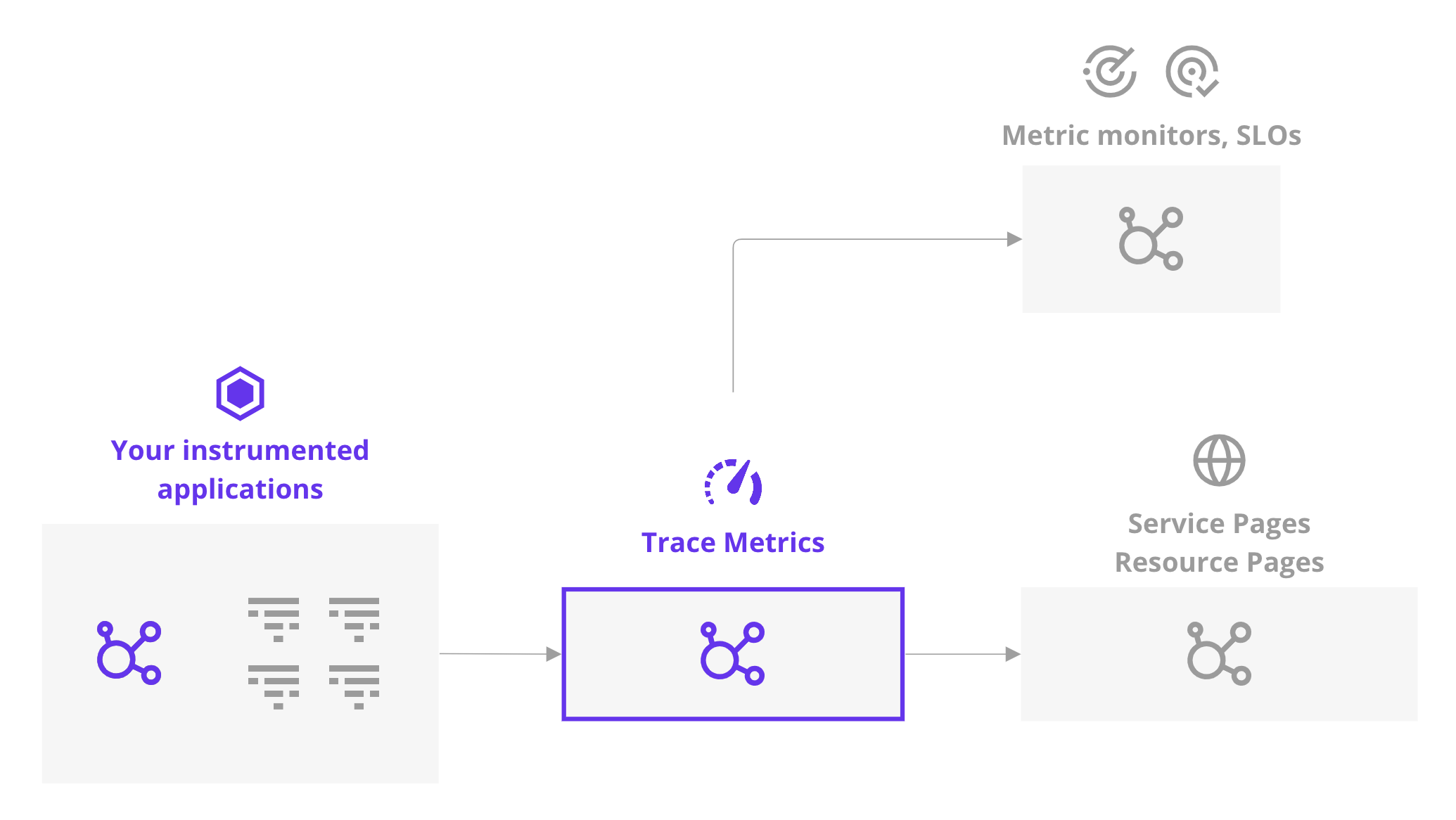
Présentation
Pour recueillir les métriques d’application de tracing, vous devez avoir activé la collecte des traces et instrumenté votre application.
Ces métriques capturent le nombre de requêtes, le nombre d’erreurs et les mesures de latence. Elles sont calculées pour l’ensemble du trafic de l’application, peu importe l’échantillonnage ces traces ingérées que vous avez configuré. Afin de bénéficier d’une visibilité complète sur le trafic de votre application, vous pouvez vous servir de ces métriques pour créer des dashboards, monitors et SLO. Vous pourrez ainsi identifier les erreurs potentielles concernant un service ou une ressource.
Remarque : si vos applications et services sont instrumentés avec des bibliothèques OpenTelemetry et que vous avez configuré l’échantillonnage au niveau du SDK ou au niveau du Collector, les métriques APM sont calculées en fonction de l’ensemble de données échantillonné.
Des métriques de trace sont générées pour les spans d’entrée de service et certaines opérations, selon le langage de l’intégration. Par exemple, l’intégration Django produit des métriques de trace à partir de spans qui représentent différentes opérations (1 span racine pour la requête Django, 1 pour chaque middleware et 1 pour la vue).
L’espace de nommage des métriques de trace est formaté comme suit :
trace.<NOM_SPAN>.<SUFFIXE_MÉTRIQUE>
Les paramètres sont définis comme suit :
<NOM_SPAN>- Le nom de l’opération ou
span.name (par exemple : redis.command, pylons.request, rails.request, mysql.query). <SUFFIXE_MÉTRIQUE>- Le nom de la métrique (par exemple :
hits, errors, apdex, duration). Référez-vous à la section ci-dessous. <TAGS>- Les tags des métriques de trace. Voici la liste des tags pris en charge :
env, service, version, resource, http.status_code, http.status_class et les tags de l’Agent Datadog (y compris le tag host et le deuxième tag primaire).
Remarque : les autres tags définis sur des spans ne sont pas disponibles en tant que tags sur les métriques de trace.
Suffixe des métriques
Hits
trace.<SPAN_NAME>.hits- Prérequis : cette métrique est disponible pour tous les services APM.
Description : elle représente le nombre de spans créées avec un nom spécifique (par exemple redis.command, pylons.request, rails.request, or mysql.query).
Type de métrique : COUNT.
Tags : env, service, version, resource, resource_name, http.status_code, tous les tags de host de l’Agent de host Datadog et le deuxième tag primaire. trace.<NOM_SPAN>.hits.by_http_status- Prérequis : cette métrique est disponible pour les services APM de type HTTP/WEB tant que des métadonnées HTTP sont fournies.
Description : elle représente le nombre de hits d’une span donnée, avec une répartition par code de statut HTTP.
Type de métrique : COUNT.
Tags : env, service, version, resource, resource_name, http.status_class, http.status_code, tous les tags de host de l’Agent de host Datadog et le deuxième tag primaire.
Distribution de la latence
trace.<NOM_SPAN>- Prérequis : cette métrique est disponible pour tous les services de l’APM.
Description : elle représente la distribution de latence pour l’ensemble des services, ressources et versions ainsi que tous les environnements et deuxièmes tags primaires.
Type de métrique : DISTRIBUTION.
Tags : env, service,version, resource, resource_name, http.status_code, synthetics et le deuxième tag primaire.
Erreurs
trace.<NOM_SPAN>.errors- Prérequis : cette métrique est disponible pour tous les services APM.
Description : elle représente le nombre d’erreurs d’une span donnée.
Type de métrique : COUNT.
Tags : env, service, version, resource, resource_name, http.status_code, tous les tags de host de l’Agent de host Datadog et le deuxième tag primaire. trace.<NOM_SPAN>.errors.by_http_status- Prérequis : cette métrique est disponible pour tous les services APM.
Description : elle représente le nombre d’erreurs d’une span donnée.
Type de métrique : COUNT.
Tags : env, service, version, resource, http.status_class, http.status_code, tous les tags de host de l’Agent de host Datadog et le deuxième tag primaire.
Apdex
trace.<NOM_SPAN>.apdex- Prérequis : cette métrique est disponible pour tous les services APM de type HTTP/ ou basés sur le web.
Description : elle mesure le score Apdex pour chaque service Web.
Type de métrique : GAUGE.
Tags : env, service, version, resource / resource_name, version, synthetics et le deuxième tag primaire.
Durée
trace.<SPAN_NAME>.duration- Prérequis : cette métrique est disponible pour tous les services APM.
Description : correspond à la durée totale mesurée pour un groupe de spans dans un intervalle de temps, y compris les spans enfants détectées par le service de collecte. Dans la plupart des cas, Datadog recommande d’utiliser la distribution de la latence pour calculer la latence moyenne ou les centiles. Pour calculer la latence moyenne avec des filtres basés sur des tags, vous pouvez utiliser cette métrique avec la formule suivante :
sum:trace.<SPAN_NAME>.duration{<FILTER>}.rollup(sum).fill(zero) / sum:trace.<SPAN_NAME>.hits{<FILTER>}
Cette métrique ne prend pas en charge les agrégations par centile. Lisez la section relative à la distribution de la latence pour en savoir plus.
Type de métrique : GAUGE.
Tags : env, service, resource, http.status_code tous les tags de l’Agent pour host Datadog et le deuxième tag primaire.
Duration by
trace.<NOM_SPAN>.duration.by_http_status- Prérequis : cette métrique est disponible pour les services APM HTTP/WEB tant que des métadonnées HTTP sont fournies.
Description : elle correspond à la durée totale mesurée pour un groupe de spans, pour chaque statut HTTP. Plus précisément, il s’agit de la proportion de la durée de traitement mesurée pour toutes les spans lors d’un intervalle donné et pour un statut HTTP précis, y compris le temps passé à attendre les processus enfant.
Type de métrique : GAUGE.
Tags : env, service, resource, http.status_class, http.status_code, tous les tags de host de l’Agent de host Datadog et le deuxième tag primaire.
Impact de l’échantillonnage sur les métriques de traces
Dans la plupart des cas, les métriques de traces sont calculés sur la base de l’ensemble du trafic de l’application. Toutefois, dans certaines configurations d’échantillonnage de l’ingestion des traces, les métriques ne représentent qu’un sous-ensemble de toutes les requêtes.
Échantillonnage côté application
Certaines bibliothèques de tracing prennent en charge l’échantillonnage côté application, ce qui réduit le nombre de spans avant leur envoi vers l’Agent Datadog. Par exemple, la bibliothèques de tracing Ruby propose un échantillonnage côté application afin d’améliorer les performances. Cependant, cela peut affecter les métriques de traces, car l’Agent Datadog a besoin de tous les spans pour calculer les métriques avec précision.
Très peu de bibliothèques de tracing prennent en charge ce paramètre, et son utilisation n’est généralement pas conseillée.
Échantillonnage OpenTelemetry
Les mécanismes d’échantillonnage natifs du SDK OpenTelemetry réduisent le nombre de spans envoyées au Collector Datadog, ce qui se traduit par des métriques de traces échantillonnées et potentiellement imprécises.
Échantillonnage XRay
Les spans XRay sont échantillonnées avant d’être envoyées à Datadog, ce qui signifie que les métriques de traces ne reflètent peut-être pas tout le trafic.
Pour aller plus loin
Documentation, liens et articles supplémentaires utiles: