Datadog effectue automatiquement le parsing de vos logs au format JSON. Pour les autres formats, Datadog vous permet d’enrichir vos logs à l’aide du parser Grok.
Comparée à l’utilisation exclusive d’expressions régulières, la syntaxe Grok simplifie le parsing des logs. Le parser Grok vous permet d’extraire des attributs à partir de messages texte semi-structurés.
Grok propose des patterns réutilisables pour parser des entiers, des adresses IP, des hostnames, etc.
Vous pouvez rédiger des règles de parsing à l’aide de la syntaxe %{MATCHER:EXTRACT:FILTER} :
Matcher : une règle (éventuellement une référence à la règle d’un autre token) qui décrit la valeur attendue (number, word, notSpace, etc.).
Extract (facultatif) : un identifiant représentant la destination d’enregistrement pour le morceau de texte correspondant au Matcher.
Filter (facultatif) : un post-processeur de la correspondance permettant de la transformer.
Exemple d’un log non structuré standard :
john connected on 11/08/2017
Avec la règle de parsing suivante :
MyParsingRule %{word:user} connected on %{date("MM/dd/yyyy"):connect_date}
Une fois le traitement terminé, le log structuré suivant est généré :
Remarques :
Si vous cumulez plusieurs règles de parsing dans un seul parser Grok :
Une seule d’entre elles peut renvoyer un log donné. La première qui correspond en totalité est celle qui effectue le parsing.
Chaque règle peut se référer à des règles de parsing définies en amont dans la liste.
Les noms des règles au sein d’un même parser Grok doivent être uniques.
Les noms des règles doivent contenir uniquement des caractères alphanumériques, ainsi que les caractères _ et .. Ils doivent commencer par un caractère alphanumérique.
Les propriétés avec des valeurs null ou vides ne sont pas affichées.
Une description détaillée de la syntaxe acceptée par l’Agent pour les expressions régulières est disponible sur le référentiel RE2.
Le matcher d’expression régulière applique un ^ implicite, afin de renvoyer le début d’une chaîne, ainsi qu’un $, afin de renvoyer la fin d’une chaîne.
Certains logs peuvent générer une grande quantité d’espaces. Utilisez \n et \s+ pour tenir compte des retours à la ligne et des espaces.
Matcher et filtre
Voici la liste de tous les matchers et de tous les filtres implémentés en natif par Datadog :
Parse un user-agent et renvoie un objet JSON qui contient l’appareil, le système d’exploitation et le navigateur représentés par l’Agent. En savoir plus sur le processeur d’user-agent.
querystring
Extrait toutes les paires key/value d’une chaîne de requête URL correspondante (par exemple, ?productId=superproduct&promotionCode=superpromo).
decodeuricomponent
Décode les composants d’un URI. Transforme par exemple %2Fservice%2Ftest en /service/test.
Parse une séquence de tokens et la renvoie en tant que tableau.
url
Parse une URL et renvoie tous les membres tokenisés (domaine, paramètres de requête, port, etc.) dans un objet JSON. En savoir plus sur le parsing d’URL.
Paramètres avancés
En bas de vos carrés de processeur Grok, vous trouverez une section Advanced Settings :
Parsing d’un attribut texte spécifique
Utilisez le champ Extract from pour appliquer votre processeur Grok sur un attribut texte donné plutôt que sur l’attribut message par défaut.
Imaginez par exemple un log contenant un attribut command.line devant être parsé en tant que key/value. Le parsing de ce log peut se faire comme suit :
Utiliser des règles d’auxiliaires pour factoriser plusieurs règles de parsing
Utilisez le champ Helper Rules afin de définir les tokens pour vos règles de parsing. Les règles d’auxiliaires vous aident à factoriser les patterns Grok dans vos règles de parsing, ce qui est utile lorsque plusieurs règles d’un même parser Grok utilisent les mêmes tokens.
Exemple d’un log non structuré standard :
john id:12345 connected on 11/08/2017 on server XYZ in production
Utilisez la règle de parsing suivante :
MyParsingRule %{user} %{connection} %{server}
Avec les auxiliaires suivants :
user %{word:user.name} id:%{integer:user.id}
connection connected on %{date("MM/dd/yyyy"):connect_date}
server on server %{notSpace:server.name} in %{notSpace:server.env}
Le filtre key/value correspond à keyvalue([separatorStr[, characterWhiteList[, quotingStr[, delimiter]]]]), où :
separatorStr définit le séparateur entre la clé et les valeurs. Par défaut, =.
characterWhiteList définit des caractères supplémentaires non échappés en plus de la valeur par défaut \\w.\\-_@. Uniquement utilisé pour les valeurs sans guillemets (par exemple, key=@valueStr).
quotingStr : définit des guillemets, ce qui remplace la détection de guillemets par défaut : <>, "", ''.
delimiter définit le séparateur entre les différentes paires key/value (par exemple, | est le délimiteur dans key1=value1|key2=value2). Valeur par défaut : (espace normale), , et ;.
Utilisez des filtres tels que keyvalue pour mapper plus facilement des chaînes à des attributs au format keyvalue ou logfmt :
Vous n’avez pas besoin de spécifier le nom de vos paramètres, car ils sont déjà contenus dans le log.
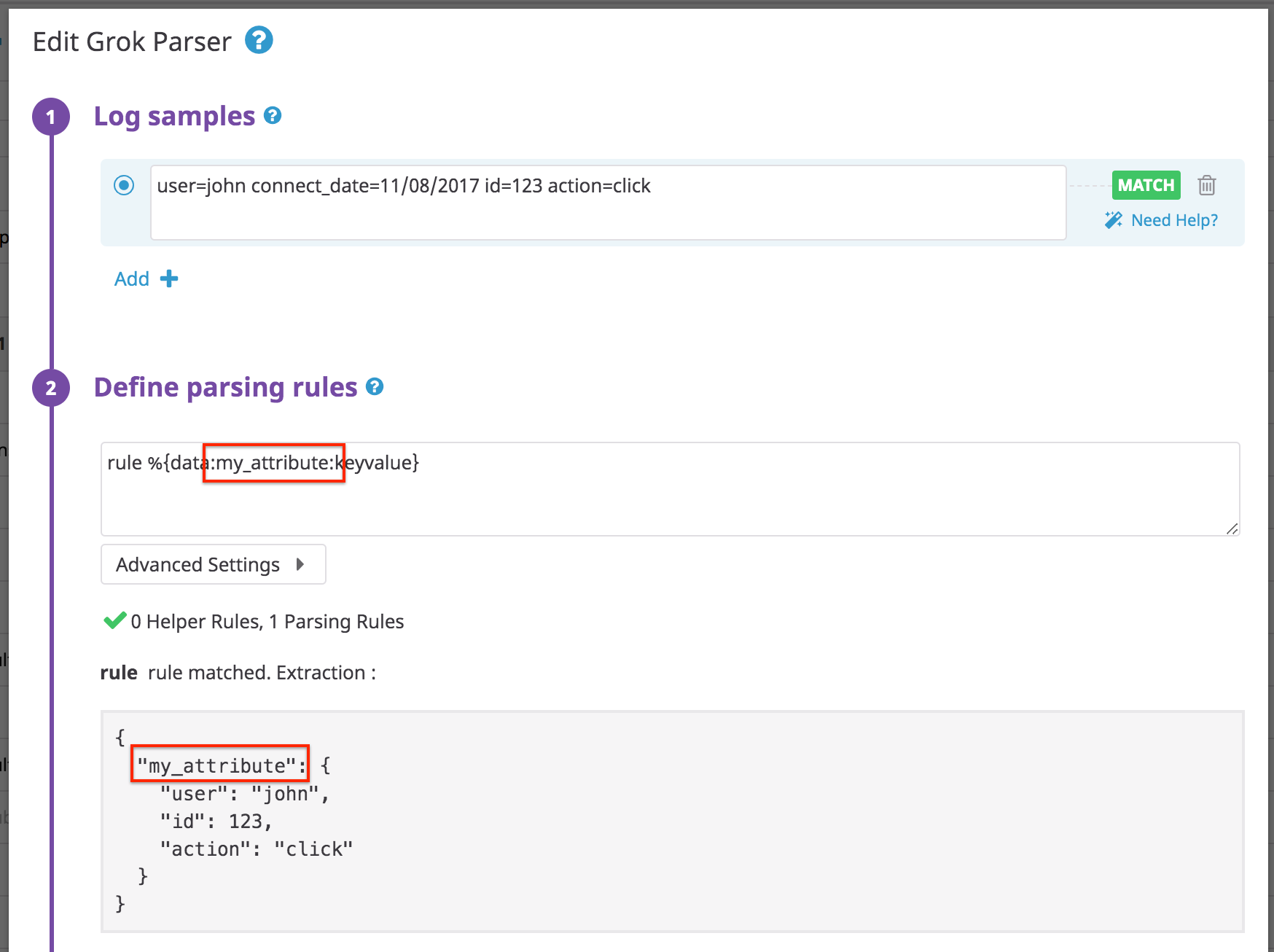
Si vous ajoutez un attribut d’extractionmy_attribute dans votre pattern de règles, vous obtenez :
Si le caractère = n’est pas le séparateur par défaut entre votre clé et vos valeurs, ajoutez à votre règle de parsing un paramètre avec un séparateur.
Log :
user: john connect_date: 11/08/2017 id: 123 action: click
Règle :
rule %{data::keyvalue(": ")}
Si les logs contiennent des caractères spéciaux dans une valeur d’attribut, tels que / dans une URL, ajoutez-les à la liste blanche de la règle de parsing :
Exemple avec plusieurs QuotingString : lorsque plusieurs QuotingString sont définies, le comportement par défaut est ignoré, et seul le guillemet défini est autorisé.
Le filtre key/value met toujours en correspondance des entrées sans guillemet, peu importe la valeur de quotingStr. Lorsque des guillemets sont utilisés, le paramètre characterWhiteList est ignoré, puisque tout le contenu entre les guillemets est extrait.
Les valeurs vides (key=) ou null (key=null) ne sont pas affichées dans la sortie JSON.
Si vous définissez un filtre keyvalue sur un objet data et qu’aucune valeur ne correspond au filtre, un JSON vide {} est renvoyé (par exemple, entrée : key:=valueStr, règle de parsing : rule_test %{data::keyvalue("=")}, sortie : {}).
Si vous définissez "" en tant que quotingStr, la configuration par défaut des guillemets est conservée.
Parser des dates
Le matcher de date convertit votre timestamp au format EPOCH (unité de mesure : millisecondes).
1 Utilisez le paramètre timezone si vous effectuez vos propres localisations et que vos timestamps ne sont pas au fuseau UTC.
Les formats de fuseaux horaires pris en charge sont les suivants :
GMT, UTC, UT ou Z
+h, +hh, +hh:mm, -hh:mm, +hhmm, -hhmm, +hh:mm:ss, -hh:mm:ss, +hhmmss ou -hhmmss. La plage la plus étendue prise en charge est de +18:00 à -18:00 (inclus).
Fuseaux horaires commençant par UTC+, UTC-, GMT+, GMT-, UT+ ou UT-. La plage la plus étendue prise en charge est de +18:00 à -18:00 (inclus).
Les identifiants de fuseaux horaires sont extraits de la base de données TZ. Pour en savoir plus, consultez les noms de la base de données TZ.
Remarque : le parsing d’une date ne définit pas sa valeur comme la date officielle du log. Pour cela, utilisez le remappeur de dates de log dans un processeur ultérieur.
Pattern alternatif
Si vous avez des logs qui se présentent dans deux formats différents, avec un unique attribut comme seule différence, définissez une seule règle en utilisant une alternative avec (<REGEX_1>|<REGEX_2>). Cette règle équivaut à un OR booléen.
Log :
john connected on 11/08/2017
12345 connected on 11/08/2017
Règle :
Notez que « id » est un nombre entier et non une chaîne.
MyParsingRule (%{integer:user.id}|%{word:user.firstname}) connected on %{date("MM/dd/yyyy"):connect_date}
Résultats :
Attribut facultatif
Certains logs contiennent des valeurs qui n’apparaissent que de temps en temps. Dans ce cas, vous pouvez rendre l’extraction d’attributs facultative avec ()?.
Log :
john 1234 connected on 11/08/2017
Règle :
MyParsingRule %{word:user.firstname} (%{integer:user.id} )?connected on %{date("MM/dd/yyyy"):connect_date}
Remarque : la règle ne fonctionnera pas si vous ajoutez une espace après le premier mot dans la section facultative.
JSON imbriqué
Utilisez le filtre json pour effectuer le parsing d’un objet JSON imbriqué après un préfixe en texte brut :
{"level":"W","timestamp":1587728861605,"logger":{"thread_id":1,"name":"authorization.go"},"lineno":47,"msg":"Authorization is disabled"}
Parser du XML
Le parser de XML permet de transformer des messages au format XML en JSON.
Log :
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
</book>
Règle :
rule %{data::xml}
Résultat :
{"book":{"year":"2005","author":"J K. Rowling","category":"CHILDREN","title":{"lang":"en","value":"Harry Potter"}}}
Remarques :
Si le XML contient des tags qui ont à la fois un attribut et une valeur de type chaîne entre les deux tags, un attribut value est généré. Par exemple : <title lang="en">Harry Potter</title> devient {"title": {"lang": "en", "value": "Harry Potter" } }.
Les tags qui se répètent sont automatiquement convertis en tableaux. Par exemple : <bookstore><book>Harry Potter</book><book>Everyday Italian</book></bookstore> devient { "bookstore": { "book": [ "Harry Potter", "Everyday Italian" ] } }
Parser des CSV
Utilisez le filtre CSV pour mapper plus facilement les chaînes de caractères aux attributs lorsqu’elles sont séparées par un caractère donné (, par défaut).
Le filtre CSV correspond à csv(headers[, separator[, quotingcharacter]]), où :
headers définit le nom des clés séparées par ,. Les noms des clés doivent commencer par un caractère alphabétique et peuvent contenir n’importe quel caractère alphanumérique en plus de _.
separator définit le séparateur utilisé pour séparer les différentes valeurs. Seul un caractère est accepté. Valeur par défaut : ,. Remarque : utilisez tab pour représenter le caractère de tabulation.
quotingcharacter définit le caractère des guillemets. Seul un caractère est accepté. Valeur par défaut : ".
Remarques :
Les valeurs contenant un séparateur doivent être entourées de guillemets.
Les valeurs entre guillemets qui contiennent un guillemet doivent être échappées à l’aide de guillemets. Par exemple, dans une valeur entre guillemets, "" représente ".
Si le log ne contient pas le même nombre de valeurs que le nombre de clés dans l’en-tête, le parser CSV se limitera aux premières.
Les entiers et les valeurs doubles sont automatiquement convertis lorsque cela est possible.
Si vos logs contiennent des caractères de contrôle ASCII, ils sont sérialisés lors de l’ingestion. Pour y remédier, échappez explicitement la valeur sérialisée avec votre parser grok.
Pour aller plus loin
Documentation, liens et articles supplémentaires utiles: