Barre de recherche
Tous les paramètres de recherche sont contenus dans l’URL de la page, ce qui permet de partager facilement votre vue.
Syntaxe de recherche
Une requête est composée de termes et d’opérateurs.
Il existe deux types de termes :
Pour combiner plusieurs termes dans une requête complexe, utilisez l’un des opérateurs booléens suivants :
| Opérateur | Description | Exemple |
|---|
AND | Intersection : les deux termes figurent dans les événements sélectionnés (si aucun opérateur n’est ajouté, AND est utilisé par défaut). | authentication AND failure |
OR | Union : un des deux termes figure dans les événements sélectionnés. | authentication OR password |
- | Exclusion : le terme suivant ne figure PAS dans les événements sélectionnés. | authentication AND -password |
Recherche de facettes
Pour effectuer une recherche en fonction d’une facette spécifique, vous devez d’abord l’ajouter comme facette puis utiliser @ pour spécifier que vous faites une recherche à partir d’une facette.
Par exemple, si le nom de votre facette est url et que vous souhaitez filtrer en fonction de la valeur www.datadoghq.com, il vous suffit de saisir :
@url:www.datadoghq.com
Vos traces héritent des tags des hosts et des intégrations qui les génèrent. Elles peuvent être utilisées dans une recherche ainsi que sous la forme de facettes :
| Requête | Résultat |
|---|
("env:prod" OR test) | Toutes les traces avec le tag #env:prod ou le tag #test |
(service:srvA OR service:srvB) ou (service:(srvA OR srvB)) | Toutes les traces qui contiennent les tags #service:srvA ou #service:srvB |
("env:prod" AND -"version:beta") | Toutes les traces qui contiennent #env:prod et qui ne contiennent pas #version:beta |
Si vos tags ne respectent pas les recommandations relatives aux tags et n’utilisent pas la syntaxe key:value, utilisez cette requête de recherche :
Wildcards
Afin d’effectuer une recherche avec un wildcard pour plusieurs caractères, utilisez le symbole * comme illustré ci-dessous :
service:web* renvoie toutes les traces dont le service commence par web.@url:data* renvoie toutes les traces dont le tag url commence par data.
Valeurs numériques
Utilisez les caractères <, >, <= ou >= pour effectuer une recherche avec des attributs numériques. Par exemple, pour récupérer toutes les traces avec un délai de réponse supérieur à 100 ms :
@http.response_time:>100
Vous pouvez également effectuer une recherche d’attribut numérique dans une plage spécifique. Par exemple, pour récupérer toutes les erreurs 4xx :
@http.status_code:[400 TO 499]
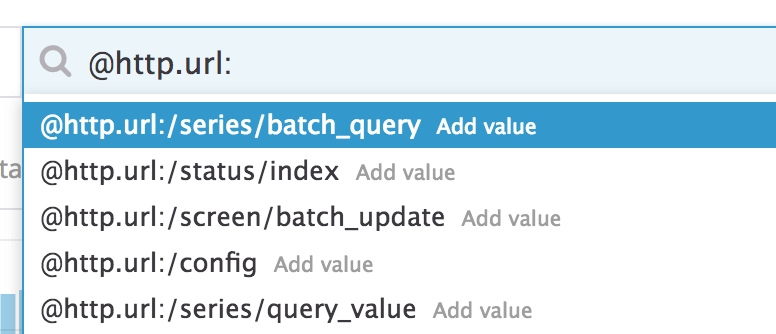
Saisie automatique
La saisie de requête complexe peut être fastidieuse. Utilisez la fonctionnalité de saisie automatique de la barre de recherche pour compléter votre requête en utilisant des valeurs existantes :
Échappement de caractères spéciaux
Les attributs suivants sont considérés comme spéciaux : ?, >, <, :, =,", ~, /, et \. Ils requièrent par conséquent le caractère d’échappement \.
Par exemple, pour rechercher les traces qui contiennent user=AliceMartin dans leur url, saisissez la recherche suivante :
@url:*user\=AliceMartin*
La même logique s’applique aux espaces dans les attributs de trace. Les attributs de trace ne sont pas supposés contenir d’espaces, mais s’ils en ont, les espaces doivent être précédées du caractère d’échappement.
Si un attribut est appelé user.first name, effectuez une recherche sur cet attribut en ajoutant un caractère d’échappement devant l’espace :
@user.first\ name:mavaleur
Recherches enregistrées
Ne perdez pas de temps à créer les mêmes vues tous les jours. Les recherches enregistrées contiennent votre requête de recherche, les colonnes et l’horizon temporel. Pour retrouver une recherche enregistrée, saisissez son nom ou sa requête dans la barre de recherche et utilisez la saisie automatique.
Pour supprimer une recherche enregistrée, cliquez sur l’icône en forme de corbeille sous le menu déroulant de recherche de traces.
Intervalle
L’intervalle vous permet d’afficher les traces correspondant à une période donnée. Changez rapidement l’intervalle en sélectionnant une durée prédéfinie dans la liste déroulante. Vous pouvez également saisir un intervalle personnalisé :
Flux de traces
Le flux de traces regroupe la liste des traces qui correspondent au contexte sélectionné. Un contexte est défini par un filtre dans la barre de recherche et un intervalle.
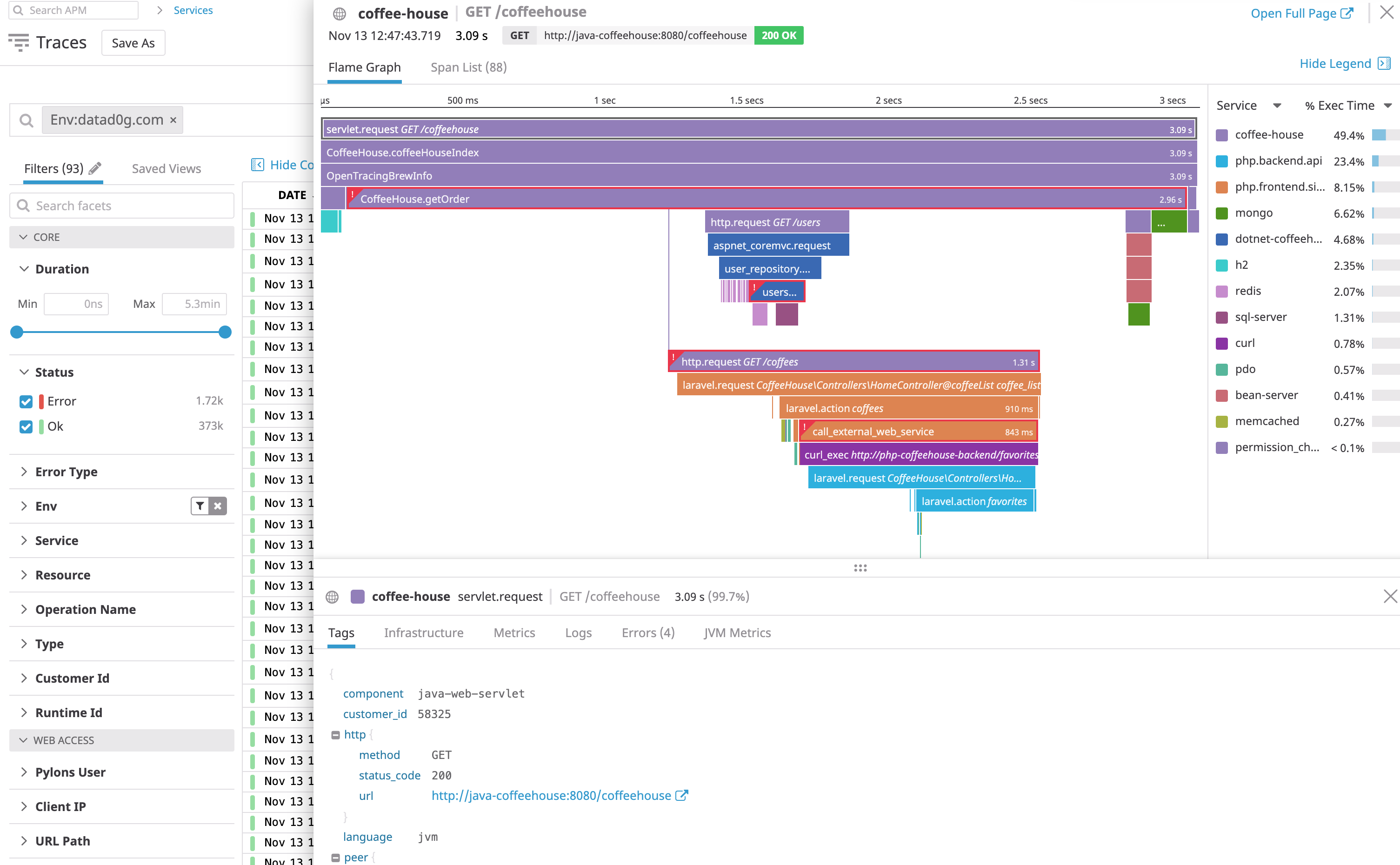
Afficher une trace complète
Cliquez sur une trace pour l’examiner plus en détail :
Colonnes
Pour ajouter plus d’informations de tracing à la liste, cliquez sur le bouton Options et sélectionnez les facettes que vous souhaitez visualiser :
Affichage multiligne
Choisissez d’afficher une, trois ou dix lignes à partir de vos traces. L’affichage de trois et dix lignes vous offre davantage d’informations sur l’attribut error.stack.
Avec une ligne affichée :
Avec trois lignes affichées :
Avec dix lignes affichées :
Facettes
Une facette présente toutes les valeurs distinctes d’un attribut ou d’un tag, en plus de proposer des analyses de base, comme la quantité de traces représentées. Son activation permet également de filtrer vos données.
Les facettes vous permettent de faire pivoter ou de filtrer vos ensembles de données en fonction d’un attribut donné. Les facettes peuvent correspondre à des utilisateurs, des services, etc.
Facettes quantitatives (mesures)
Les mesures vous permettent d’accomplir les tâches suivantes :
- Agréger des valeurs à partir de plusieurs traces. Vous pouvez par exemple créer une mesure sur le nombre de lignes dans Cassandra et visualiser le 95e centile ou les principaux référents selon la somme des tailles de fichiers demandée.
- Calculer les services avec la plus forte latence pour les paniers dépassant 1 000 €.
- Filtrer des valeurs continues, par exemple la taille en octets de chaque bloc de charge utile d’un flux vidéo.
Types
Les mesures disposent d’un nombre entier (long) ou d’une double valeur. Ces deux types de valeurs proposent des fonctionnalités équivalentes.
Unités
Les mesures ont une unité (le temps est exprimé en secondes ou les tailles en octets) afin de gérer les ordres de grandeur au moment de la requête et de l’affichage. L’unité est une propriété de la mesure, et non du champ. Prenons l’exemple d’une mesure « duration » exprimée en nanosecondes. Vous disposez de tags de span du service service:A, pour lesquels duration:1000 désigne la durée 1000 milliseconds, et d’autres tags de span du service service:B, pour lesquels duration:500 désigne la durée de 500 microseconds :
Grâce au processeur arithmétique, vous pouvez faire en sorte que les durées de tous vos tags de span transmis soient exprimées en nanosecondes. Pour ce faire, ajoutez le multiplicateur *1000000 aux tags de span de service:A et le multiplicateur *1000 aux tags de span de service:B.
Appliquez le filtre duration:>20ms (voir la syntaxe de recherche pour en savoir plus) pour interroger systématiquement les tags de span des deux services à la fois et pour afficher un résultat agrégé ayant pour valeur maximale une minute.
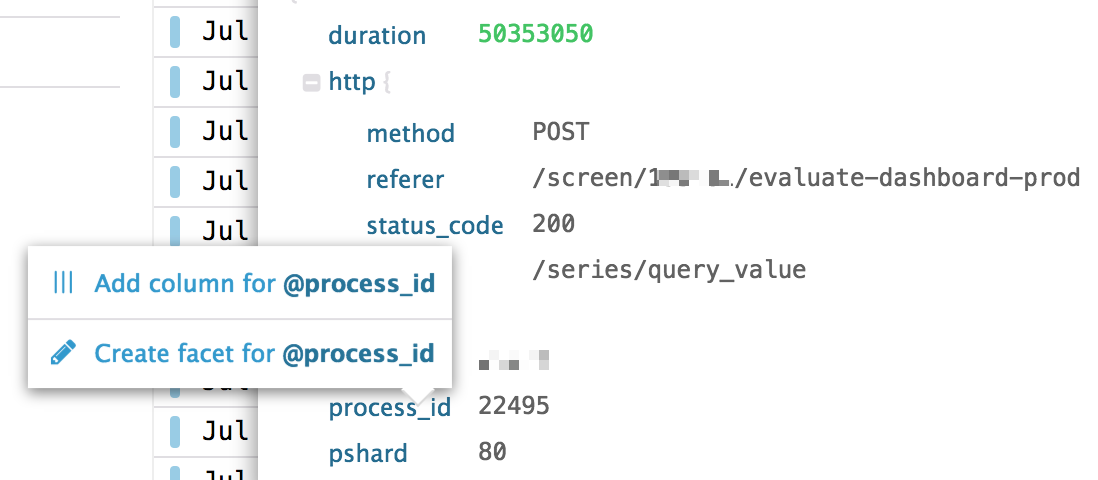
Créer une facette
Pour commencer à utiliser un attribut en tant que facette ou dans une recherche, cliquez dessus et ajoutez-le en tant que facette :
Lorsque vous avez terminé, la valeur de cet attribut est stockée pour toutes les nouvelles traces et peut être utilisée dans la barre de recherche, le volet Facettes et la requête de graphique de trace.
Volet des facettes
Utilisez les facettes pour filtrer vos traces. La barre de recherche et l’URL s’adaptent automatiquement à vos sélections.
Présentation de la fonctionnalité d’analyse
Utilisez les Analyses pour filtrer les métriques de performance des applications et les spans indexées en fonction de tags. Cette fonctionnalité vous permet de plonger au cœur des requêtes Web transitant par votre service.
Les analyses sont automatiquement activées pour tous les services d’APM, avec 100 % de données ingérées pendant 15 minutes (période mobile). Les spans indexées à l’aide de filtres de rétention personnalisés et à l’aide de l’ancien système App Analytics sont disponibles dans les analyses pendant 15 jours.
Les services en aval comme les bases de données et les couches du cache ne font pas partie des services disponibles (car ils ne génèrent pas leurs propres traces), mais les informations les concernant sont récupérées par les services de haut niveau qui les appellent.
Requête d’analyse
Créez une requête pour contrôler les données affichées dans votre analyse :
Choisissez la métrique Duration ou une facette à analyser. La métrique Duration vous permet de choisir la fonction d’agrégation, tandis qu’une facette affiche le nombre de valeurs uniques.
Sélectionnez la fonction d’agrégation pour la métrique Duration :
Utilisez un tag ou une facette pour fractionner votre analyse.
Choisissez d’afficher les X valeurs les plus élevées (top) ou les plus faibles (bottom) en fonction de la facette ou de la Duration sélectionnée.
Sélectionnez les laps de temps de l’analyse.
Le changement de l’intervalle de temps global modifie la liste des laps de temps disponibles.
Visualisations
Sélectionnez un type de visualisation à l’aide du sélecteur d’analyse :
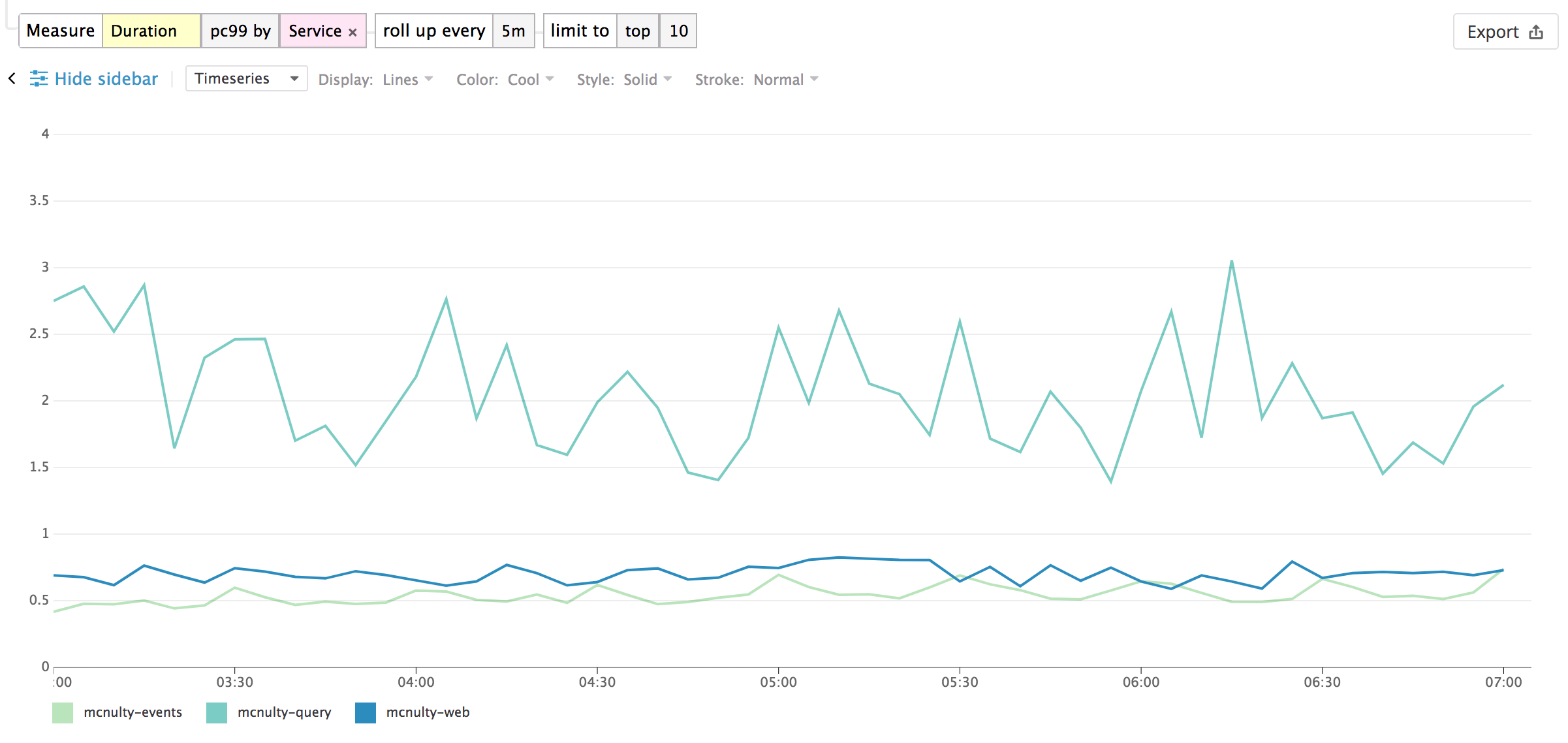
Série temporelle
Visualisez l’évolution de la métrique Duration (ou d’une facette correspondant à un nombre unique de valeurs) pour un intervalle donné. Vous pouvez également fractionner le graphique en utilisant une facette disponible.
L’analyse sous forme de série temporelle suivante illustre l’évolution de la durée au pc99 (99e centile) toutes les 5 minutes pour chaque service :
Top list
Visualisez les valeurs les plus élevées d’une facette en fonction de leur Duration (ou d’une facette correspondant à un nombre unique de valeurs).
L’analyse sous forme de Top List suivante illustre la durée au pc99 (99e centile) la plus élevée d’un service :
Tableau
Visualisez la liste des valeurs les plus élevées d’une facette en fonction de la mesure choisie (la première mesure que vous choisissez dans la liste), et affichez la valeur des autres mesures dans la liste. Mettez à jour la requête de recherche ou étudiez les logs correspondant à l’une des dimensions.
- Lorsque plusieurs dimensions sont définies, les valeurs les plus élevées sont déterminées en fonction de la première dimension, puis de la seconde dans la fourchette des valeurs les plus élevées de la première dimension, puis de la troisième dans la fourchette des valeurs les plus élevées de la seconde dimension.
- Lorsque plusieurs mesures sont définies, les valeurs les plus élevées ou faibles sont déterminées en fonction de la première mesure.
- Le sous-total peut différer de la somme réelle des valeurs au sein d’un groupe, étant donné qu’un seul sous-ensemble (celui des valeurs les plus élevées ou des valeurs les plus faibles) s’affiche. Les événements associés à une valeur nulle ou vide pour cette dimension ne s’affichent pas en tant que sous-groupe.
Remarque : la visualisation d’une seule mesure et d’une seule dimension sous forme de tableau est identique à celle d’une top list. Seule la présentation diffère.
L’analyse de logs sous forme de tableau suivante illustre l’évolution des premiers codes de statut en fonction de leur débit, ainsi que le nombre moyen d’IP client uniques au cours des 15 dernières minutes :
Traces associées
Sélectionnez une section du graphique ou cliquez dessus pour l’agrandir ou consulter la liste des traces correspondant à votre sélection :
Exporter
Exportez votre analyse :
Remarque : l’analyse peut être exportée uniquement lorsqu’elle effectuée sur des spans indexées.
Traces dans les dashboards
Exportez votre analyse depuis la recherche de traces ou créez-en une directement dans votre dashboard aux côtés des métriques et des logs.
En savoir plus sur le widget Série temporelle.
Pour aller plus loin
Documentation, liens et articles supplémentaires utiles: