概要
Cloud Run は、HTTP リクエストを使って呼び出し可能なステートレスコンテナを実行できるマネージド型のコンピューティングプラットフォームです。
このインテグレーションを有効にしてコンテナをインスツルメンテーションすると、Cloud Run のメトリクス、トレース、ログのすべてを Datadog に表示できます。
Cloud Run for Anthos の詳細については、Google Cloud Run for Anthos ドキュメントを参照してください。
セットアップ
メトリクスの収集
インストール
Google Cloud Platform インテグレーションをセットアップして、すぐに使えるメトリクスの収集を開始します。カスタムメトリクスを設定するには、Serverless ドキュメントを参照してください。
ログ収集
インテグレーション
Google Cloud Run は監査ログも公開します。
Google Cloud Run のログは Google Cloud Logging で収集され、Cloud Pub/Sub トピックを通じて Dataflow ジョブに送信されます。まだの場合は、Datadog Dataflow テンプレートでロギングをセットアップしてください。
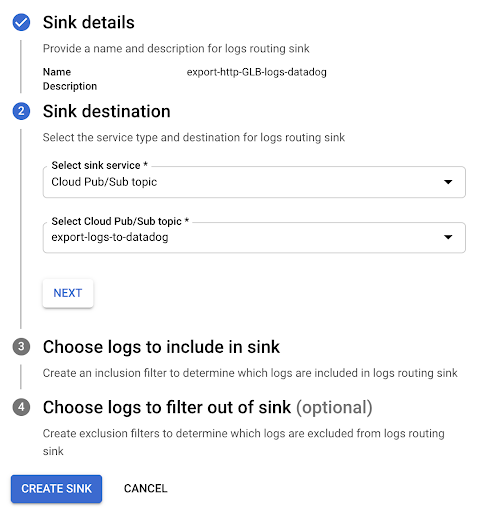
これが完了したら、Google Cloud Run のログを Google Cloud Logging から Pub/Sub トピックへエクスポートします。
Google Cloud Logging のページに移動し、Google Cloud Run のログを絞り込みます。
シンクを作成し、シンクに適宜名前を付けます。
宛先として “Cloud Pub/Sub” を選択し、その目的で作成された Pub/Sub トピックを選択します。注: Pub/Sub トピックは別のプロジェクトに配置できます。
作成をクリックし、確認メッセージが表示されるまで待ちます。
直接ロギング
Cloud Run サービスから Datadog へのアプリケーションの直接ロギングについては、Serverless ドキュメントを参照してください。
トレーシング
フルマネージド Google Cloud Run に特化した Agent の設定手順については、Serverless ドキュメントを参照してください。
収集データ
メトリクス
イベント
Google Cloud Functions インテグレーションには、イベントは含まれません。
サービスチェック
Google Cloud Functions インテグレーションには、サービスのチェック機能は含まれません。
トラブルシューティング
ご不明な点は、Datadog のサポートチームまでお問い合わせください。
その他の参考資料