 Use the timezone parameter if you perform your own localizations and your timestamps are not in UTC.
The supported format for timezones are:
GMT, UTC, UT or Z
+h, +hh, +hh:mm, -hh:mm, +hhmm, -hhmm, +hh:mm:ss, -hh:mm:ss, +hhmmss or -hhmmss . The maximum supported range is from +18:00 to -18:00 inclusive.
Timezones starting with UTC+, UTC-, GMT+, GMT-, UT+ or UT-. The maximum supported range is from +18:00 to -18:00 inclusive.
Timezone IDs pulled from the TZ database. For more information, see TZ database names.
Note: Parsing a date doesn’t set its value as the log official date. For this use the Log Date Remapper in a subsequent Processor.
Alternating pattern
If you have logs with two possible formats which differ in only one attribute, set a single rule using alternating with (<REGEX_1>|<REGEX_2>). This rule is equivalent to a Boolean OR.
Log:
john connected on 11/08/2017
12345 connected on 11/08/2017
Rule:
Note that “id” is an integer and not a string.
MyParsingRule (%{integer:user.id}|%{word:user.firstname}) connected on %{date("MM/dd/yyyy"):connect_date}
Results:
Optional attribute
Some logs contain values that only appear part of the time. In this case, make attribute extraction optional with ()?.
Log:
john 1234 connected on 11/08/2017
Rule:
MyParsingRule %{word:user.firstname} (%{integer:user.id} )?connected on %{date("MM/dd/yyyy"):connect_date}
Note: A rule will not match if you include a space after the first word in the optional section.
Nested JSON
Use the json filter to parse a JSON object nested after a raw text prefix:
Use the array([[openCloseStr, ] separator][, subRuleOrFilter) filter to extract a list into an array in a single attribute. The subRuleOrFilter is optional and accepts these filters.
Log:
Users [John, Oliver, Marc, Tom] have been added to the database
Rule:
myParsingRule Users %{data:users:array("[]",",")} have been added to the database
Log:
Users {John-Oliver-Marc-Tom} have been added to the database
Rule:
myParsingRule Users %{data:users:array("{}","-")} have been added to the database
Rule using subRuleOrFilter:
myParsingRule Users %{data:users:array("{}","-", uppercase)} have been added to the database
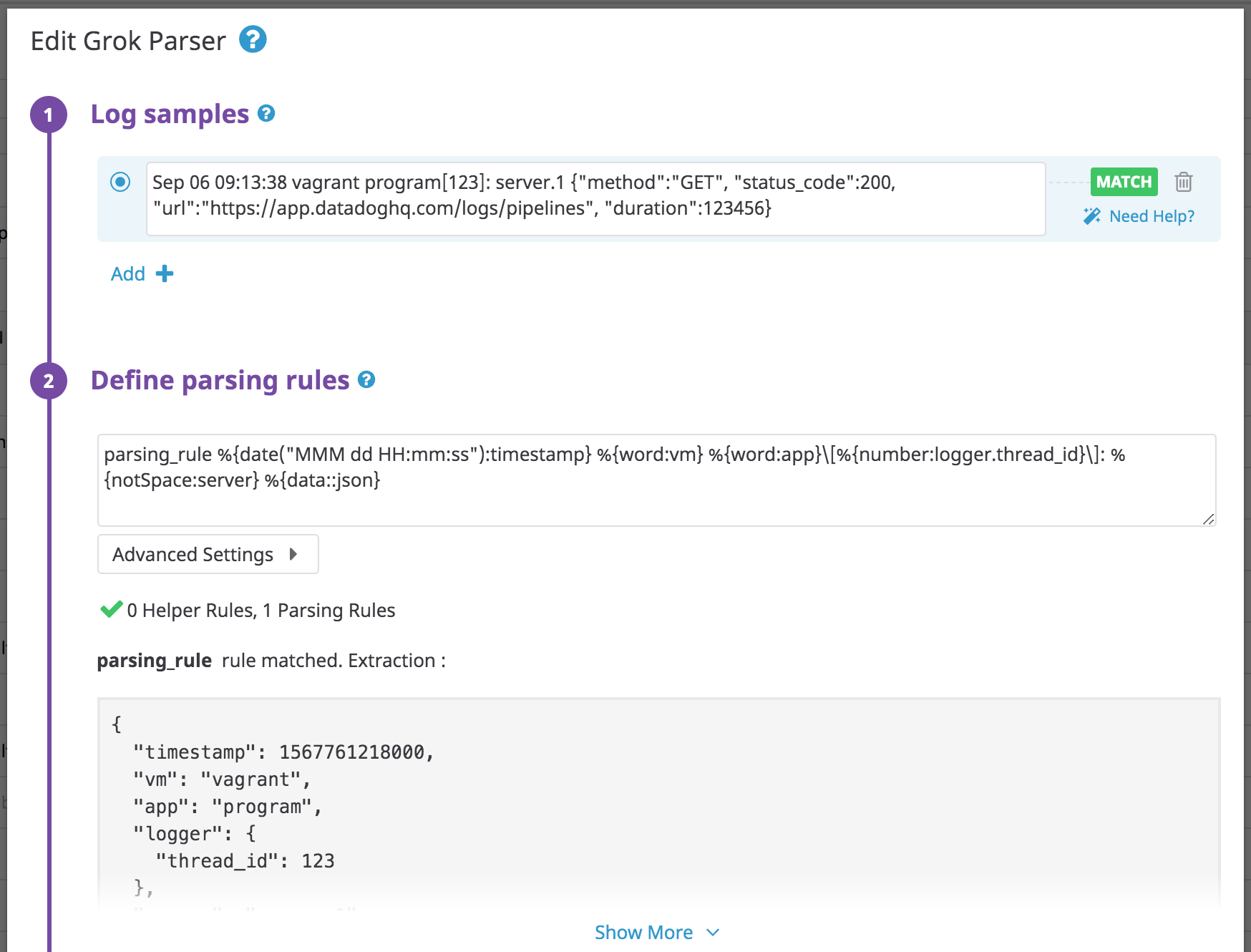
Glog format
Kubernetes components sometimes log in the glog format; this example is from the Kube Scheduler item in the Pipeline Library.
Example log line:
W0424 11:47:41.605188 1 authorization.go:47] Authorization is disabled
{"level":"W","timestamp":1587728861605,"logger":{"thread_id":1,"name":"authorization.go"},"lineno":47,"msg":"Authorization is disabled"}
Parsing XML
The XML parser transforms XML formatted messages into JSON.
Log:
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
</book>
Rule:
rule %{data::xml}
Result:
{"book":{"year":"2005","author":"J K. Rowling","category":"CHILDREN","title":{"lang":"en","value":"Harry Potter"}}}
Notes:
If the XML contains tags that have both an attribute and a string value between the two tags, a value attribute is generated. For example: <title lang="en">Harry Potter</title> is converted to {"title": {"lang": "en", "value": "Harry Potter" } }
Repeated tags are automatically converted to arrays. For example: <bookstore><book>Harry Potter</book><book>Everyday Italian</book></bookstore> is converted to { "bookstore": { "book": [ "Harry Potter", "Everyday Italian" ] } }
Parsing CSV
Use the CSV filter to more-easily map strings to attributes when separated by a given character (, by default).
The CSV filter is defined as csv(headers[, separator[, quotingcharacter]]) where:
headers: Defines the keys name separated by ,. Keys names must start with alphabetical character and can contain any alphanumerical character in addition to _.
separator: Defines separators used to separate the different values. Only one character is accepted. Default: ,. Note: Use tab for the separator to represent the tabulation character for TSVs.
quotingcharacter: Defines the quoting character. Only one character is accepted. Default: "
Note:
Values containing a separator character must be quoted.
Quoted Values containing a quoting character must be escaped with a quoting characters. For example, "" within a quoted value represents ".
If the log doesn’t contain the same number of value as the number of keys in the header, the CSV parser will match the first ones.
Intergers and Double are automatically casted if possible.
If you have a log where after you have parsed what is needed and know that the text after that point is safe to discard, you can use the data matcher to do so. For the following log example, you can use the data matcher to discard the % at the end.
If your logs contain ASCII control characters, they are serialized upon ingestion. These can be handled by explicitly escaping the serialized value within your grok parser.
Further Reading
Additional helpful documentation, links, and articles: