ラーニングセンターで Grok パースを試してみましょう ログパイプラインの構築と変更を行い、Pipeline Scanner で管理し、処理されたログ全体で属性名を統一して一貫性を持たせる方法を学びましょう。
今すぐ登録 概要 Datadog は JSON 形式のログを自動的にパースしますが、その他の形式の場合は、Grok パーサーを利用してログを補完できます。
Grok 構文は、標準の正規表現より簡単にログをパースする方法を提供します。Grok パーサーにより、半構造化されたテキストメッセージから属性を抽出できます。
Grok には、整数、IP アドレス、ホスト名などをパースするための再利用可能なパターンが付属しています。これらの値は文字列として grok パーサーに送られなければなりません。
パース規則は、%{MATCHER:EXTRACT:FILTER} 構文を使用して記述できます。
Matcher : 期待する内容 (数値、単語、スペース以外など) を記述する規則 (または別のトークン規則への参照)。
Extract (任意): Matcher と一致するテキストをキャプチャする対象を表す識別子。
Filter (任意): 一致したテキストを変換するためのポストプロセッサー。
典型的な非構造化ログの例
john connected on 11/08/2017
これに次のパース規則を使用します。
MyParsingRule %{word:user} connected on %{date("MM/dd/yyyy"):date}
処理後は、次のような構造化ログが生成されます。
注 :
1 つの Grok パーサーに複数のパース規則がある場合特定のログに一致する規則は 1 つだけです。上から下へ参照し、最初に一致した規則がパースを行う規則になります。 各規則は上記のリストに定義されたパースを参照します。 同一の Grok パーサー内では同じ規則名を複数使用できません。 規則名には英数字、アンダースコア (_)、ピリオド (.) のみ使用できます。最初の文字は英数字でなければなりません。 値が null または空欄のプロパティは表示されません。 正規表現マッチャーは、文字列の先頭に一致するように暗黙の ^ を適用し、文字列の末尾に一致するように $ を適用します。 特定のログは、空白の大きなギャップを生成する可能性があります。改行と空白を表すには、\n と \s+ を使用します。 マッチャーとフィルター 以下に、Datadog でネイティブに実装されるすべてのマッチャーとフィルターを示します。
date("pattern"[, "timezoneId"[, "localeId"]])指定されたパターンを持つ日付に一致してパースし、Unix タイムスタンプを生成します。日付マッチャーの例を参照してください 。 regex("pattern")正規表現に一致します。正規表現マッチャーの例を参照してください 。 notSpace次のスペースまでの文字列に一致します。 boolean("truePattern", "falsePattern")ブール値に一致してパースします。true と false のパターンをオプションで定義できます (デフォルトは ’true’ と ‘false’。大文字と小文字は区別されません)。 numberStr10 進浮動小数点数に一致し、それを文字列としてパースします。 number10 進浮動小数点数に一致し、それを倍精度数としてパースします。 numberExtStr(指数表記の) 浮動小数点数に一致し、それを文字列としてパースします。 numberExt(指数表記の) 浮動小数点数に一致し、それを倍精度数としてパースします。 integerStr整数に一致し、それを文字列としてパースします。 integer整数に一致し、それを整数としてパースします。 integerExtStr(指数表記の) 整数に一致し、それを文字列としてパースします。 integerExt(指数表記の) 整数に一致し、それを整数としてパースします。 word単語境界で始まり、a-z、A-Z、0-9 の文字と _ (アンダースコア) 文字を含み、単語境界で終わる単語にマッチします。正規表現では \b\w+\b に相当します。 doubleQuotedString二重引用符で囲まれた文字列に一致します。 singleQuotedString単一引用符で囲まれた文字列に一致します。 quotedString二重引用符または単一引用符で囲まれた文字列に一致します。 uuidUUID に一致します。 macMAC アドレスに一致します。 ipv4IPV4 に一致します。 ipv6IPV6 に一致します。 ipIP (v4 または v6) に一致します。 hostnameホスト名に一致します。 ipOrHostホスト名または IP に一致します。 portポート番号に一致します。 dataスペースと改行を含め、任意の文字列に一致します。正規表現の .* と同じです。上記のいずれのパターンも適切でない場合に使用します。 number一致部分を倍精度数としてパースします。 integer一致部分を整数としてパースします。 boolean大文字と小文字を区別しないで、’true’ および ‘false’ 文字列をブール値としてパースします。 nullIf("value")一致部分が指定された値に等しい場合は null を返します。 json適切な形式の JSON をパースします。 rubyhash適切な形式の Ruby ハッシュをパースします (例: {name => "John", "job" => {"company" => "Big Company", "title" => "CTO"}})。 useragent([decodeuricomponent:true/false])User-Agent をパースして、Agent によって表されるデバイス、OS、ブラウザを含む JSON オブジェクトを返します。ユーザーエージェントプロセッサーを参照してください 。 querystring一致する URL クエリ文字列内のすべての key-value ペアを抽出します (例: ?productId=superproduct&promotionCode=superpromo)。 decodeuricomponentURI コンポーネントをデコードします。たとえば、’%2Fservice%2Ftest’ は ‘/service/test’ に変換されます。 lowercase小文字に変換した文字列を返します。 uppercase大文字に変換した文字列を返します。 keyvalue([separatorStr[, characterAllowList[, quotingStr[, delimiter]]]])キー値のパターンを抽出し、JSON オブジェクトを返します。キー値フィルターの例 を参照してください。 xml適切にフォーマット化された XML をパースします。XML フィルターの例 を参照してください。 csv(headers[, separator[, quotingcharacter]])適切にフォーマット化された CSV または TSV の行をパースします。[CSV フィルターの例](#CSV をパースする)を参照してください。 scale(factor)抽出された数値を指定された factor で乗算します。 array([[openCloseStr, ] separator][, subRuleOrFilter)文字列トークンシーケンスをパースして配列として返します。配列へのリスト の例を参照してください。 urlURL をパースし、トークン化されたすべてのメンバー (ドメイン、クエリパラメーター、ポートなど) を 1 つの JSON オブジェクトとして返します。URL のパース方法を参照してください 。 高度な設定 Grok プロセッサータイルの下部に、Advanced Settings セクションがあります。
特定のテキスト属性をパース Extract from フィールドを使用して、デフォルトの message 属性ではなく、指定されたテキスト属性に Grok プロセッサを適用します。
たとえば、key-value としてパースされる必要のある command.line 属性を持つログを例に取ると、そのログは以下のようにパースできます。
ヘルパー規則を使用して複数のパース規則を再利用する パース規則に使用するトークンを定義するには、Helper Rules フィールドを使用します。Helper Rules を使用すると、Grok パターンを複数のパース規則で再利用でき、同じ Grok パーサーの複数の規則で同じトークンを使用する場合に便利です。
典型的な非構造化ログの例
john id:12345 connected on 11/08/2017 on server XYZ in production
次のパース規則を使用します。
MyParsingRule %{user} %{connection} %{server}
次のヘルパーと組み合わせます。
user %{word:user.name} id:%{integer:user.id}
connection connected on %{date("MM/dd/yyyy"):connect_date}
server on server %{notSpace:server.name} in %{notSpace:server.env}
例 以下に、パーサーの具体的な使用例をいくつか挙げます。
キー値または logfmt これは key-value コアフィルター keyvalue([separatorStr[, characterAllowList[, quotingStr[, delimiter]]]]) です。
separatorStr: キーと値を区切るセパレーターを定義します。デフォルト =.characterAllowList: デフォルトの \\w.\\-_@ に加え、追加の非エスケープ値文字を定義します。引用符で囲まれていない値 (例: key=@valueStr) にのみ使用します。quotingStr: 引用符を定義し、デフォルトの引用符検出(<>、""、'')を置き換えます。delimiter: 異なる key-value ペアのセパレーターを定義します(すなわち、| は key1=value1|key2=value2の区切り文字です)。デフォルトは , および ; です。keyvalue などのフィルターを使用すると、keyvalue または logfmt 形式の属性に文字列をより簡単にマップできます。
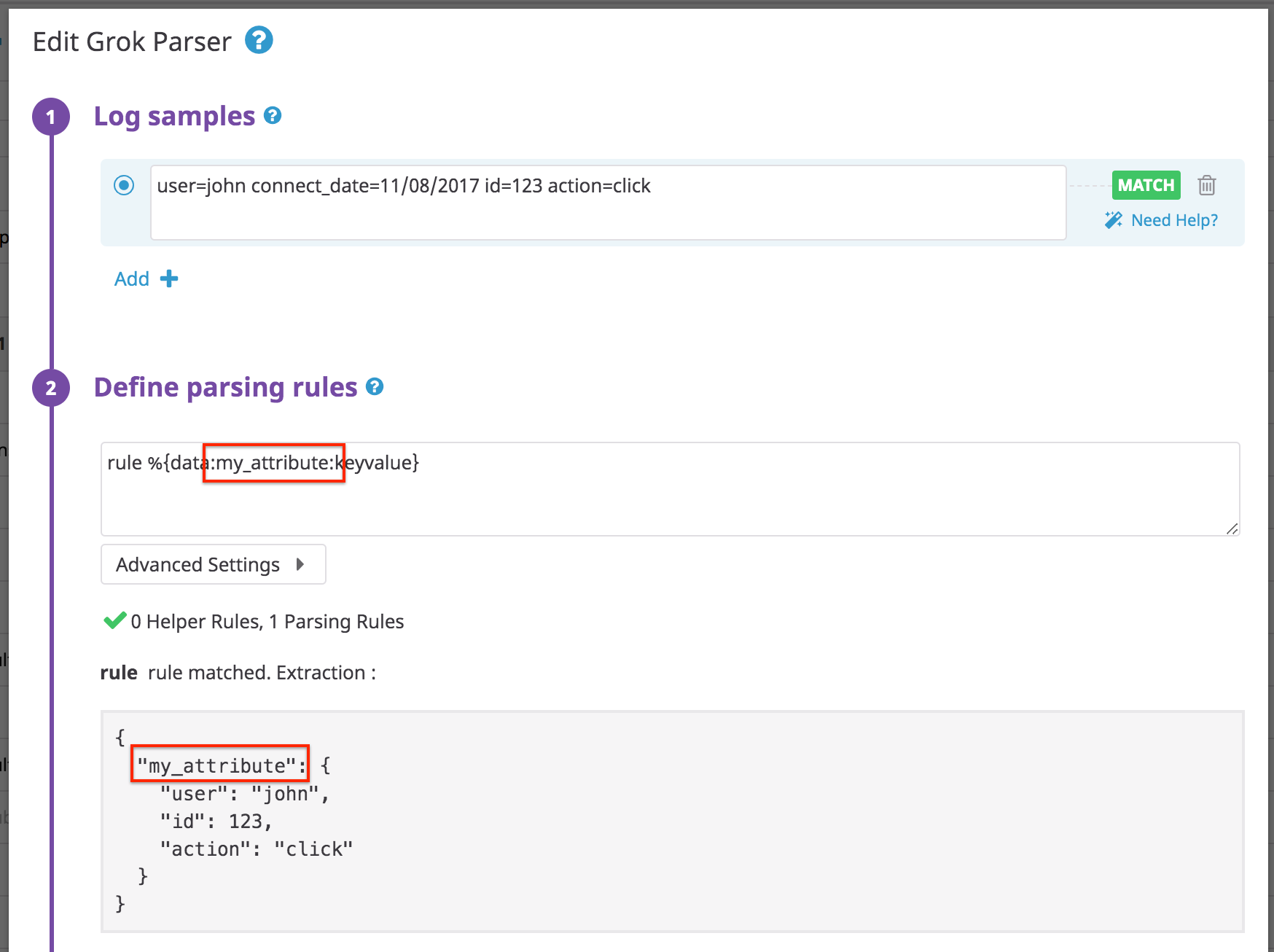
ログ:
user=john connect_date=11/08/2017 id=123 action=click
例:
パラメーターの名前はログに既に含まれているため、指定する必要はありません。
extract 属性 my_attribute を規則パターンに追加すると、次のようになります。
キーと値を区切るデフォルトのセパレーターが = 以外の場合は、セパレーターとともにパラメーターをパース規則に追加します。
ログ:
user: john connect_date: 11/08/2017 id: 123 action: click
例:
rule %{data::keyvalue(": ")}
ログの属性値に、URL の / などの特殊文字が含まれる場合は、それをパース規則の許可リストに追加します。
ログ:
url=https://app.datadoghq.com/event/stream user=john
例:
rule %{data::keyvalue("=","/:")}
その他の例
文字列の例 パース規則 結果 key=valueStr %{data::keyvalue}{“key”: “valueStr”} key=<valueStr> %{data::keyvalue}{“key”: “valueStr”} “key”=“valueStr” %{data::keyvalue}{“key”: “valueStr”} key:valueStr %{data::keyvalue(":")}{“key”: “valueStr”} key:"/valueStr" %{data::keyvalue(":", "/")}{“key”: “/valueStr”} /key:/valueStr %{data::keyvalue(":", "/")}{"/key": “/valueStr”} key:={valueStr} %{data::keyvalue(":=", "", "{}")}{“key”: “valueStr”} key1=value1|key2=value2 %{data::keyvalue("=", "", "", "|")}{“key1”: “value1”, “key2”: “value2”} key1=“value1”|key2=“value2” %{data::keyvalue("=", "", "", "|")}{“key1”: “value1”, “key2”: “value2”}
Multiple QuotingString の例 : 複数の引用文字列が定義されると、デフォルトの挙動が定義された引用文字に置き換えられます。
quotingStr で指定されている値にかかわらず、キーと値は引用文字列が使用されていなくても常に入力と一致します。 引用文字列が使用されている場合、引用符内の文字列がすべて抽出されるため、characterAllowList は無視されます。
ログ:
key1:=valueStr key2:=</valueStr2> key3:="valueStr3"
例:
rule %{data::keyvalue(":=","","<>")}
結果:
{ "key1" : "valueStr" , "key2" : "/valueStr2" }
注 :
値が空 (key=) または null (key=null) の場合、出力される JSON に表示されません。 data オブジェクトで keyvalue フィルターを定義する場合で、このフィルターが一致しない時は、空の JSON {} が返されます (例: 入力: key:=valueStr、パース規則: rule_test %{data::keyvalue("=")}、出力: {})。"" を quotingStr と定義すると、引用符のデフォルト設定が保持されます。日付のパース 日付マッチャーは、タイムスタンプを EPOCH 形式 (millisecond 計測単位) に変換します。
文字列の例 パース規則 結果 14:20:15 %{date("HH:mm:ss"):date}{“date”: 51615000} 02:20:15 PM %{date("hh:mm:ss a"):date}{“date”: 51615000} 11/10/2014 %{date("dd/MM/yyyy"):date}{“date”: 1412978400000} Thu Jun 16 08:29:03 2016 %{date("EEE MMM dd HH:mm:ss yyyy"):date}{“date”: 1466065743000} Tue Nov 1 08:29:03 2016 %{date("EEE MMM d HH:mm:ss yyyy"):date}{“date”: 1466065743000} 06/Mar/2013:01:36:30 +0900 %{date("dd/MMM/yyyy:HH:mm:ss Z"):date}{“date”: 1362501390000} 2016-11-29T16:21:36.431+0000 %{date("yyyy-MM-dd'T'HH:mm:ss.SSSZ"):date}{“date”: 1480436496431} 2016-11-29T16:21:36.431+00:00 %{date("yyyy-MM-dd'T'HH:mm:ss.SSSZZ"):date}{“date”: 1480436496431} 06/Feb/2009:12:14:14.655 %{date("dd/MMM/yyyy:HH:mm:ss.SSS"):date}{“date”: 1233922454655} 2007-08-31 19:22:22.427 ADT %{date("yyyy-MM-dd HH:mm:ss.SSS z"):date}{“date”: 1188598942427} Thu Jun 16 08:29:03 20161 %{date("EEE MMM dd HH:mm:ss yyyy","Europe/Paris"):date}{“date”: 1466058543000} Thu Jun 16 08:29:03 20161 %{date("EEE MMM dd HH:mm:ss yyyy","UTC+5"):date}{“date”: 1466047743000} Thu Jun 16 08:29:03 20161 %{date("EEE MMM dd HH:mm:ss yyyy","+3"):date}{“date”: 1466054943000}
1 独自のローカライズを実行し、タイムスタンプが UTC _以外_の場合は、timezone パラメーターを使用します。
タイムゾーンとしてサポートされる形式は、以下になります。
GMT、UTC、UT、Z+h、+hh、+hh:mm、-hh:mm、+hhmm、-hhmm、+hh:mm:ss、-hh:mm:ss、+hhmmss、-hhmmss 。対応する範囲は最大で +18:00 から -18:00 までです。UTC+、UTC-、GMT+、GMT-、UT+、UT- で始まるタイムゾーン。対応する範囲は最大で +18:00 から -18:00 までです。TZ データベースから取得されるタイムゾーン ID。詳細については、TZ データベース名 を参照してください。 注 : 日付をパースしても、その値は公式のログ日付として設定されません 。設定するには、後続のプロセッサーで ログ日付リマッパー を使用してください。
交互パターン ログの形式が 2 通りあり、そのうち 1 つの属性だけが異なる場合は、(<REGEX_1>|<REGEX_2>) による交互条件を使用して 1 つの規則を設定します。この規則は Boolean OR と同じです。
ログの例
john connected on 11/08/2017
12345 connected on 11/08/2017
規則 :
“id” は整数です。文字列ではないので注意してください。
MyParsingRule (%{integer:user.id}|%{word:user.firstname}) connected on %{date("MM/dd/yyyy"):connect_date}
結果
オプションの属性 必ずしも表示されない値がログに含まれることがあります。その場合は、()? を使用して属性抽出を任意にします。
ログの例
john 1234 connected on 11/08/2017
規則の例
MyParsingRule %{word:user.firstname} (%{integer:user.id} )?connected on %{date("MM/dd/yyyy"):connect_date}
注 : 任意のセクションで先頭の単語の後ろにスペースを含めると、規則は一致しません。
ネストされた JSON 未処理のテキストプレフィックスの後でネストされている JSON オブジェクトをパースするには、json フィルターを使用します。
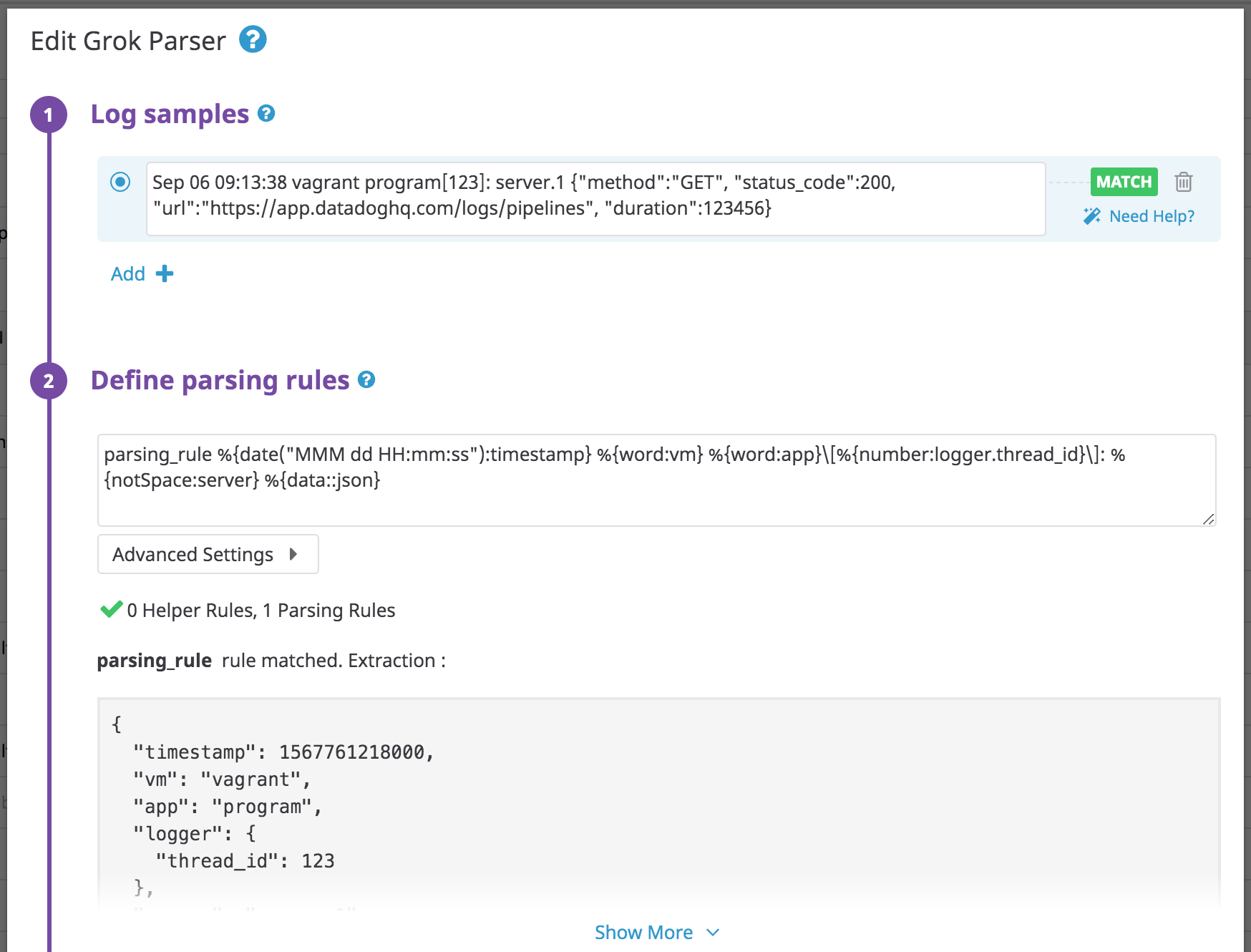
ログの例
Sep 06 09:13:38 vagrant program[123]: server.1 {"method":"GET", "status_code":200, "url":"https://app.datadoghq.com/logs/pipelines", "duration":123456}
規則の例
parsing_rule %{date("MMM dd HH:mm:ss"):timestamp} %{word:vm} %{word:app}\[%{number:logger.thread_id}\]: %{notSpace:server} %{data::json}
正規表現 ログの例
john_1a2b3c4 connected on 11/08/2017
規則の例
MyParsingRule %{regex("[a-z]*"):user.firstname}_%{regex("[a-zA-Z0-9]*"):user.id} .*
リストから配列へ リストを 1 つの属性の配列に取り出すには array([[openCloseStr, ] separator][, subRuleOrFilter) フィルターを使用します。subRuleOrFilter はオプションで、これらのフィルター を受け入れることができます。
ログの例
Users [John, Oliver, Marc, Tom] have been added to the database
規則の例
myParsingRule Users %{data:users:array("[]",",")} have been added to the database
ログの例
Users {John-Oliver-Marc-Tom} have been added to the database
規則の例
myParsingRule Users %{data:users:array("{}","-")} have been added to the database
subRuleOrFilter を使用したルール
myParsingRule Users %{data:users:array("{}","-", uppercase)} have been added to the database
GLog 形式 Kubernetes コンポーネントは glog 形式でログを記録することがあります。下の例は、パイプラインライブラリの Kube Scheduler アイテムからのものです。
ログラインの例、
W0424 11:47:41.605188 1 authorization.go:47] Authorization is disabled
パースの例、
kube_scheduler %{regex("\\w"):level}%{date("MMdd HH:mm:ss.SSSSSS"):timestamp}\s+%{number:logger.thread_id} %{notSpace:logger.name}:%{number:logger.lineno}\] %{data:msg}
抽出された JSON、
{
"level" : "W" ,
"timestamp" : 1587728861605 ,
"logger" : {
"thread_id" : 1 ,
"name" : "authorization.go"
},
"lineno" : 47 ,
"msg" : "Authorization is disabled"
}
XML のパース XML パーサーは、XML 形式のメッセージを JSON に変換します。
ログ:
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
</book>
例:
結果:
{
"book" : {
"year" : "2005" ,
"author" : "J K. Rowling" ,
"category" : "CHILDREN" ,
"title" : {
"lang" : "en" ,
"value" : "Harry Potter"
}
}
}
注 :
XML に、前後のタグの間に属性と文字列値の両方が存在するタグが含まれている場合、value 属性が生成されます。例えば、<title lang="en">Harry Potter</title> は {"title": {"lang": "en", "value": "Harry Potter" } } に変換されます。 繰り返しタグは自動的に配列に変換されます。例えば、<bookstore><book>Harry Potter</book><book>Everyday Italian</book></bookstore> は { "bookstore": { "book": [ "Harry Potter", "Everyday Italian" ] } } に変換されます。 CSV をパースする CSV フィルターを使用して、文字列を属性に簡単にマップできます。対象のデータは任意の文字で区切る必要があります (デフォルトでは , ) 。
CSV フィルターは csv(headers[, separator[, quotingcharacter]]) で定義されます。それぞれの内容は以下の通りです。
headers: , で区切られたキーの名前を定義します。キー名にはアルファベットと _ を使用できますが、冒頭の文字はアルファベットでなければなりません。separator: 異なる値の区切りに使用する区切り文字を定義します。1 文字のみ使用可能です。デフォルト: ,。注 : TSV のタブ文字を表すには、separator に tab を使用します。quotingcharacter: 引用符を定義します。許可されるのは 1 文字だけです。デフォルトは " 。注 :
区切り文字を含む値は引用符で囲む必要があります。 引用符で囲まれた (引用符を含む) 値は引用符でエスケープする必要があります。たとえば、引用符を含む値における "" は " を意味します。 ヘッダーに含まれるキー数と同じ個数の値がログに含まれていない場合、CSV パーサーは最初に出現する値とのマッチングを行います。 整数と浮動小数点数は、可能な場合自動でキャストされます。 ログの例
Copy
John,Doe,120,Jefferson St.,Riverside 規則の例
Copy
myParsingRule %{data:user:csv("first_name,name,st_nb,st_name,city")} 結果:
Copy
{
"user" : {
"first_name" : "John" ,
"name" : "Doe" ,
"st_nb" : 120 ,
"st_name" : "Jefferson St." ,
"city" : "Riverside"
}
} その他の例
文字列の例 パース規則 結果 John,Doe%{data::csv("firstname,name")}{“firstname”: “John”, “name”:“Doe”} "John ""Da Man""",Doe%{data::csv("firstname,name")}{“firstname”: “John "Da Man"”, “name”:“Doe”} 'John ''Da Man''',Doe%{data::csv("firstname,name",",","'")}{“firstname”: “John ‘Da Man’”, “name”:“Doe”} John|Doe%{data::csv("firstname,name","|")}{“firstname”: “John”, “name”:“Doe”} value1,value2,value3%{data::csv("key1,key2")}{“key1”: “value1”, “key2”:“value2”} value1,value2%{data::csv("key1,key2,key3")}{“key1”: “value1”, “key2”:“value2”} value1,,value3%{data::csv("key1,key2,key3")}{“key1”: “value1”, “key3”:“value3”} Value1 Value2 Value3 (TSV)%{data::csv("key1,key2,key3","tab")}{“key1”: “value1”, “key2”: “value2”, “key3”:“value3”}
data matcher を使用して、不要なテキストを破棄する もし、必要な情報をパースした後のログで、それ以降のテキストは安全に破棄できるとわかっている場合、data matcher を使ってそれを行うことができます。以下のログの例では、data matcher を使って末尾の % を破棄することができます。
ログの例
規則の例
MyParsingRule Usage\:\s+%{number:usage}%{data:ignore}
Result :
{
"usage": 24.3,
"ignore": "%"
}
ASCII 制御文字 ログに ASCII 制御文字が含まれている場合、それは取り込み時にシリアル化されます。これは、grok パーサー内でシリアル化された値を明示的にエスケープすることで処理できます。
その他の参考資料