検索クエリ
すべての検索パラメーターは、ページの URL に含まれているので、ビューを共有するのに便利です。
検索構文
クエリは条件と演算子で構成されます。
条件には 2 種類あります。
- Span 属性: アプリケーション内で自動または手動のインスツルメントによって収集されたスパンの内容を指します。
- Span タグ: スパンに関連するコンテキスト情報を拡張するためのタグです。例えば、サービスが稼働しているインフラストラクチャーを示すホストやコンテナタグなどが含まれます。
複合クエリで複数の条件を組み合わせるには、以下のブール演算子のいずれかを使用します。
| 演算子 | 説明 | 例 |
|---|
AND | 積: 両方の条件を含むイベントが選択されます (何も追加しなければ、AND がデフォルトで採用されます)。 | authentication AND failure |
OR | 和: いずれかの条件を含むイベントが選択されます。 | authentication OR password |
- | 排他: 後続の条件はイベントに含まれません。 | authentication AND -password |
Attribute 検索
スパン属性を検索するには、属性キーの先頭に @ を追加する必要があります。
例えば、以下の属性を持つスパンにアクセスしたい場合は、次のクエリを使用します:
@git.commit.sha:12345
"git": {
"commit": {
"sha": "12345"
},
"repository": {
"id": "github.com/datadog/datadog"
}
}
スパン属性はトレース サイド パネルの Overview タブに表示されます。
注: 予約属性 (env, operation_name, resource_name, service, status, span_id, timestamp, trace_id, type, link) については、属性キーの先頭に @ を付ける必要はありません。
タグ検索
スパンは、それらを生成するホストやインテグレーションからタグを継承します。
例:
| Query | 一致 |
|---|
(hostname:web-server OR env:prod) | インフラストラクチャー タグ hostname:web-server または予約済み属性 env:prod が付与されたすべてのトレース |
(availability-zone:us-east OR container_name:api-frontend) | これらのインフラストラクチャー タグのいずれかが付与されたすべてのトレース |
(service:api AND -kube_deployment:canary) | api サービスで、canary デプロイメントにデプロイされていないすべてのトレース |
スパン タグはトレース サイド パネルの Infrastructure タブに表示されます。
標準外のタグ形式
もしタグがタグ運用ベストプラクティスに従っていない場合、key:value 形式は使用せず、以下のような検索クエリを利用してください:
tags:<MY_TAG>
例として、次のタグはベスト プラクティスに従っていません:
auto-discovery.cluster-autoscaler.k8s.io/daffy
このタグを検索するには、次のクエリを使用します:
tags:"auto-discovery.cluster-autoscaler.k8s.io/daffy"
ワイルドカード
複数文字のワイルドカード検索を実行するには、* 記号を次のように使用します。
service:web* は、web で始まるサービスを持つすべてのトレースに一致します@url:data* は、data で始まる url を持つすべてのトレースに一致します。
数値
<、>、<=、または >= を使用して、数値属性の検索を実行します。たとえば、100ms を超える応答時間を持つすべてのトレースを取得するには、次のようにします。
@http.response_time:>100
特定の範囲内にある数値属性を検索することもできます。たとえば、4xx エラーをすべて取得するには、次のようにします。
@http.status_code:[400 TO 499]
オートコンプリート
複雑なクエリを入力するのは面倒です。検索バーのオートコンプリート機能を使用すると、既存の値を使用してクエリを完成させることができます。
特殊文字のエスケープ
?、>、<、:、=、"、~、/、および \ は特殊属性と見なされ、\ を使用してエスケープする必要があります。
たとえば、url に user=JaneDoe を含むトレースを検索するには、次の検索を入力する必要があります。
@url:*user\=JaneDoe*
同じロジックはトレース属性内のスペースにも適用する必要があります。トレース属性にスペースを含めることはお勧めしませんが、含まれている場合は、スペースをエスケープする必要があります。
属性の名前が user.first name の場合、スペースをエスケープしてこの属性で検索を実行します。
@user.first\ name:myvalue
検索の保存
同じビューを毎日作成するのは時間の無駄です。保存された検索には、検索クエリ、列、期間が含まれます。検索名やクエリにかかわらず、オートコンプリートの一致により、これは検索バーで利用できます。
保存された検索を削除するには、Trace search ドロップダウンメニューの下にあるごみ箱のアイコンをクリックします。
サービスおよびエンティティの検索
サービスを検索するには、service 属性を使用します。別の エンティティ タイプ (たとえば、データベース、キュー、サード パーティ プロバイダーなど) を検索する場合は、Datadog が APM でインスツルメントされていない依存関係を表すために使用するその他の ピア属性 を利用します。たとえば、Postgres データベースの users テーブルへの呼び出しを表すスパンを見つけるには、次のクエリを使用します: @peer.db.name:users @peer.db.system:postgres
注: グローバルサービスネーミングへ移行し、DD_TRACE_REMOVE_INTEGRATION_SERVICE_NAME_ENABLED=true を設定している場合、スパンの service タグはそのスパンを発行しているサービスを表します。
タイムレンジ
タイムレンジを使用すると、特定の期間内のトレースを表示できます。タイムレンジをすばやく変更するには、プリセットされたレンジをドロップダウンメニューから選択します(または、カスタムタイムフレームを入力します):
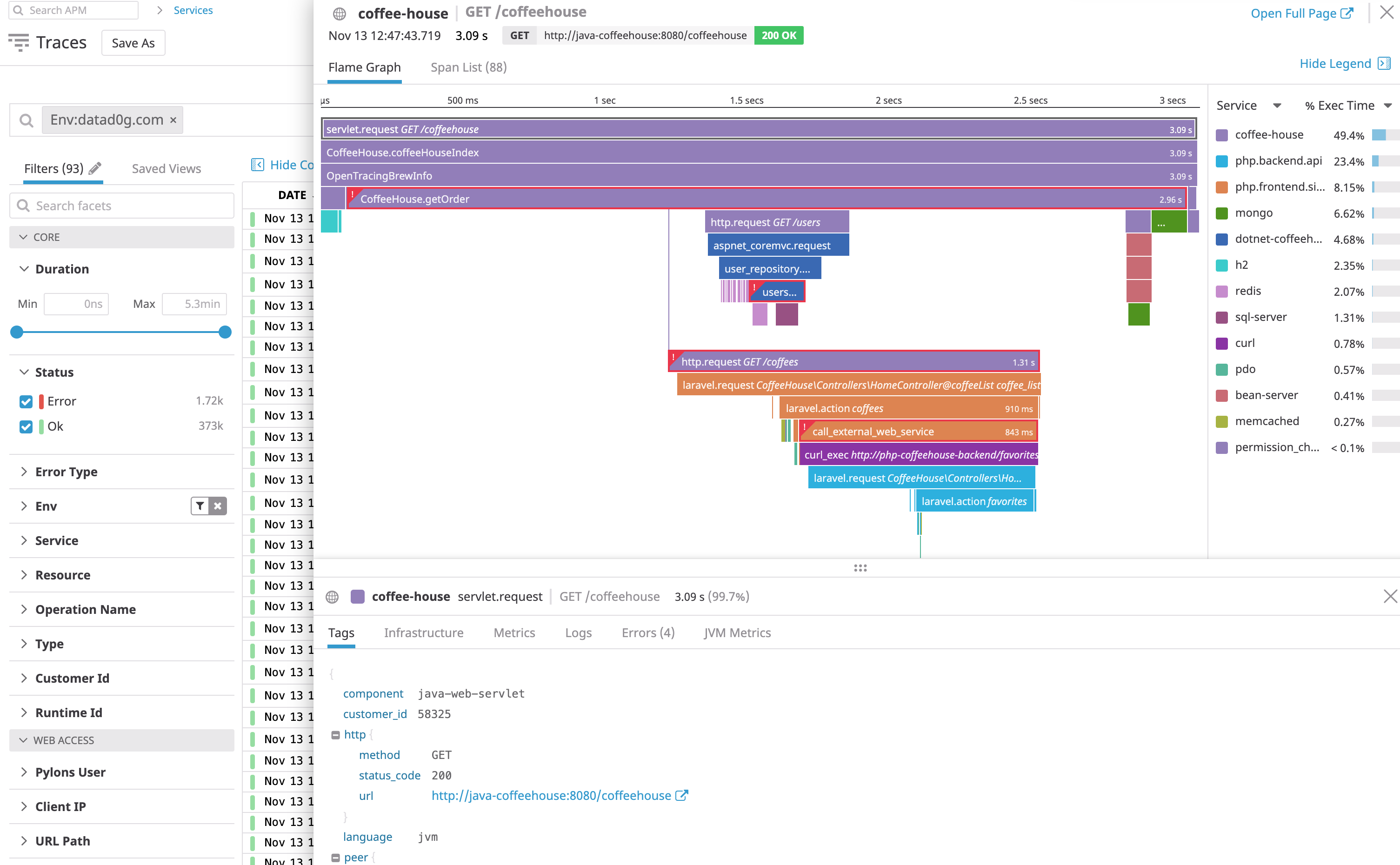
Span テーブル
Span テーブルは、選択されたコンテキスト (検索バーフィルタおよび時間範囲で定義) に一致するスパンの一覧を表示します。
Service 列
デフォルトでは、Service 列はスパンの service 予約属性を表示します。
スパンがインスツルメント済みサービスから推論されたサービスへのクライアント呼び出しを表す場合、Service 列には以下が表示されます。
サービス名がベースサービス名からオーバーライドされている場合、Service 列には以下が表示されます:
完全なトレースの表示
任意のスパンをクリックすると、関連するトレースの詳細を確認できます。
列
リストに他のスパンタグや属性を列として追加するには、Options ボタンをクリックして、追加したい任意のディメンションを選択します。
トレース グループ
任意のスパン タグまたは属性でクエリをグループ化し、リクエスト数、エラー レート、レイテンシー分布をリスト ビューで確認できます。Group by 句では、最大 4 つのディメンションを選択できます。
高度な ‘Group By’ クエリ
グループ化するディメンションを選択した後、from ドロップダウンを使用して、ディメンションの値の取得先を指定できます:
- スパン: クエリ対象のスパンのディメンションでグループ化します (デフォルト)。例:
a。 - スパンの親: クエリに一致するスパンの親スパンから、指定したディメンションの値を取得してグループ化します。たとえば、API エンドポイントのパフォーマンスを呼び出し元のサービスを基準に視覚化するには、
parent(a) から service でグループ化します。 - ルート スパン: トレースのルート スパンから、指定したディメンションでグループ化します。たとえば、リクエストの発生元であるフロントエンド ページを基準にバックエンドのリクエスト パターンを分析するには、
root から @view.name でグループ化します。
グループ リストでトレース グループを表示する
トレース グループは、選択したディメンションの一意の値として表示されます。各グループは、次の 3 つの主要なメトリクスと共に表示されます:
- REQUESTS: グループ内のスパンの数。
- ERRORS: エラー レートとエラー数。
- P95 Latency: スパンの p95 レイテンシー。
これらのメトリクスを、クエリ対象のスパンではなく親スパンまたはルート スパンに集約して表示するには、Show metrics from 文で parent(a) または root を選択します。
また、Latency Breakdown により、各グループからのリクエスト内で、異なるサービス間でどのように時間が費やされるかが表示されるため、指定したグループについてレイテンシーのボトルネックを可視化することができます。
より詳細な分析を行うには、任意のグループをクリックして、集計されたメトリクスを構成する個々のスパン イベントを調べます。
ファセット
ファセットは、1 つの属性またはタグの個別値をすべて表示すると共に、示されたトレースの量などのいくつかの基本分析も提供します。また、データを絞り込むためのスイッチにもなります。
ファセットを使用すると、特定の属性に基づいてデータセットを絞り込んだり、データセットの切り口を変えることができます。ファセットには、ユーザーやサービスなどがあります。
メジャー
メジャー (Measures) は定量的な値に対応する特定のファセットです。
次が必要な場合は、メジャーを使用します。
- 複数のトレースから値を集計する。たとえば、Cassandra の行数にメジャーを作成し、リクエストされたファイルサイズの合計ごとに最上位の参照元または P95 を表示します。
- ショッピングカートの値が $1000 を超えるサービスの最もレイテンシーの高いものを数値的に計算します。
- 連続する値をフィルタリングします。たとえば、ビデオストリームの各ペイロードチャンクのサイズ(バイト単位)。
タイプ
メジャーには、同等の機能のために、(長)整数またはダブル値が付属しています。
単位
メジャーは、クエリ時間と表示時間の桁数を処理するための単位(秒単位の時間またはバイト単位のサイズ)をサポートします。単位は、フィールドではなく、メジャー自体のプロパティです。たとえば、ナノ秒単位の duration メジャーを考えてみます。duration:1000 が 1000 ミリ秒を表す service:A からのスパンタグと、duration:500 が 500 マイクロ秒を表す service:B からの他のスパンタグがあるとします。
算術演算プロセッサーで流入するすべてのスパンタグの期間をナノ秒にスケーリングします。service:A のスパンタグには *1000000 乗数を使用し、service:B のスパンタグには *1000 乗数を使用します。
duration:>20ms(検索構文を参照)を使用して、両方のサービスから一度に一貫してスパンタグにクエリを実行し、最大 1 分の集計結果を確認します。
ファセットの作成
属性をファセットとして使用したり、検索で使用したりするには、属性をクリックしてファセットとして追加します。
新しいファセットを作成すると、フィルタリングや基本分析のために、そのファセットがファセットパネルで利用可能になります。
ファセットパネル
ファセットを使用し、トレースをフィルタリングします。検索バーと URL には、選択内容が自動的に反映されます。
視覚化
分析セレクターを使用して、Analytics の可視化タイプを選択します。
Timeseries
選択したタイムフレーム内での Duration メトリクス(またはファセットのユニーク値数)の動きを可視化し、使用可能なファセットで分割します (オプション) 。
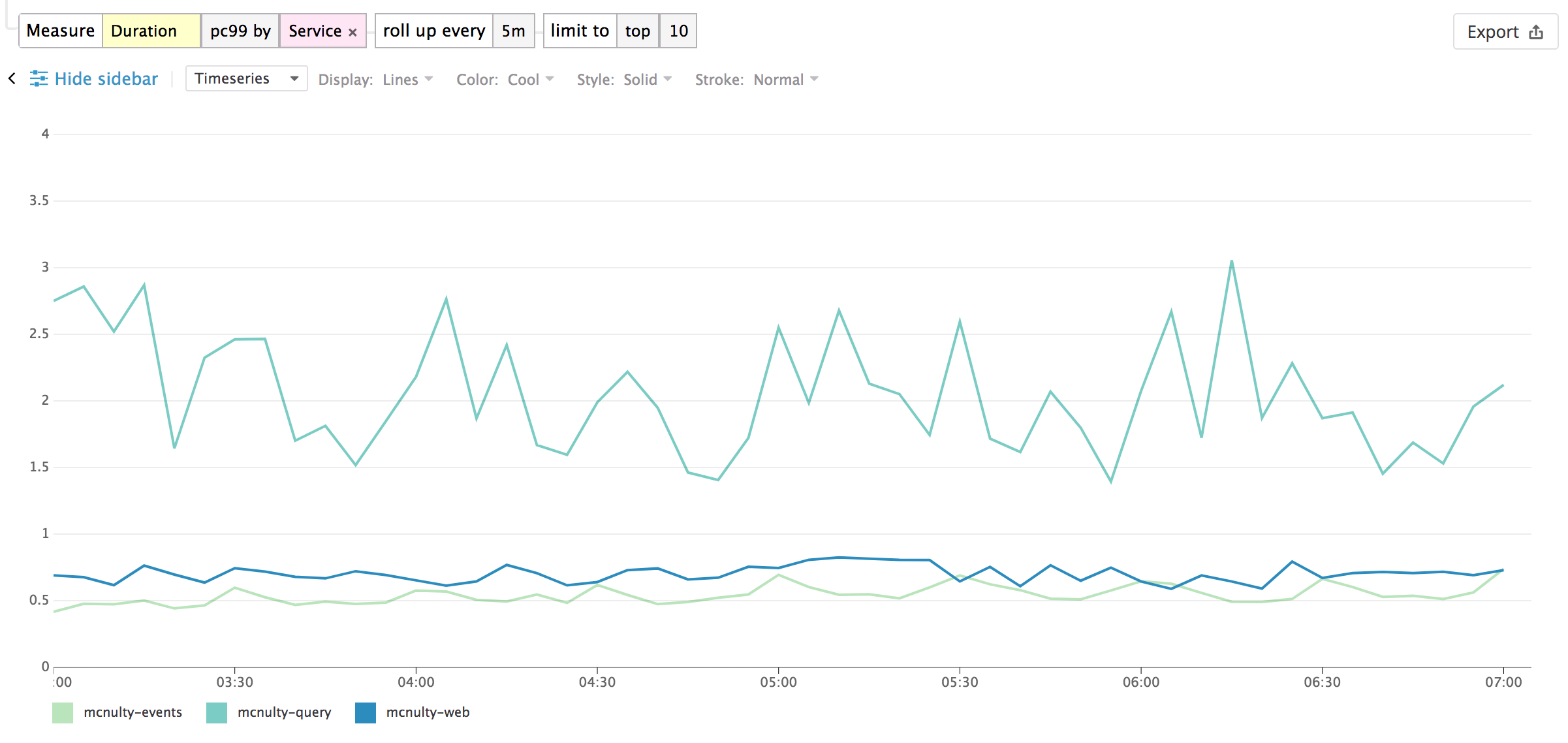
次の時系列 Analytics は、各サービスにおける pc99 の 5 分おきの継続時間の動きを示しています。
Toplist
継続時間(またはファセットのユニーク値数)に基づいて、ファセットの上位の値を可視化します。
以下の Analytics トップリストは、pc99 のサービスの継続時間を上から示しています。
表
選択したメジャー (リストで選択した最初のメジャー) に基づいてファセットから上位の値を可視化し、この上位のリストに現れる要素に対して他のメジャーの値を表示します。検索クエリを更新したり、いずれかのディメンションに対応するログを調査することができます。
- 複数のディメンションがある場合、上位の値は最初のディメンションに基づき決定されます。その後最初のディメンション内の上位値内の 2 番めのディメンション、次に 2 番目のディメンション内の上位値内の 3 番めのディメンションに基づき決定されます。
- メジャーが複数ある場合、最初のメジャーに基づいて上位または下位リストが決定されます。
- サブセット(上位または下位)のみが表示されるため、小計がグループ内の実際の合計値とは異なる場合があります。このディメンジョンに対する、値が null または空欄のイベントは、サブグループとして表示されません。
注: 単一のメジャーと単一のディメンジョンで使用されるテーブルの可視化は、表示が異なりますが、上位リストと同じです。
次のテーブルログ分析は、スループットに基づいて、過去 15 分間の上位ステータスコードの動きをユニーククライアント IP の数と共に示しています。
関連トレース
グラフの一部を選択またはクリックすると、グラフをズームインしたり、選択範囲に対応するトレースのリストを表示したりすることができます。
エクスポート
クエリのエクスポート先:
また、このクエリから新たなメトリクスを生成することも可能です。
注: ダッシュボードおよびノートブック内の APM クエリは、すべてのインデックス化されたスパンに基づきます。一方、モニター内の APM クエリは、カスタム保持フィルターでインデックス化されたスパンにのみ基づきます。
参考資料