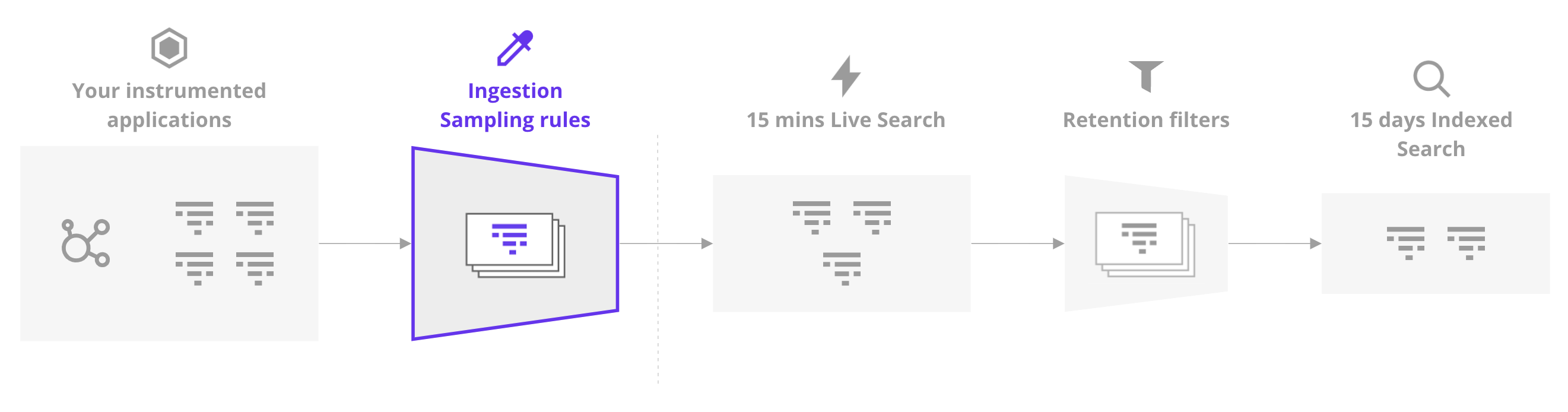
Plusieurs mécanismes déterminent si les spans générés par vos applications sont envoyés à Datadog (ingérés). La logique derrière ces mécanismes réside dans les bibliothèques de traçage et dans l’Agent Datadog. Selon la configuration, tout ou une partie du trafic généré par les services instrumentés est ingéré.
Chaque span ingéré se voit attribuer une raison d’ingestion unique, qui correspond à l’un des mécanismes décrits sur cette page. Métriques d’utilisation datadog.estimated_usage.apm.ingested_bytes et datadog.estimated_usage.apm.ingested_spans sont étiquetées par ingestion_reason.
Utilisez le tableau de bord des raisons d’ingestion pour enquêter dans le contexte chacune de ces raisons d’ingestion. Obtenez un aperçu du volume attribué à chaque mécanisme, pour savoir rapidement sur quelles options de configuration se concentrer.
Échantillonnage basé sur l’en-tête
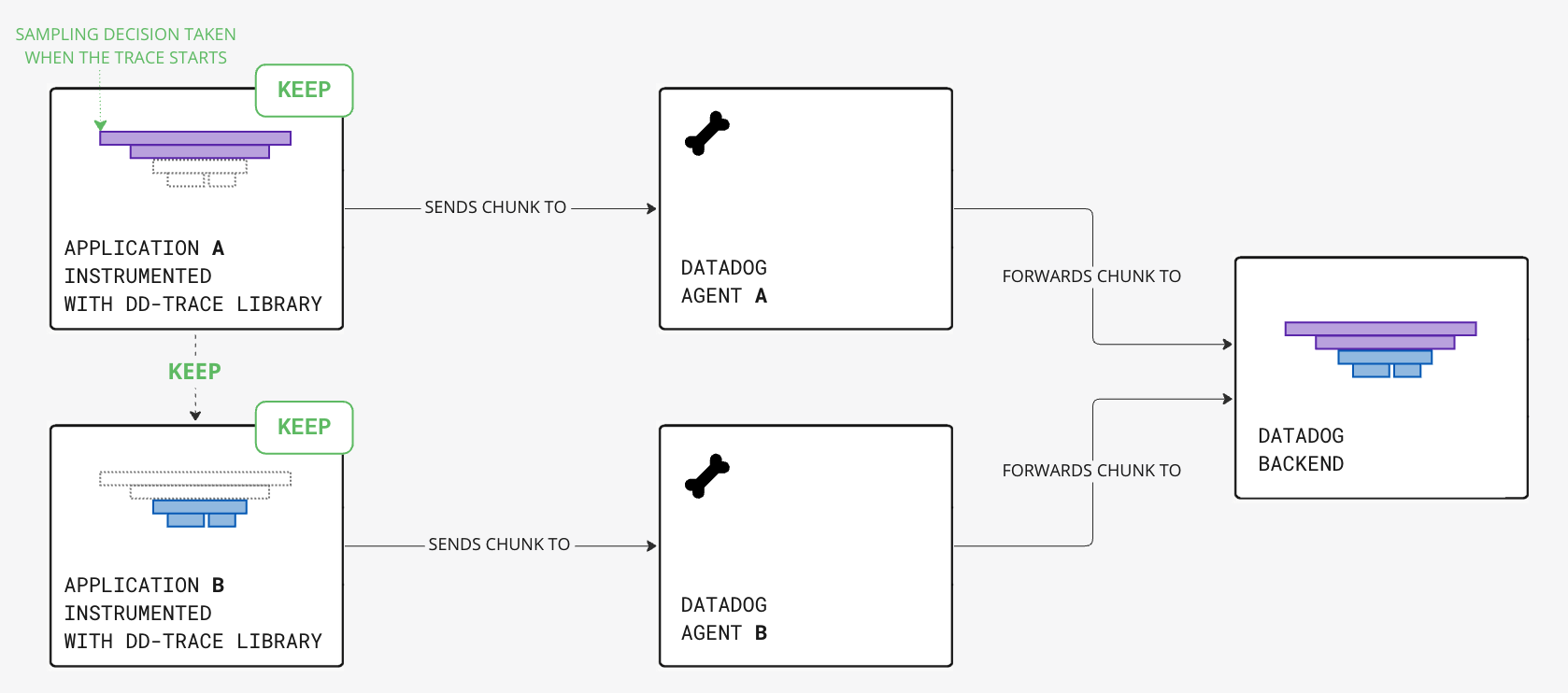
Le mécanisme d’échantillonnage par défaut est appelé échantillonnage basé sur l’en-tête. La décision de conserver ou de supprimer une trace est prise dès le début de la trace, au début du span racine. Cette décision est ensuite propagée à d’autres services dans le cadre de leur contexte de requête, par exemple sous forme d’en-tête de requête HTTP.
Parce que la décision est prise au début de la trace et ensuite transmise à toutes les parties de la trace, la trace est garantie d’être conservée ou supprimée dans son ensemble.
Vous pouvez définir les taux d’échantillonnage pour l’échantillonnage basé sur l’en-tête à deux endroits :
- Au niveau de l’Agent (par défaut)
- Au niveau de la Bibliothèque de Traçage : tout mécanisme de bibliothèque de traçage remplace la configuration de l’Agent.
Dans l’Agent
ingestion_reason: auto
L’Agent Datadog envoie en continu des taux d’échantillonnage aux bibliothèques de traçage à appliquer à la racine des traces. L’Agent ajuste les taux pour atteindre un objectif de dix traces par seconde au total, réparties entre les services en fonction du trafic.
Par exemple, si le service A a plus de trafic que le service B, l’Agent peut varier le taux d’échantillonnage pour A de sorte que A ne conserve pas plus de sept traces par seconde, et ajuster de manière similaire le taux d’échantillonnage pour B afin que B ne conserve pas plus de trois traces par seconde, pour un total de 10 traces par seconde.
Configuration à distance
La configuration du taux d’échantillonnage dans l’Agent peut être configurée à distance si vous utilisez la version de l’Agent 7.42.0 ou supérieure. Pour commencer, configurez Configuration à Distance puis configurez le paramètre ingestion_reason depuis la page de Contrôle d’Ingestion. La configuration à distance vous permet de modifier le paramètre sans avoir à redémarrer l’Agent. La configuration à distance a la priorité sur les configurations locales, y compris les variables d’environnement et les paramètres de datadog.yaml.
Configuration locale
Définissez le nombre cible de traces par seconde de l’Agent dans son fichier de configuration principal (datadog.yaml) ou en tant que variable d’environnement :
@param target_traces_per_second - integer - optional - default: 10
@env DD_APM_TARGET_TPS - integer - optional - default: 10
Remarques :
- Le taux d’échantillonnage de traces par seconde défini dans l’Agent ne s’applique qu’aux bibliothèques de traçage Datadog. Cela n’a aucun effet sur d’autres bibliothèques de traçage telles que les SDK OpenTelemetry.
- La cible n’est pas une valeur fixe. En réalité, elle fluctue en fonction des pics de trafic et d’autres facteurs.
Tous les spans d’une trace échantillonnée via l’Agent Datadog (taux d’échantillonnage calculés automatiquement) sont étiquetés avec la raison d’ingestion auto. Le tag ingestion_reason est également défini sur les métriques d’utilisation. Les services utilisant le mécanisme par défaut de l’Agent Datadog sont étiquetés comme Automatic dans la colonne Configuration de la Page de contrôle d’ingestion.
Dans les bibliothèques de traçage : règles définies par l’utilisateur
ingestion_reason: rule
Pour un contrôle plus granulaire, utilisez les options de configuration d’échantillonnage de la bibliothèque de traçage :
-Définissez un taux d’échantillonnage spécifique à appliquer à la racine de la trace, par service et/ou par nom de ressource, en remplaçant le mécanisme par défaut de l’Agent.
- Définissez une limite de taux sur le nombre de traces ingérées par seconde. La limite de taux par défaut est de 100 traces par seconde par instance de service (lors de l’utilisation du mécanisme par défaut de l’Agent, le limiteur de taux est ignoré).
Remarque : Les règles d’échantillonnage sont également des contrôles d’échantillonnage basés sur l’en-tête. Si le trafic pour un service est supérieur au maximum configuré de traces par seconde, alors les traces sont abandonnées à la racine. Cela ne crée pas de traces incomplètes.
La configuration peut être définie par des variables d’environnement ou directement dans le code :
Configuration à distance
À partir de la version 1.34.0, pour les applications Java, définissez les taux d’échantillonnage par service et par ressource depuis l’interface utilisateur de la Page de contrôle d’ingestion.
En savoir plus sur la façon de configurer à distance les taux d’échantillonnage par service et par ressource dans le guide d’échantillonnage basé sur les ressources.
Remarque : La configuration à distance a la priorité sur la configuration locale.
Configuration locale
Pour les applications Java, définissez les taux d’échantillonnage par service et par ressource (à partir de la version v1.26.0 pour l’échantillonnage basé sur les ressources) avec la variable d’environnement DD_TRACE_SAMPLING_RULES.
Par exemple, pour capturer 100 % des traces pour la ressource GET /checkout du service my-service, et 20 % des traces des autres points de terminaison, définissez :
# using system property
java -Ddd.trace.sampling.rules='[{"service": "my-service", "resource": "GET /checkout", "sample_rate":1},{"service": "my-service", "sample_rate":0.2}]' -javaagent:dd-java-agent.jar -jar my-app.jar
# using environment variables
export DD_TRACE_SAMPLING_RULES='[{"service": "my-service", "resource":"GET /checkout", "sample_rate": 1},{"service": "my-service", "sample_rate": 0.2}]'
La valeur du nom de service est sensible à la casse et doit correspondre à la casse du nom de service réel.
Configurez une limite de taux en définissant la variable d’environnement DD_TRACE_RATE_LIMIT à un nombre de traces par seconde par instance de service. Si aucune valeur DD_TRACE_RATE_LIMIT n’est définie, une limite de 100 traces par seconde est appliquée.
Remarque : L’utilisation de DD_TRACE_SAMPLE_RATE est obsolète. Utilisez DD_TRACE_SAMPLING_RULES à la place. Par exemple, si vous avez déjà défini DD_TRACE_SAMPLE_RATE sur 0.1, définissez DD_TRACE_SAMPLING_RULES sur [{"sample_rate":0.1}] à la place.
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage Java.
Configuration à distance
À partir de la version 2.9.0, pour les applications Python, définissez les taux d’échantillonnage par service et par ressource depuis l’interface utilisateur de la Page de contrôle d’ingestion.
En savoir plus sur la façon de configurer à distance les taux d’échantillonnage par service et par ressource dans le guide d’échantillonnage basé sur les ressources.
Remarque : La configuration à distance a la priorité sur la configuration locale.
Configuration locale
Pour les applications Python, définissez les taux d’échantillonnage par service et par ressource (à partir de la version v2.8.0 pour l’échantillonnage basé sur les ressources) avec la variable d’environnement DD_TRACE_SAMPLING_RULES.
Par exemple, pour capturer 100 % des traces pour la ressource GET /checkout du service my-service, et 20 % des traces des autres points de terminaison, définissez :
export DD_TRACE_SAMPLING_RULES='[{"service": "my-service", "resource": "GET /checkout", "sample_rate": 1},{"service": "my-service", "sample_rate": 0.2}]'
Configurez une limite de taux en définissant la variable d’environnement DD_TRACE_RATE_LIMIT à un nombre de traces par seconde par instance de service. Si aucune valeur DD_TRACE_RATE_LIMIT n’est définie, une limite de 100 traces par seconde est appliquée.
Remarque : L’utilisation de DD_TRACE_SAMPLE_RATE est obsolète. Utilisez DD_TRACE_SAMPLING_RULES à la place. Par exemple, si vous avez déjà défini DD_TRACE_SAMPLE_RATE sur 0.1, définissez DD_TRACE_SAMPLING_RULES sur [{"sample_rate":0.1}] à la place.
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage Python.
Configuration à distance
À partir de la version 2.0.0, pour les applications Ruby, définissez les taux d’échantillonnage par service et par ressource depuis l’interface utilisateur de la Page de contrôle d’ingestion.
En savoir plus sur la façon de configurer à distance les taux d’échantillonnage par service et par ressource dans le guide d’échantillonnage basé sur les ressources.
Remarque : La configuration à distance a la priorité sur la configuration locale.
Configuration locale
Pour les applications Ruby, définissez un taux d’échantillonnage global pour la bibliothèque en utilisant la variable d’environnement DD_TRACE_SAMPLE_RATE. Définissez les taux d’échantillonnage par service avec la variable d’environnement DD_TRACE_SAMPLING_RULES.
Par exemple, pour envoyer 50 % des traces pour le service nommé my-service et 10 % des autres traces :
export DD_TRACE_SAMPLE_RATE=0.1
export DD_TRACE_SAMPLING_RULES='[{"service": "my-service", "sample_rate": 0.5}]'
Configurez une limite de taux en définissant la variable d’environnement DD_TRACE_RATE_LIMIT à un nombre de traces par seconde par instance de service. Si aucune valeur DD_TRACE_RATE_LIMIT n’est définie, une limite de 100 traces par seconde est appliquée.
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage Ruby.
Configuration à distance
À partir de la version 1.64.0, pour les applications Go, définissez les taux d’échantillonnage par service et par ressource depuis l’interface utilisateur de la page de contrôle d’ingestion.
En savoir plus sur la façon de configurer à distance les taux d’échantillonnage par service et par ressource dans cet article.
Remarque : La configuration définie à distance a la priorité sur la configuration locale.
Configuration locale
Pour les applications Go, définissez les taux d’échantillonnage par service et par ressource (à partir de la version v1.60.0 pour l’échantillonnage basé sur les ressources) avec la variable d’environnement DD_TRACE_SAMPLING_RULES.
Par exemple, pour capturer 100 % des traces pour la ressource GET /checkout du service my-service, et 20 % des traces des autres points de terminaison, définissez :
export DD_TRACE_SAMPLING_RULES='[{"service": "my-service", "resource": "GET /checkout", "sample_rate": 1},{"service": "my-service", "sample_rate": 0.2}]'
Configurez une limite de taux en définissant la variable d’environnement DD_TRACE_RATE_LIMIT à un nombre de traces par seconde par instance de service. Si aucune valeur DD_TRACE_RATE_LIMIT n’est définie, une limite de 100 traces par seconde est appliquée.
Remarque : L’utilisation de DD_TRACE_SAMPLE_RATE est obsolète. Utilisez DD_TRACE_SAMPLING_RULES à la place. Par exemple, si vous avez déjà défini DD_TRACE_SAMPLE_RATE sur 0.1, définissez DD_TRACE_SAMPLING_RULES sur [{"sample_rate":0.1}] à la place.
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage Go.
Configuration à distance
À partir de la version 5.16.0, pour les applications Node.js, définissez les taux d’échantillonnage par service et par ressource depuis l’interface utilisateur de la page de contrôle d’ingestion.
En savoir plus sur la façon de configurer à distance les taux d’échantillonnage par service et par ressource dans le guide d’échantillonnage basé sur les ressources.
Remarque : La configuration à distance a la priorité sur la configuration locale.
Configuration locale
Pour les applications Node.js, définissez un taux d’échantillonnage global dans la bibliothèque en utilisant la variable d’environnement DD_TRACE_SAMPLE_RATE.
Vous pouvez également définir des taux d’échantillonnage par service. Par exemple, pour envoyer 50 % des traces pour le service nommé my-service et 10 % pour le reste des traces :
tracer.init({
ingestion: {
sampler: {
sampleRate: 0.1,
rules: [
{ sampleRate: 0.5, service: 'my-service' }
]
}
}
});
Configurez une limite de taux en définissant la variable d’environnement DD_TRACE_RATE_LIMIT à un nombre de traces par seconde par instance de service. Si aucune valeur DD_TRACE_RATE_LIMIT n’est définie, une limite de 100 traces par seconde est appliquée.
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage Node.js.
Configuration à distance
À partir de la version 1.4.0, pour les applications PHP, définissez les taux d’échantillonnage par service et par ressource à partir de la page de contrôle d’ingestion.
En savoir plus sur la façon de configurer à distance les taux d’échantillonnage par service et par ressource dans le guide d’échantillonnage basé sur les ressources.
Remarque : La configuration définie à distance a la priorité sur la configuration locale.
Configuration locale
Pour les applications PHP, définissez un taux d’échantillonnage global pour la bibliothèque en utilisant la variable d’environnement DD_TRACE_SAMPLE_RATE. Définissez les taux d’échantillonnage par service avec la variable d’environnement DD_TRACE_SAMPLING_RULES.
Par exemple, pour envoyer 50 % des traces pour le service nommé my-service, 20 % des traces des autres points de terminaison, et 10 % pour le reste des traces, définissez :
export DD_TRACE_SAMPLE_RATE=0.1
export DD_TRACE_SAMPLING_RULES='[{"service": "my-service", "resource":"GET /checkout", "sample_rate": 1},{"service": "my-service", "sample_rate": 0.2}]'
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage PHP.
Configuration à distance
À partir de la version 0.2.2, pour les applications C++, définissez les taux d’échantillonnage par service et par ressource à partir de l’interface utilisateur de la page de contrôle d’ingestion.
En savoir plus sur la façon de configurer à distance les taux d’échantillonnage par service et par ressource dans le guide d’échantillonnage basé sur les ressources.
Remarque : La configuration définie à distance a la priorité sur la configuration locale.
Configuration locale
À partir de v0.1.0, la bibliothèque C++ de Datadog prend en charge les configurations suivantes :
- Taux d’échantillonnage global :
DD_TRACE_SAMPLE_RATE variable d’environnement - Taux d’échantillonnage par service :
DD_TRACE_SAMPLING_RULES variable d’environnement. - Paramètre de limite de taux : variable d’environnement
DD_TRACE_RATE_LIMIT.
Par exemple, pour envoyer 50 % des traces pour le service nommé my-service et 10 % pour le reste des traces :
export DD_TRACE_SAMPLE_RATE=0.1
export DD_TRACE_SAMPLING_RULES='[{"service": "my-service", "sample_rate": 0.5}]'
C++ ne fournit pas d’intégrations pour l’instrumentation automatique, mais il est utilisé pour le traçage via des proxies tels qu’Envoy, Nginx ou Istio. En savoir plus sur la façon de configurer l’échantillonnage pour les proxies dans Traçage des proxies.
Pour les applications .NET, définissez un taux d’échantillonnage global pour la bibliothèque en utilisant la variable d’environnement DD_TRACE_SAMPLE_RATE. Définissez les taux d’échantillonnage par service avec la variable d’environnement DD_TRACE_SAMPLING_RULES.
Par exemple, pour envoyer 50 % des traces pour le service nommé my-service et 10 % pour le reste des traces :
#using powershell
$env:DD_TRACE_SAMPLE_RATE=0.1
$env:DD_TRACE_SAMPLING_RULES='[{"service": "my-service", "sample_rate": 0.5}]'
#using JSON file
{
"DD_TRACE_SAMPLE_RATE": "0.1",
"DD_TRACE_SAMPLING_RULES": "[{\"service\": \"my-service\", \"resource\": \"GET /checkout\", \"sample_rate\": 0.5}]"
}
Configurez une limite de taux en définissant la variable d’environnement DD_TRACE_RATE_LIMIT à un nombre de traces par seconde par instance de service. Si aucune valeur DD_TRACE_RATE_LIMIT n’est définie, une limite de 100 traces par seconde est appliquée.
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage .NET.
En savoir plus sur la configuration des variables d’environnement pour .NET.
Remarque : Tous les spans d’une trace échantillonnée à l’aide d’une configuration de bibliothèque de traçage sont étiquetés avec la raison d’ingestion rule. Les services configurés avec des règles d’échantillonnage définies par l’utilisateur sont marqués comme Configured dans la colonne Configuration de la page de contrôle d’ingestion.
Traces d’erreur et traces rares
Pour les traces non capturées par l’échantillonnage basé sur l’en-tête, deux mécanismes d’échantillonnage supplémentaires de l’agent Datadog garantissent que les traces critiques et diverses sont conservées et ingérées. Ces deux échantillonneurs conservent un ensemble diversifié de traces locales (ensemble de spans du même hôte) en capturant toutes les combinaisons d’un ensemble prédéterminé d’étiquettes :
- Traces d’erreur : Échantillonner les erreurs est important pour fournir une visibilité sur les pannes potentielles du système.
- Traces rares : Échantillonner les traces rares vous permet de garder une visibilité sur votre système dans son ensemble, en veillant à ce que les services et ressources à faible trafic soient toujours surveillés.
Remarque : Les échantillonneurs d’erreurs et de traces rares sont ignorés pour les services pour lesquels vous avez défini des règles d’échantillonnage de bibliothèque.
Traces d’erreur
ingestion_reason: error
L’échantillonneur d’erreurs capture des morceaux de traces contenant des spans d’erreur qui ne sont pas capturés par l’échantillonnage basé sur l’en-tête. Il capture des traces d’erreur jusqu’à un taux de 10 traces par seconde (par agent). Il garantit une visibilité complète sur les erreurs lorsque le taux d’échantillonnage basé sur l’en-tête est faible.
Avec la version 7.33 de l’agent et les versions ultérieures, vous pouvez configurer l’échantillonneur d’erreurs dans le fichier de configuration principal de l’agent (datadog.yaml) ou avec des variables d’environnement :
@param errors_per_second - integer - optional - default: 10
@env DD_APM_ERROR_TPS - integer - optional - default: 10
Remarques :
- Réglez le paramètre sur
0 pour désactiver l’échantillonneur d’erreurs. - L’échantillonneur d’erreurs capture les traces locales avec des spans d’erreur au niveau de l’Agent. Si la trace est distribuée, il n’y a aucune garantie que la trace complète soit envoyée à Datadog.
- Par défaut, les spans supprimés par les règles de la bibliothèque de traçage ou par une logique personnalisée telle que
manual.drop sont exclus sous l’échantillonneur d’erreurs.
Datadog Agent 7.42.0 et supérieur
L’échantillonnage des erreurs est configuré à distance si vous utilisez la version de l’Agent 7.42.0 ou supérieure. Suivez la documentation pour activer la configuration à distance dans vos Agents. Avec la configuration à distance, vous pouvez activer la collecte de spans rares sans avoir à redémarrer l’Agent Datadog.
Datadog Agent 6/7.41.0 et supérieur
Pour remplacer le comportement par défaut afin que les spans supprimés par les règles de la bibliothèque de traçage ou par une logique personnalisée telle que manual.drop soient inclus par l’échantillonneur d’erreurs, activez la fonctionnalité avec : DD_APM_FEATURES=error_rare_sample_tracer_drop dans l’Agent Datadog (ou le conteneur dédié de l’Agent de Traçage dans le pod de l’Agent Datadog dans Kubernetes).
Datadog Agent 6/7.33 à 6/7.40.x
Le comportement par défaut de l’échantillonnage des erreurs ne peut pas être modifié pour ces versions de l’Agent. Mettez à niveau l’Agent Datadog vers Datadog Agent 6/7.41.0 et supérieur.
Traces rares
ingestion_reason: rare
L’échantillonneur rare envoie un ensemble de spans rares à Datadog. Il capture des combinaisons de env, service, name, resource, error.type et http.status jusqu’à 5 traces par seconde (par Agent). Il garantit la visibilité sur les ressources à faible trafic lorsque le taux d’échantillonnage basé sur l’en-tête est faible.
Remarque : L’échantillonneur rare capture les traces locales au niveau de l’Agent. Si la trace est distribuée, il n’y a aucun moyen de garantir que la trace complète sera envoyée à Datadog.
Datadog Agent 7.42.0 et supérieur
Le taux d’échantillonnage rare est configurable à distance si vous utilisez la version de l’Agent 7.42.0 ou supérieure. Suivez la documentation pour activer la configuration à distance dans vos Agents. Avec la configuration à distance, vous pouvez changer la valeur du paramètre sans avoir à redémarrer l’Agent Datadog.
Datadog Agent 6/7.41.0 et supérieur
Par défaut, l’échantillonneur rare n’est pas activé.
Remarque : Lorsque activé, les spans supprimés par les règles de la bibliothèque de traçage ou par une logique personnalisée telle que manual.drop sont exclus sous cet échantillonneur.
Pour configurer l’échantillonneur rare, mettez à jour le paramètre apm_config.enable_rare_sampler dans le fichier de configuration principal de l’Agent (datadog.yaml) ou avec la variable d’environnement DD_APM_ENABLE_RARE_SAMPLER :
@params apm_config.enable_rare_sampler - boolean - optional - default: false
@env DD_APM_ENABLE_RARE_SAMPLER - boolean - optional - default: false
Pour évaluer les spans supprimés par les règles de la bibliothèque de traçage ou par une logique personnalisée telle que manual.drop,
activez la fonctionnalité avec : DD_APM_FEATURES=error_rare_sample_tracer_drop dans l’Agent de Traçage.
Datadog Agent 6/7.33 à 6/7.40.x
Par défaut, l’échantillonneur rare est activé.
Remarque : Lorsque activé, les spans supprimés par les règles de la bibliothèque de traçage ou par une logique personnalisée telle que manual.drop sont exclus sous cet échantillonneur. Pour inclure ces spans dans cette logique, mettez à niveau vers l’Agent Datadog 6.41.0/7.41.0 ou supérieur.
Pour changer les paramètres par défaut de l’échantillonneur rare, mettez à jour le paramètre apm_config.disable_rare_sampler dans le fichier de configuration principal de l’Agent (datadog.yaml) ou avec la variable d’environnement DD_APM_DISABLE_RARE_SAMPLER :
@params apm_config.disable_rare_sampler - boolean - optional - default: false
@env DD_APM_DISABLE_RARE_SAMPLER - boolean - optional - default: false
Forcer la conservation et la suppression
ingestion_reason: manual
Le mécanisme d’échantillonnage basé sur l’en-tête peut être remplacé au niveau de la bibliothèque de traçage. Par exemple, si vous devez surveiller une transaction critique, vous pouvez forcer la trace associée à être conservée. En revanche, pour des informations inutiles ou répétitives comme les vérifications de santé, vous pouvez forcer la trace à être supprimée.
Définissez le maintien manuel sur un span pour indiquer que celui-ci et tous les spans enfants doivent être ingérés. La trace résultante peut sembler incomplète dans l’interface utilisateur si le span en question n’est pas le span racine de la trace.
Définissez le Manual Drop sur un span pour vous assurer qu’aucun span enfant n’est ingéré. Les échantillonneurs d’erreur et rares seront ignorés dans l’Agent.
Gardez manuellement une trace :
import datadog.trace.api.DDTags;
import io.opentracing.Span;
import datadog.trace.api.Trace;
import io.opentracing.util.GlobalTracer;
public class MyClass {
@Trace
public static void myMethod() {
// grab the active span out of the traced method
Span span = GlobalTracer.get().activeSpan();
// Always keep the trace
span.setTag(DDTags.MANUAL_KEEP, true);
// method impl follows
}
}
Supprimez manuellement une trace :
import datadog.trace.api.DDTags;
import io.opentracing.Span;
import datadog.trace.api.Trace;
import io.opentracing.util.GlobalTracer;
public class MyClass {
@Trace
public static void myMethod() {
// grab the active span out of the traced method
Span span = GlobalTracer.get().activeSpan();
// Always Drop the trace
span.setTag(DDTags.MANUAL_DROP, true);
// method impl follows
}
}
Gardez manuellement une trace :
from ddtrace import tracer
from ddtrace.constants import MANUAL_DROP_KEY, MANUAL_KEEP_KEY
@tracer.wrap()
def handler():
span = tracer.current_span()
# Always Keep the Trace
span.set_tag(MANUAL_KEEP_KEY)
# method impl follows
Supprimez manuellement une trace :
from ddtrace import tracer
from ddtrace.constants import MANUAL_DROP_KEY, MANUAL_KEEP_KEY
@tracer.wrap()
def handler():
span = tracer.current_span()
# Always Drop the Trace
span.set_tag(MANUAL_DROP_KEY)
# method impl follows
Gardez manuellement une trace :
Datadog::Tracing.trace(name, options) do |span, trace|
trace.keep! # Affects the active trace
# Method implementation follows
end
Supprimez manuellement une trace :
Datadog::Tracing.trace(name, options) do |span, trace|
trace.reject! # Affects the active trace
# Method implementation follows
end
Note: This documentation uses v2 of the Go tracer, which Datadog recommends for all users. If you are using v1, see the migration guide to upgrade to v2.
Gardez manuellement une trace :
package main
import (
"log"
"net/http"
"github.com/DataDog/dd-trace-go/v2/ddtrace/ext"
"github.com/DataDog/dd-trace-go/v2/ddtrace/tracer"
)
func handler(w http.ResponseWriter, r *http.Request) {
// Create a span for a web request at the /posts URL.
span := tracer.StartSpan("web.request", tracer.ResourceName("/posts"))
defer span.Finish()
// Always keep this trace:
span.SetTag(ext.ManualKeep, true)
//method impl follows
}
Supprimez manuellement une trace :
package main
import (
"log"
"net/http"
"github.com/DataDog/dd-trace-go/v2/ddtrace/ext"
"github.com/DataDog/dd-trace-go/v2/ddtrace/tracer"
)
func handler(w http.ResponseWriter, r *http.Request) {
// Create a span for a web request at the /posts URL.
span := tracer.StartSpan("web.request", tracer.ResourceName("/posts"))
defer span.Finish()
// Always drop this trace:
span.SetTag(ext.ManualDrop, true)
//method impl follows
}
Gardez manuellement une trace :
const tracer = require('dd-trace')
const tags = require('dd-trace/ext/tags')
const span = tracer.startSpan('web.request')
// Always keep the trace
span.setTag(tags.MANUAL_KEEP)
//method impl follows
Supprimez manuellement une trace :
const tracer = require('dd-trace')
const tags = require('dd-trace/ext/tags')
const span = tracer.startSpan('web.request')
// Always drop the trace
span.setTag(tags.MANUAL_DROP)
//method impl follows
Gardez manuellement une trace :
using Datadog.Trace;
using(var scope = Tracer.Instance.StartActive("my-operation"))
{
var span = scope.Span;
// Always keep this trace
span.SetTag(Datadog.Trace.Tags.ManualKeep, "true");
//method impl follows
}
Supprimez manuellement une trace :
using Datadog.Trace;
using(var scope = Tracer.Instance.StartActive("my-operation"))
{
var span = scope.Span;
// Always drop this trace
span.SetTag(Datadog.Trace.Tags.ManualDrop, "true");
//method impl follows
}
Gardez manuellement une trace :
<?php
$tracer = \DDTrace\GlobalTracer::get();
$span = $tracer->getActiveSpan();
if (null !== $span) {
// Always keep this trace
$span->setTag(\DDTrace\Tag::MANUAL_KEEP, true);
}
?>
Supprimez manuellement une trace :
<?php
$tracer = \DDTrace\GlobalTracer::get();
$span = $tracer->getActiveSpan();
if (null !== $span) {
// Always drop this trace
$span->setTag(\DDTrace\Tag::MANUAL_DROP, true);
}
?>
Gardez manuellement une trace :
...
#include <datadog/tags.h>
#include <datadog/trace_segment.h>
#include <datadog/sampling_priority.h>
...
dd::SpanConfig span_cfg;
span_cfg.resource = "operation_name";
auto span = tracer.create_span(span_cfg);
// Always keep this trace
span.trace_segment().override_sampling_priority(int(dd::SamplingPriority::USER_KEEP));
//method impl follows
Supprimez manuellement une trace :
...
#include <datadog/tags.h>
#include <datadog/trace_segment.h>
#include <datadog/sampling_priority.h>
...
using namespace dd = datadog::tracing;
dd::SpanConfig span_cfg;
span_cfg.resource = "operation_name";
auto another_span = tracer.create_span(span_cfg);
// Always drop this trace
span.trace_segment().override_sampling_priority(int(dd::SamplingPriority::USER_DROP));
//method impl follows
La conservation manuelle des traces doit se faire avant la propagation du contexte. Si elle est conservée après la propagation du contexte, le système ne peut pas garantir que l’ensemble de la trace est conservé à travers les services. La conservation manuelle des traces est définie à l’emplacement du client de traçage, de sorte que la trace peut toujours être supprimée par l’Agent ou l’emplacement du serveur en fonction des règles d’échantillonnage.
Spans uniques
ingestion_reason: single_span
Si vous devez échantillonner un span spécifique, mais que vous n’avez pas besoin que la trace complète soit disponible, les bibliothèques de traçage vous permettent de définir un taux d’échantillonnage à configurer pour un seul span.
Par exemple, si vous construisez des métriques à partir de spans pour surveiller des services spécifiques, vous pouvez configurer des règles d’échantillonnage de spans pour garantir que ces métriques sont basées sur 100 % du trafic de l’application, sans avoir à ingérer 100 % des traces pour toutes les demandes circulant à travers le service.
Cette fonctionnalité est disponible pour Datadog Agent v7.40.0+.
Remarque : Les règles d’échantillonnage de spans uniques ne peuvent pas être utilisées pour supprimer des spans qui sont conservés par l’échantillonnage basé sur l’en-tête, seulement pour conserver des spans supplémentaires qui sont supprimés par l’échantillonnage basé sur l’en-tête.
À partir de la bibliothèque de traçage version 1.7.0, pour les applications Java, définissez les règles d’échantillonnage de span par service et par nom d’opération avec la variable d’environnement DD_SPAN_SAMPLING_RULES.
Par exemple, pour collecter 100 % des spans du service nommé my-service, pour l’opération http.request, jusqu’à 50 spans par seconde :
@env DD_SPAN_SAMPLING_RULES=[{"service": "my-service", "name": "http.request", "sample_rate":1.0, "max_per_second": 50}]
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage Java.
À partir de la version v1.4.0, pour les applications Python, définissez les règles d’échantillonnage de span par service et par nom d’opération avec la variable d’environnement DD_SPAN_SAMPLING_RULES.
Par exemple, pour collecter 100% des spans du service nommé my-service, pour l’opération http.request, jusqu’à 50 spans par seconde :
@env DD_SPAN_SAMPLING_RULES=[{"service": "my-service", "name": "http.request", "sample_rate":1.0, "max_per_second": 50}]
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage Python.
À partir de la version v1.5.0, pour les applications Ruby, définissez les règles d’échantillonnage de span par service et par nom d’opération avec la variable d’environnement DD_SPAN_SAMPLING_RULES.
Par exemple, pour collecter 100% des spans du service nommé my-service, pour l’opération http.request, jusqu’à 50 spans par seconde :
@env DD_SPAN_SAMPLING_RULES=[{"service": "my-service", "name": "http.request", "sample_rate":1.0, "max_per_second": 50}]
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage Ruby.
À partir de la version v1.41.0, pour les applications Go, définissez les règles d’échantillonnage de span par service et par nom d’opération avec la variable d’environnement DD_SPAN_SAMPLING_RULES.
Par exemple, pour collecter 100% des spans du service nommé my-service, pour l’opération http.request, jusqu’à 50 spans par seconde :
@env DD_SPAN_SAMPLING_RULES=[{"service": "my-service", "name": "http.request", "sample_rate":1.0, "max_per_second": 50}]
À partir de la version v1.60.0, pour les applications Go, définissez les règles d’échantillonnage de span par ressource et par tags avec la variable d’environnement DD_SPAN_SAMPLING_RULES.
Par exemple, pour collecter 100% des spans du service pour la ressource POST /api/create_issue, pour le tag priority avec la valeur high :
@env DD_SPAN_SAMPLING_RULES=[{"resource": "POST /api/create_issue", "tags": { "priority":"high" }, "sample_rate":1.0}]
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage Go.
Pour les applications Node.js, définissez les règles d’échantillonnage de span par service et par nom d’opération avec la variable d’environnement DD_SPAN_SAMPLING_RULES.
Par exemple, pour collecter 100% des spans du service nommé my-service, pour l’opération http.request, jusqu’à 50 spans par seconde :
@env DD_SPAN_SAMPLING_RULES=[{"service": "my-service", "name": "http.request", "sample_rate":1.0, "max_per_second": 50}]
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage Node.js.
À partir de la version v0.77.0, pour les applications PHP, définissez les règles d’échantillonnage de span par service et par nom d’opération avec la variable d’environnement DD_SPAN_SAMPLING_RULES.
Par exemple, pour collecter 100% des spans du service nommé my-service, pour l’opération http.request, jusqu’à 50 spans par seconde :
@env DD_SPAN_SAMPLING_RULES=[{"service": "my-service", "name": "http.request", "sample_rate":1.0, "max_per_second": 50}]
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage PHP.
À partir de la version v0.1.0, pour les applications C++, définissez les règles d’échantillonnage span par service et par nom d’opération avec la variable d’environnement DD_SPAN_SAMPLING_RULES.
Par exemple, pour collecter 100% des spans du service nommé my-service, pour l’opération http.request, jusqu’à 50 spans par seconde :
@env DD_SPAN_SAMPLING_RULES=[{"service": "my-service", "name": "http.request", "sample_rate":1.0, "max_per_second": 50}]
À partir de la version v2.18.0, pour les applications .NET, définissez les règles d’échantillonnage span par service et par nom d’opération avec la variable d’environnement DD_SPAN_SAMPLING_RULES.
Par exemple, pour collecter 100% des spans du service nommé my-service, pour l’opération http.request, jusqu’à 50 spans par seconde :
#using powershell
$env:DD_SPAN_SAMPLING_RULES='[{"service": "my-service", "name": "http.request", "sample_rate":1.0, "max_per_second": 50}]'
#using JSON file
{
"DD_SPAN_SAMPLING_RULES": "[{\"service\": \"my-service\", \"name\": \"http.request\", \"sample_rate\": 1.0, \"max_per_second\": 50}]"
}
En savoir plus sur les contrôles d’échantillonnage dans la documentation de la bibliothèque de traçage .NET.
Spans ingérés par le produit
Traces RUM
ingestion_reason:rum
Une requête d’une application web ou mobile génère une trace lorsque les services backend sont instrumentés. L’intégration APM avec la surveillance des utilisateurs réels relie les requêtes des applications web et mobiles à leurs traces backend correspondantes afin de visualiser l’ensemble de vos données frontend et backend dans une vue unifiée.
À partir de la version 4.30.0 du SDK navigateur RUM, vous pouvez contrôler les volumes ingérés et conserver un échantillonnage des traces backend en configurant le paramètre d’initialisation traceSampleRate. Définissez traceSampleRate sur un nombre compris entre 0 et 100.
Si aucune valeur traceSampleRate n’est définie, par défaut, 100 % des traces provenant des requêtes du navigateur sont envoyées à Datadog.
De même, contrôlez le taux d’échantillonnage des traces dans d’autres SDK en utilisant des paramètres similaires :
| SDK | Paramètre | Version minimale |
|---|
| Navigateur | traceSampleRate | v4.30.0 |
| iOS | tracingSamplingRate | 1.11.0 Le taux d’échantillonnage est rapporté dans la page de contrôle d’ingestion depuis 1.13.0 |
| Android | traceSampleRate | 1.13.0 Le taux d’échantillonnage est rapporté dans la page de contrôle d’ingestion depuis 1.15.0 |
| Flutter | tracingSamplingRate | 1.0.0 |
| React Native | tracingSamplingRate | 1.0.0 Le taux d’échantillonnage est rapporté dans la page de contrôle d’ingestion depuis 1.2.0 |
Traces synthétiques
ingestion_reason:synthetics et ingestion_reason:synthetics-browser
Les tests HTTP et de navigateur génèrent des traces lorsque les services backend sont instrumentés. L’intégration APM avec les tests synthétiques relie vos tests synthétiques aux traces backend correspondantes. Naviguez d’un test qui a échoué à la cause racine du problème en consultant la trace générée par ce test.
Par défaut, 100 % des tests HTTP et de navigateur synthétiques génèrent des traces backend.
Autres produits
Certaines raisons d’ingestion supplémentaires sont attribuées aux spans générés par des produits Datadog spécifiques :
| Produit | Raison d’ingestion | Description du mécanisme d’ingestion |
|---|
| Serverless | lambda et xray | Vos traces reçues des Serverless applications tracées avec les bibliothèques de traçage Datadog ou l’intégration AWS X-Ray. |
| Protection des applications et des API | appsec | Traces ingérées à partir des bibliothèques de traçage Datadog et signalées par AAP comme une menace. |
| Observabilité des données : Surveillance des jobs | data_jobs | Traces ingérées depuis l’intégration Datadog Java Tracer Spark ou l’intégration Databricks. |
Mécanismes d’ingestion dans OpenTelemetry
ingestion_reason:otel
En fonction de votre configuration avec les SDK OpenTelemetry (en utilisant le Collecteur OpenTelemetry ou l’Agent Datadog), vous avez plusieurs façons de contrôler l’échantillonnage de l’ingestion. Voir Échantillonnage de l’ingestion avec OpenTelemetry pour des détails sur les options disponibles pour l’échantillonnage au niveau des SDK OpenTelemetry, du Collecteur OpenTelemetry et de l’Agent Datadog dans diverses configurations OpenTelemetry.
Lectures complémentaires
Documentation, liens et articles supplémentaires utiles: