概要
Datadog では、各メトリクス クエリは既定で 2 つの集計レイヤーで構成されます。ネスト クエリを使うと、先に実行したクエリの結果を後続のクエリで再利用できます。
ネスト クエリを使うことで、次のような強力な機能が利用できるようになります:
マルチ レイヤー集計
Datadog では、各メトリクス クエリは 2 段階の集計で評価されます。まず時間で集計し、続いてタグ単位で集計します。マルチ レイヤー集計を使うと、時間集計またはタグ集計のレイヤーをさらに重ねられます。集計の詳細は、メトリクス クエリの構造 を参照してください。
マルチ レイヤー時間集計
rollup 関数を使うと、マルチ レイヤー時間集計を利用できます。メトリクス クエリには最初から rollup (時間集計) が含まれており、グラフに表示されるデータ ポイントの粒度を制御します。詳しくは、ロールアップ ドキュメントを参照してください。
後続の rollup を重ねることで、時間集計のレイヤーを追加できます。
最初の rollup では、次の集計子を使用できます:
マルチ レイヤー時間集計で追加する後続レイヤーでは、次の時間集計子を使用できます:
avgsumminmaxcountarbitrary percentile pxx (p78, p99, p99.99, etc.)stddev
マルチ レイヤー時間集計は次の関数と組み合わせて使用できます:
| サポートされる関数 | 説明 |
|---|
| 算術演算子 | +, -, *, / |
| Timeshift 関数 | <METRIC_NAME>{*}, -<TIME_IN_SECOND>
hour_before(<METRIC_NAME>{*})
day_before(<METRIC_NAME>{*})
week_before(<METRIC_NAME>{*})
month_before(<METRIC_NAME>{*}) |
| Top-k 選択 | top(<METRIC_NAME>{*}, <LIMIT_TO>, '<BY>', '<DIR>') |
上記に含まれない関数は、マルチ レイヤー時間集計と組み合わせられません。
このクエリではまず、env と team でグループ化した各 EC2 インスタンスの CPU 使用率を平均し、5 分間隔にロールアップします。次にマルチ レイヤー時間集計を適用し、このネスト クエリの結果について 30m 間隔で時間方向の 95 パーセンタイルを算出します。
マルチ レイヤー空間集計
空間集計の 1 つ目のレイヤーでグループ化に使うタグを指定したら、Group By 関数でマルチ レイヤー空間集計を利用できます。
後続の Group By を重ねて、空間集計のレイヤーを追加できます。
注: 最初の空間集計レイヤーでグループ化するタグを指定しない場合、マルチ レイヤー空間集計は利用できません。
空間集計の最初のレイヤーでは、次の集計子をサポートします:
空間集計の追加レイヤーでは、次の集計子をサポートします:
avg bysum bymin bymax byarbitrary percentile pXX (p75, p99, p99.99, etc.)stddev by
マルチ レイヤー空間集計は次の関数と組み合わせて使用できます:
| サポートされる関数 | 説明 |
|---|
| 算術演算子 | +, -, *, / |
| Timeshift 関数 | <METRIC_NAME>{*}, -<TIME_IN_SECOND>
hour_before(<METRIC_NAME>{*})
day_before(<METRIC_NAME>{*})
week_before(<METRIC_NAME>{*})
month_before(<METRIC_NAME>{*}) |
| Top-k 選択 | top(<METRIC_NAME>{*}, <LIMIT_TO>, '<BY>', '<DIR>') |
上記に含まれない関数は、マルチ レイヤー空間集計と組み合わせられません。
パーセンタイルの空間集計子を除き、空間集計子は引数が 1 つで、グループ化に使うタグ キーを指定します。パーセンタイルの空間集計子は 2 つの引数が必要です:
初期クエリ avg:aws.ec2.cpuutilization{*} by {env,host}.rollup(avg, 300) は、env と host でグループ化した CPU 使用率の平均を 5 分ごとに計算します。続いてマルチ レイヤー空間集計を適用し、env ごとに平均 CPU 使用率の最大値を算出します。
UI または JSON タブでは、次のように表示されます:
集計済みの count/rate/gauge に対するパーセンタイルと標準偏差
時間集計と空間集計のマルチ レイヤー集計を使うと、count/rate/gauge のクエリ結果からパーセンタイルや標準偏差を取得できます。大規模データ セットのばらつきや分布をつかみやすくなり、外れ値も見つけやすくなります。
注: ネスト クエリ内のパーセンタイルまたは標準偏差の集計子は、すでに集計された count/rate/gauge メトリクスの結果を使って計算されます。未集計の生データ (raw) からグローバルに正確なパーセンタイルを求めたい場合は、代わりに ディストリビューション メトリクス を使用してください。
マルチ レイヤー時間集計では、パーセンタイルを使ってネスト クエリの結果 (5 分ごとに env と team 別の平均 CPU 使用率) を要約できます。具体的には、このネスト クエリの p95 値を 30 分ごとに計算します。
マルチ レイヤー空間集計では、パーセンタイルを使ってネスト クエリの結果 (5 分ごとに env と team 別の平均 CPU 使用率) を要約できます。具体的には、このネスト クエリの p95 値を、env の各ユニーク値ごとに算出します。
UI または JSON タブでは、次のように表示されます:
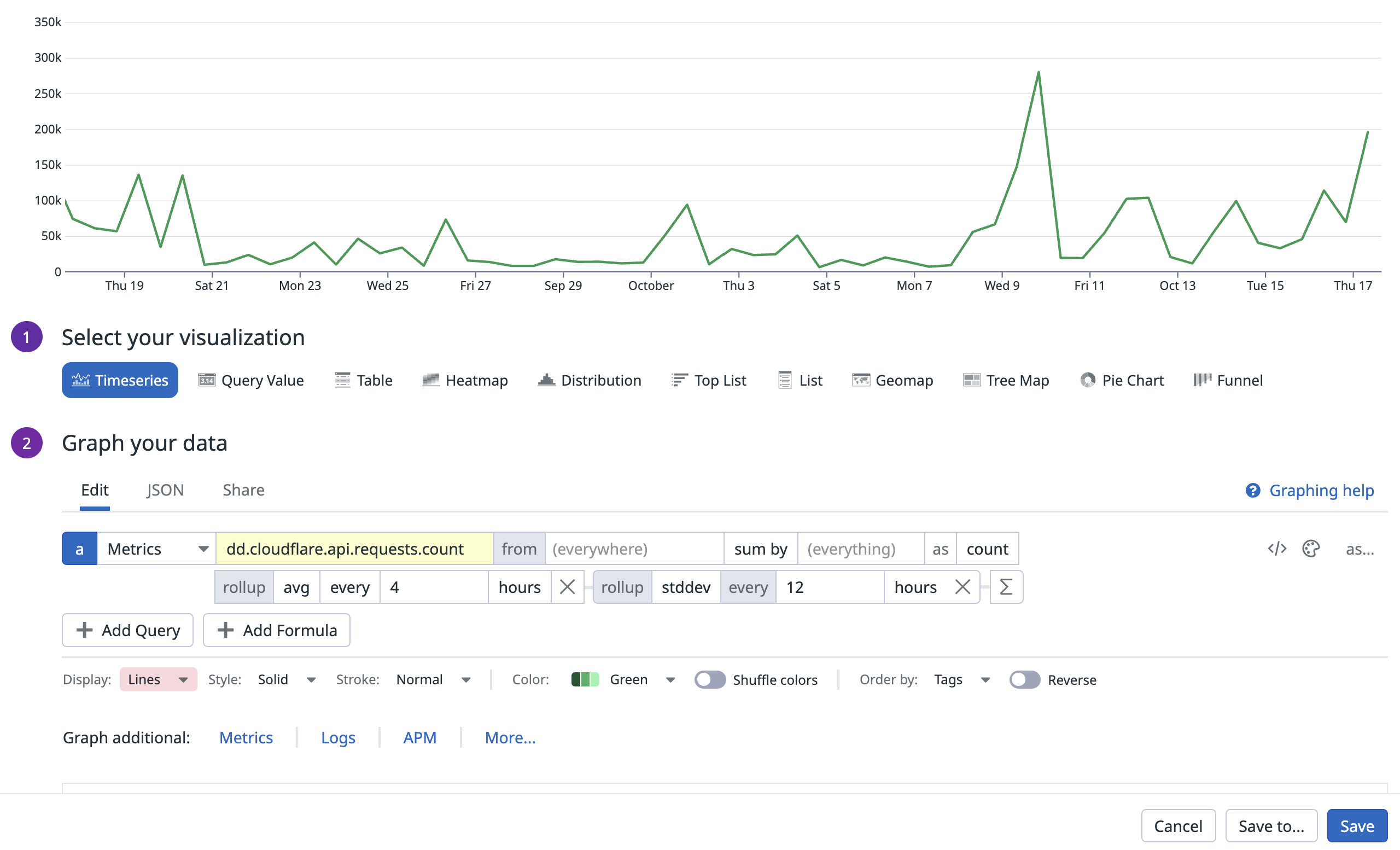
標準偏差は、データ セットのばらつき (散らばり) を測る指標です。次のクエリでは、マルチ レイヤー時間集計で標準偏差を使用し、ネスト クエリ (API リクエスト数の合計を 4 時間で平均化したもの) の標準偏差を、より長い 12 時間区間で計算します:
UI または JSON タブでは、次のように表示されます:
過去の期間に対する高解像度クエリ
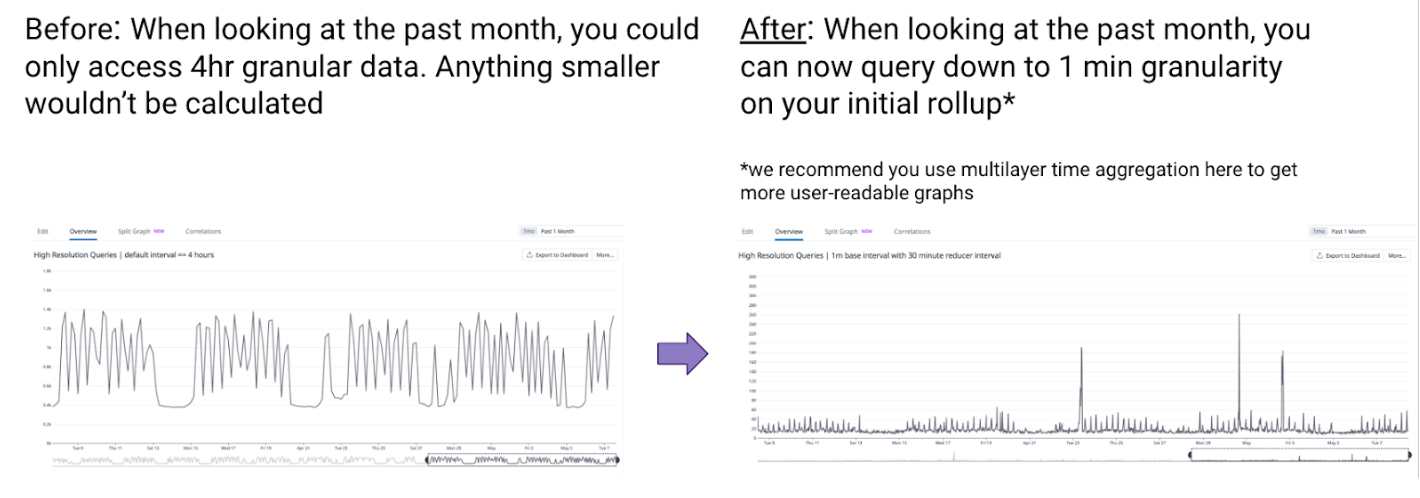
各メトリクス クエリには、表示されるデータ ポイントの粒度を制御する初期の時間集計レイヤー (rollup) が含まれています。Datadog では、クエリ対象期間が長くなるほど既定の rollup 間隔も粗くなるように設計されています。ネスト クエリを使えば、長い過去期間でもより細かな高解像度データにアクセスできます。
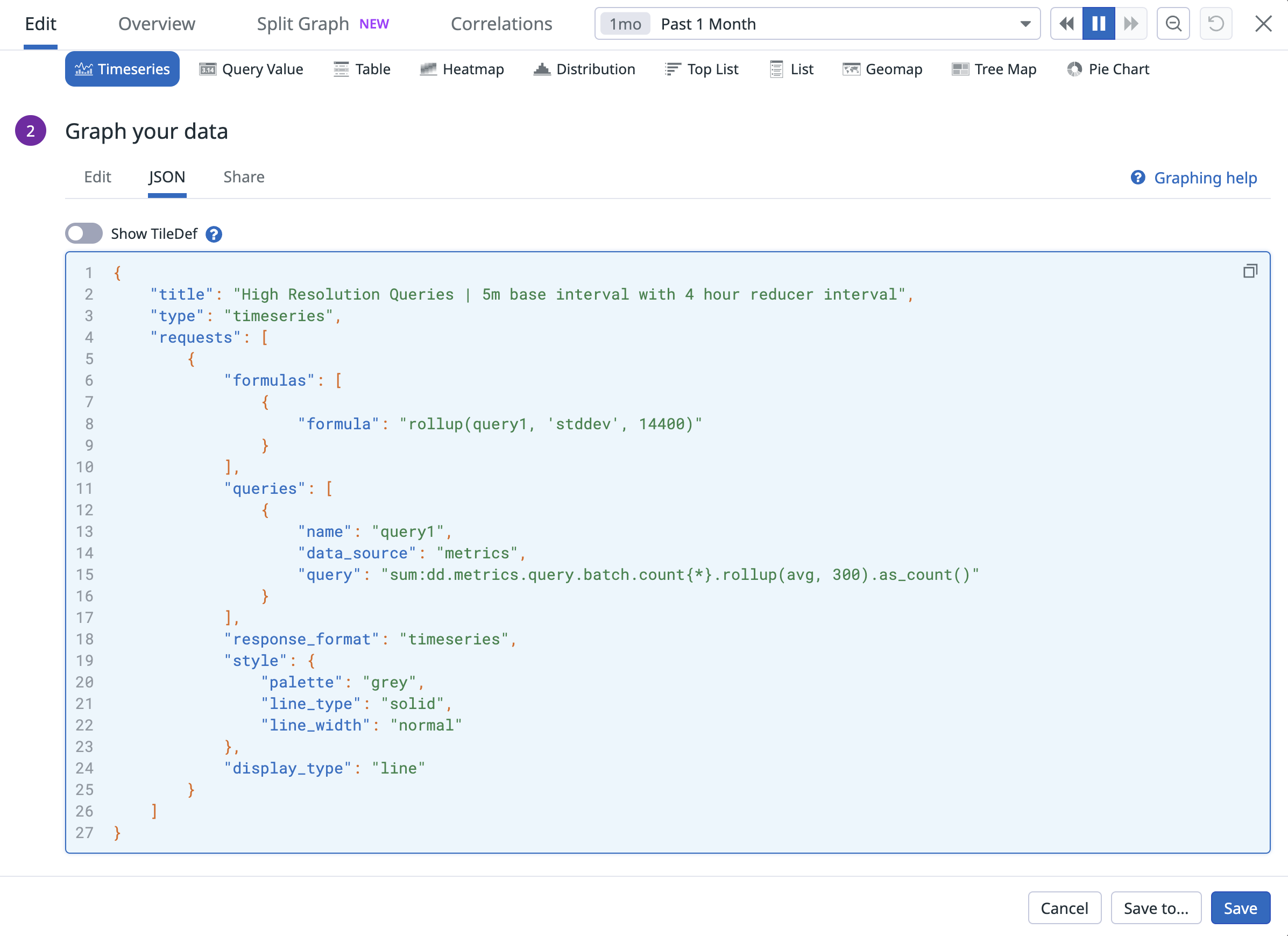
従来は、過去 1 か月のメトリクスをクエリすると、既定で 4 時間粒度のデータが表示されていました。ネスト クエリを使うと、この過去期間でもより細かな粒度のデータを参照できます。以下は過去 1 か月を対象にした例です。まずクエリ バッチ カウントを 5 分間隔で rollup し、その後マルチ レイヤー時間集計を適用して、このネスト クエリの時間方向の標準偏差を 4 時間区間で算出します。こうすることで、より人が読み取りやすいグラフにできます。
注: Datadog では、最初の rollup はできるだけ細かい間隔で定義し、その後により粗い rollup 間隔のマルチ レイヤー時間集計を使って、読みやすいグラフに整えることを推奨しています。
UI または JSON タブでは、次のように表示されます:
moving rollup
Datadog には、指定した時間ウィンドウでデータ ポイントを集計できる moving_rollup 関数があります。詳しくは moving rollup を参照してください。ネスト クエリを使うと、この関数を拡張して lookback モードを取り込み、元のクエリ ウィンドウを超えるデータ ポイントも分析できるようになります。これにより、指定した時間ウィンドウにおけるクエリの傾向やパターンを、より包括的に把握できます。
既存の moving_rollup 関数がサポートする集計子は次のとおりです:
クエリをネストする場合、利用できるのは lookback モード版の moving_rollup 関数のみです。このバージョンでは次の集計子をサポートします:
avgsumminmaxcountcount byarbitrary percentile pxx (p78, p99, p99.99, etc.)stddev
これらの moving_rollups をネストする場合、指定する rollup 間隔は UI または JSON タブに示すとおり段階的に大きくする必要があります:
lookback をサポートする新しい moving rollup 関数では、パーセンタイルや標準偏差も利用できます。また、lookback を有効にした moving rollup のネストも行えます。
UI または JSON タブでは、次のように表示されます:
ブール値しきい値のリマップ関数
リマップ関数を使うと、特定の条件に基づいてクエリ結果を絞り込んだり変換したりでき、監視や分析の幅を広げられます。ネスト クエリにより、次の 3 つの新しい関数が利用できるようになります:
is_greater (<QUERY>, <THRESHOLD>)is_less (<QUERY>, <THRESHOLD>)is_between (<QUERY>, <LOWER THRESHOLD>, <UPPER THRESHOLD>)
is_greater() は、クエリの値が定数 30 を上回るポイントでは 1.0 を返し、それ以外は 0.0 を返します。
UI または JSON タブでは、次のように表示されます:
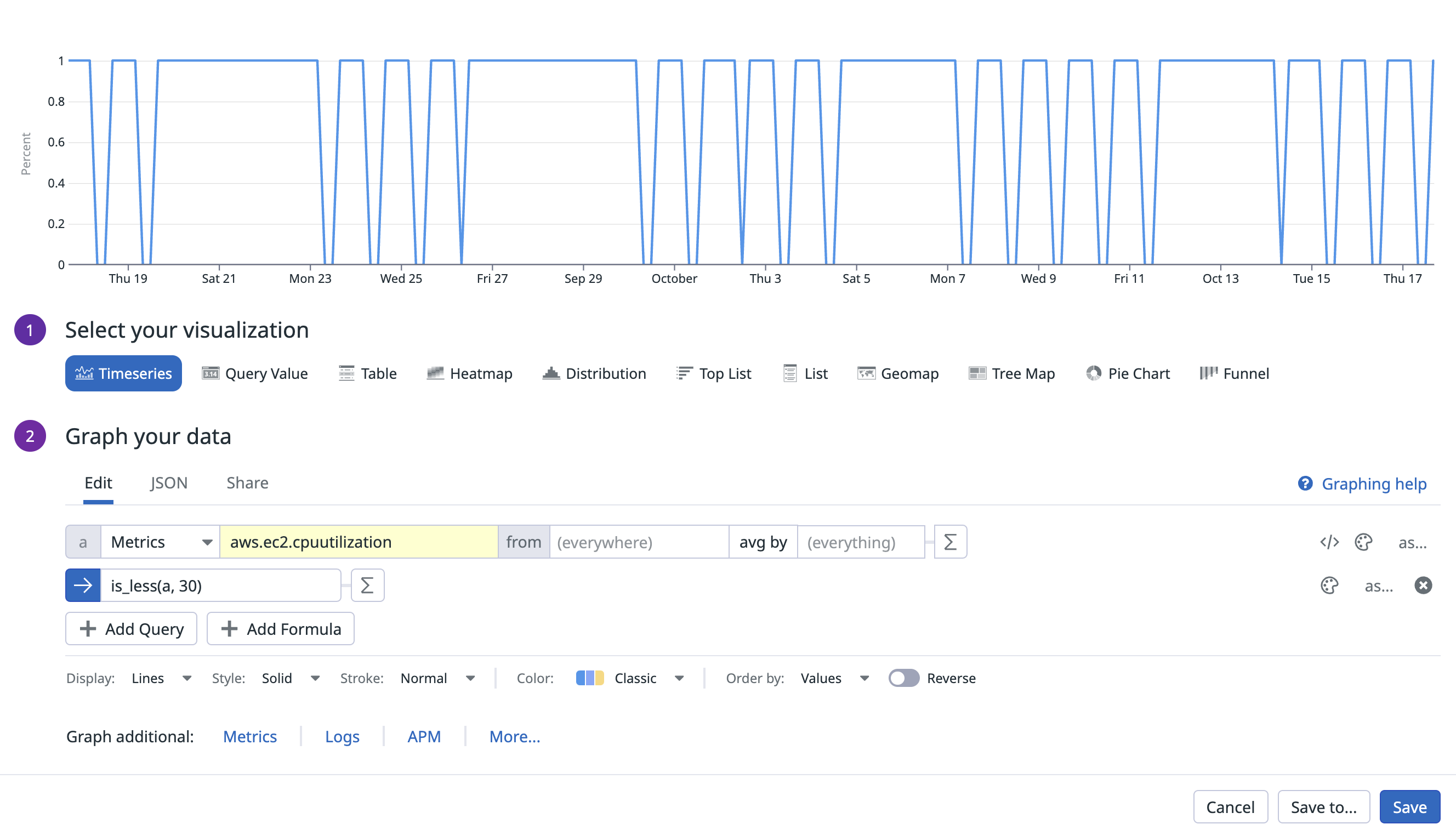
is_less() は、クエリの値が定数 30 を下回るポイントでは 1.0 を返し、それ以外は 0.0 を返します。
UI または JSON タブでは、次のように表示されます:
is_between() は、クエリの値が 10 と 30 の間 (端点は含まない) のポイントでは 1.0 を返し、それ以外は 0.0 を返します。
UI または JSON タブでは、次のように表示されます:
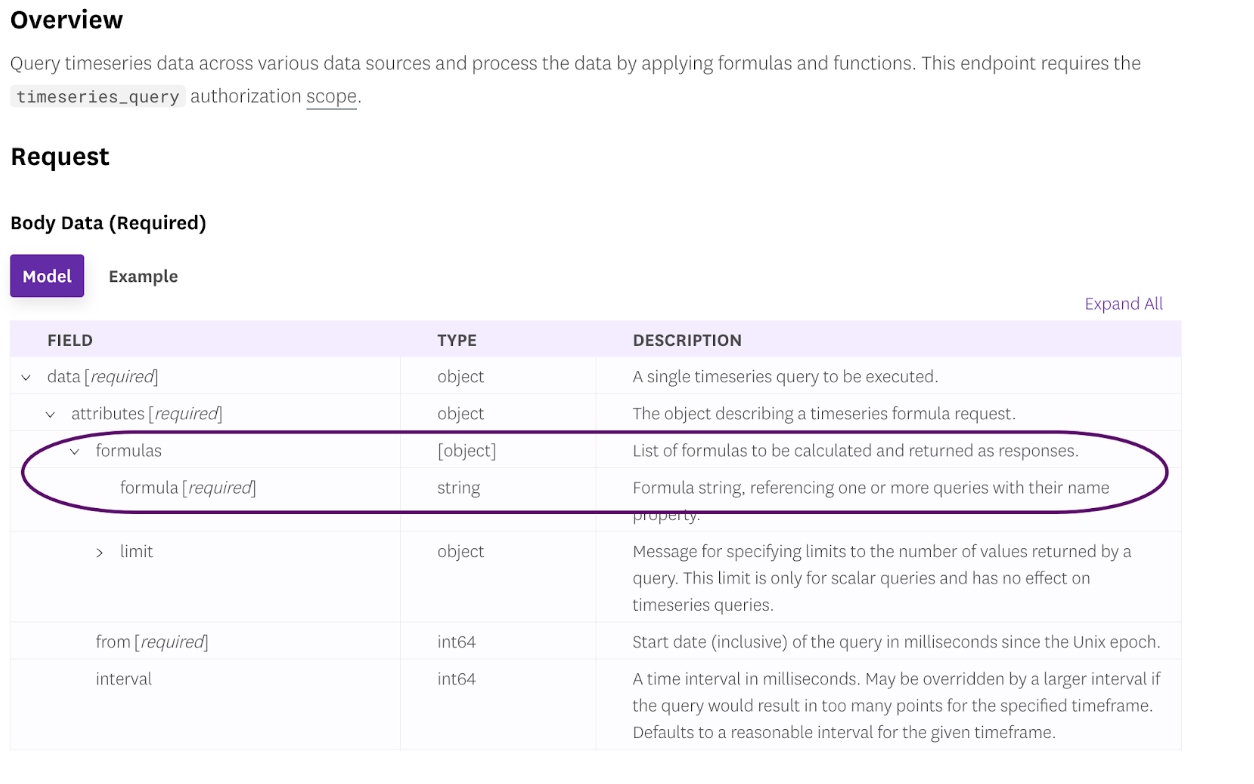
Datadog の API でネスト クエリを使用する
ネスト クエリの機能は、時系列データをクエリするための公開 API でも利用できます。formula オブジェクトの内容を変更してください。
参考資料