概要
サービスチェックモニターには、Agent に含まれる 1,000 以上のインテグレーションのいずれかによってレポートされないサービスチェックが含まれます。サービスチェックは、カスタム Agent チェック、DogStatsD、または API を使用して Datadog に送信できます。詳しくは、サービスチェックの概要をご覧ください。
モニターの作成
Datadog でサービスチェックモニターを作成するには、メインナビゲーションを使用して次のように移動します: Monitors –> New Monitor –> Service Check。
サービスチェックを選択する
ドロップダウンメニューからサービスチェックを選択します。
モニターのスコープを選択
ホスト名、タグ、または All Monitored Hosts を選択して、監視するスコープを決定します。特定のホストを除外する必要がある場合は、2 番目のフィールドに名前やタグをリストアップします。
- インクルードフィールドでは
AND ロジックを使用します。ホストに存在するリストアップされたすべてのホスト名とタグはスコープに含まれます。 - エクスクルードフィールドでは
OR ロジックを使用します。リストアップされたホスト名やタグを持つホストはスコープから除外されます。
アラートの条件を設定する
このセクションで、Check Alert または Cluster Alert を選択します。
チェックアラートは、各チェックグループにつき、送信されたステータスを連続的にトラックし、しきい値と比較します。
チェックアラートをセットアップする
チェックレポートを送信する各 <グループ> に対し、アラートを個別にトリガーします。
- チェックグループは既存のグループリストから指定するか、独自に指定します。サービスチェックモニターでは、チェックごとのグループは不明なので、指定する必要があります。
何回連続して失敗したらアラートをトリガーするか、回数 <数値> を選択します。
CRITICAL ステータスが連続して何回送信されたら通知をトリガーするか選択します。たとえば、チェックが失敗したときにすぐに通知するには、1 回のクリティカルステータスでモニターアラートをトリガーします。
Unknown ステータスに対して、Do not notify(通知しない)または Notify(通知する)を選択します。
Notify を選択した場合、UNKNOWN への状態遷移は通知をトリガーします。モニターステータスページでは、UNKNOWN 状態のグループのステータスバーには NODATA のグレーが表示されます。モニターの全体的なステータスは OK のままです。
何回連続して成功したらアラートを解決するか、回数 <数値> を選択します。
- 何回連続して
OK ステータスが送信されたらアラートを解決するか、回数を選択します。たとえば、問題修正を確実にするには、4 回の OK ステータスでモニターを解決します。
クラスターアラートは、既定のステータスでチェックの割合を計算し、しきい値と比較します。
タグの個別の組み合わせでタグ付けされた各チェックは、クラスター内の個別のチェックと見なされます。タグの各組み合わせの最後のチェックのステータスのみが、クラスターのパーセンテージの計算で考慮されます。
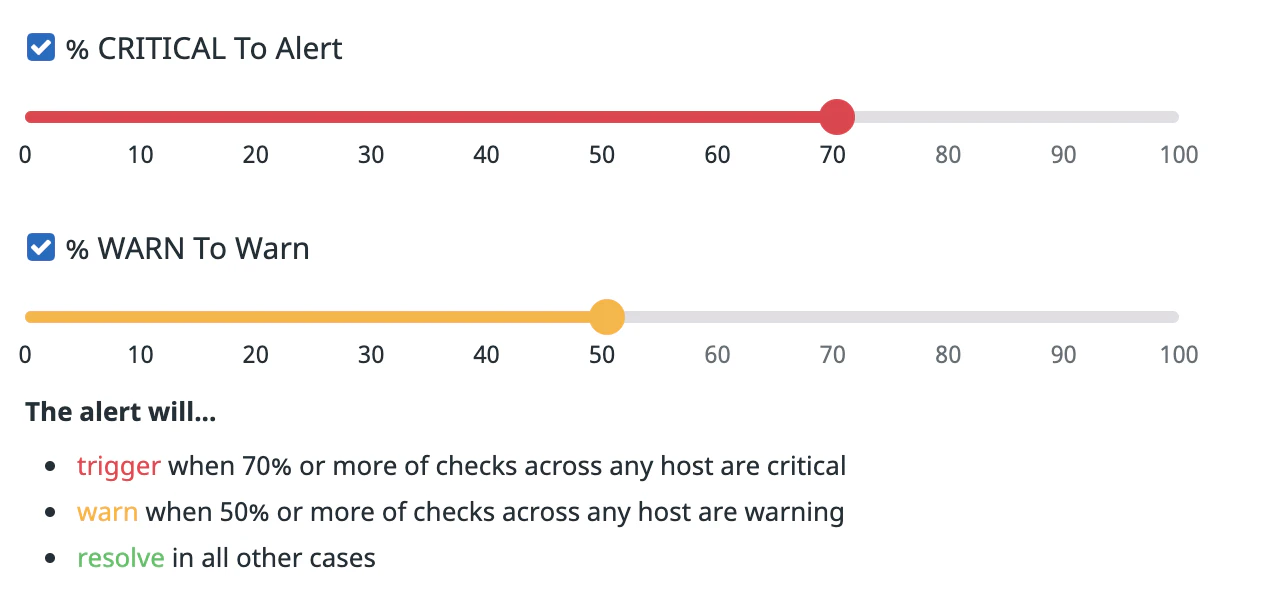
たとえば、環境ごとにグループ化されたクラスターチェックモニターは、いずれかの環境のチェックの 70% 以上が CRITICAL ステータスを送信した場合にアラートし、いずれかの環境のチェックの70% 以上が WARN ステータスを送信した場合に警告できます。
クラスターアラートをセットアップするには
タグによりチェックをグループ化するかどうか決定します。Ungrouped はすべてのソースでステータスのパーセンテージを計算します。Grouped は各グループごとのステータスのパーセンテージを計算します。
アラートと警告のしきい値の割合を選択します。1 つの設定(アラートまたは警告)のみ必須です。
高度なアラート条件
データなし、自動解決、新しいグループ遅延の各オプションに関する情報は、モニターコンフィギュレーションドキュメントを参照してください。
通知
Configure notifications and automations (通知と自動化の構成) セクションの詳しい説明は、通知のページをご覧ください。
その他の参考資料