Ce tutoriel détaille les étapes d’activation du tracing sur un exemple d’application Java installée dans un cluster sur AWS Elastic Container Service (ECS) avec Fargate. Pour cet exemple, l’Agent Datadog est également installé dans le cluster.
Pour d’autres scénarios, notamment en cas d’activation du tracing sur un host, dans un conteneur, dans une autre infrastructure cloud, et pour des applications écrites dans d’autres langages, consultez les autres tutoriels d’activation du tracing. Certains de ces autres tutoriels, par exemple ceux utilisant des conteneurs ou EKS, abordent les différences observées dans Datadog entre l’instrumentation automatique et personnalisée. Ce tutoriel part directement d’un exemple basé sur une instrumentation personnalisée complète.
Ce tutoriel aborde également des concepts AWS de niveau intermédiaire, ce qui signifie que vous devez maîtriser un minimum les applications et les réseaux AWS. Si vous débutez avec AWS et essayez de vous familiariser avec les bases de la configuration d’APM Datadog, référez-vous plutôt à l’un des tutoriels reposant sur des hosts ou des conteneurs.
Référez-vous à la section Tracer des applications Java pour consulter la documentation complète relative à la configuration du tracing pour Java.
Un référentiel Amazon ECR pour l’hébergement d’images
Un utilisateur AWS IAM avec l’autorisation AdministratorAccess ; vous devez ajouter le profil à votre fichier d’identifiants local à l’aide de la clé d’accès et de la clé d’accès secrète (pour en savoir plus, consultez la section Utiliser le fichier d’identifiants AWS et les profils d’identifiants)
Installer l’exemple d’application Java
L’exemple de code pour ce tutoriel se trouve sur GitHub, à l’adresse suivante : github.com/DataDog/apm-tutorial-java-host. Pour commencer, dupliquez le référentiel :
Le référentiel contient une application Java dotée de plusieurs services qui est préconfigurée pour être exécutée au sein de conteneurs Docker. Les fichiers YAML docker-compose permettant la création des conteneurs se situent dans le référentiel docker. Ce tutoriel utilise le fichier service-docker-compose-ECS.yaml, qui génère les conteneurs pour l’application.
Dans chacun des référentiels notes et calendar, vous trouverez deux ensembles de Dockerfiles permettant de générer les applications avec Maven ou Gradle. Ce tutoriel se base sur le build Maven, mais si vous maîtrisez davantage Gradle, vous pouvez l’utiliser en appliquant les modifications correspondantes pour générer des commandes.
L’exemple d’application Java comporte plusieurs services avec deux API, une pour le service notes et une autre pour le service calendar. Le service notes possède les endpoints GET, POST, PUT et DELETE pour les notes stockées dans une base de données H2 en mémoire. Le service calendar peut recevoir une requête et renvoyer une date aléatoire à utiliser dans une note. Les deux applications possèdent leurs propres images Docker associées et sont déployées sur Amazon ECS en tant que services distincts. Chaque application possède ses propres tâches et conteneurs respectifs. ECS extrait les images d’ECR, un référentiel pour les images d’application vers lequel vous publiez les images après le processus de build.
Configuration initiale d’ECS
L’application nécessite une configuration initiale, notamment l’ajout de votre profil AWS (déjà configuré avec les autorisations appropriées pour créer un cluster ECS et lire les données d’ECR), de la région AWS et du référentiel Amazon ECR.
Ouvrez terraform/Fargate/global_constants/variables.tf. Remplacez les valeurs de variable ci-dessous par vos informations de compte AWS.
output "aws_profile" {
value = "<PROFIL_AWS>"
sensitive = true
}
output "aws_region" {
value = "<REGION_AWS>"
sensitive = true
}
output "aws_ecr_repository" {
value = "<URL_RÉFÉRENTIEL_AWS_ECR>"
sensitive = true
}
Générer et importer les images de l’application
Si vous ne maîtrisez pas Amazon ECR, un registre d’images de conteneur, il est conseillé de lire la section Utiliser Amazon ECR avec la AWS CLI de la documentation AWS.
Dans le référentiel /docker de l’exemple de projet, exécutez les commandes suivantes :
Authentifiez-vous auprès d’ECR en fournissant votre nom d’utilisateur et votre mot de passe dans cette commande :
Votre application (sans le tracing activé) est conteneurisée et peut être récupérée par ECS.
Déployer l’application
Lancez l’application et envoyez des requêtes sans tracing. Dès lors que vous comprenez le fonctionnement de l’application, vous pouvez l’instrumenter avec la bibliothèque de tracing et l’Agent Datadog.
Pour commencer, procédez au déploiement sur Amazon ECS à l’aide d’un script Terraform :
Dans le référentiel terraform/Fargate/Uninstrumented, exécutez les commandes suivantes :
terraform init
terraform apply
terraform state show 'aws_alb.application_load_balancer'
Remarque : si la commande terraform apply renvoie un message de bloc CIDR, cela signifie que le script d’obtention de votre adresse IP n’a pas fonctionné sur votre machine locale. Pour corriger cela, définissez une valeur manuellement dans le fichier terraform/Fargate/Uninstrumented/security.tf. Au sein du bloc ingress du load_balancer_security_group, mettez en commentaire une autre ligne cidr_blocks et remplacez l’exemple de ligne qui n’est plus en commentaire par l’adresse IP4 de votre machine.
Notez le nom DNS du répartiteur de charge. Ce domaine de base servira dans les appels d’API vers l’exemple d’application. Patientez quelques minutes, le temps que les instances démarrent.
Ouvrez un autre terminal et envoyez des requêtes d’API pour entraîner l’application. L’application notes est une API REST qui stocke les données dans une base de données H2 en mémoire exécutée sur le même conteneur. Envoyez-lui quelques commandes :
curl -X GET 'BASE_DOMAIN:8080/notes'
[]
curl -X POST 'BASE_DOMAIN:8080/notes?desc=hello'
{"id":1,"description":"hello"}
curl -X GET 'BASE_DOMAIN:8080/notes?id=1'
{"id":1,"description":"hello"}
curl -X GET 'BASE_DOMAIN:8080/notes'
[{"id":1,"description":"hello"}]
curl -X PUT 'BASE_DOMAIN:8080/notes?id=1&desc=UpdatedNote'
{"id":1,"description":"UpdatedNote"}
curl -X GET 'BASE_DOMAIN:8080/notes'
[{"id":1,"description":"UpdatedNote"}]
curl -X POST 'BASE_DOMAIN:8080/notes?desc=NewestNote&add_date=y'
{"id":2,"description":"NewestNote with date 12/02/2022."}
Cette commande appelle à la fois les services notes et calendar.
Après avoir testé l’application, exécutez la commande suivante pour l’arrêter et nettoyer les ressources AWS de manière à pouvoir activer le tracing :
terraform destroy
Activer le tracing
Maintenant que vous disposez d’une application Java fonctionnelle, configurez-la de façon à activer le tracing.
Modifiez le dockerfile afin d’ajouter le package de tracing Java dont l’application a besoin pour générer des traces. Ouvrez le fichier notes/dockerfile.notes.maven et supprimez la mise en commentaire de la ligne qui télécharge dd-java-agent :
RUN curl -Lo dd-java-agent.jar 'https://dtdg.co/latest-java-tracer'
Au sein du même fichier notes/dockerfile.notes.maven, mettez en commentaire la ligne ENTRYPOINT permettant d’exécuter l’application sans le tracing. Supprimez ensuite la mise en commentaire de la ligne ENTRYPOINT permettant d’exécuter l’application avec le tracing :
Répétez cette étape pour le service calendar. Ouvrez calendar/dockerfile.calendar.maven et mettez en commentaire la ligne ENTRYPOINT permettant d exécuter l’application sans le tracing. Supprimez ensuite la mise en commentaire de la ligne ENTRYPOINT permettant d’exécuter l’application avec le tracing :
L’instrumentation automatique est désormais configurée pour les deux services.
Remarque : les flags de ces exemples de commandes, notamment le taux d'échantillonnage, ne sont pas nécessairement adaptés aux environnements en dehors de ce tutoriel. Pour en savoir plus sur les éléments à utiliser dans votre environnement réel, lisez la rubrique Configuration du tracing.
L’instrumentation automatique est une fonctionnalité pratique, mais il se peut que vous ayez besoin de spans plus précises. L’API Java DD Trace de Datadog vous permet de spécifier des spans au sein de votre code à l’aide d’annotations ou de code. Ajoutez des annotations au code à tracer au sein de quelques exemples de méthodes.
Ouvrez /notes/src/main/java/com/datadog/example/notes/NotesHelper.java. Cet exemple contient déjà du code en commentaire qui décrit les différentes méthodes de configuration du tracing personnalisé dans le code.
Supprimez la mise en commentaire des lignes qui importent les bibliothèques pour autoriser le tracing manuel :
Supprimez la mise en commentaire des lignes qui tracent manuellement les deux processus publics. Elles reposent sur l’utilisation d’annotations @Trace pour spécifier des informations telles que operationName et resourceName dans une trace :
Vous pouvez également créer une span distincte pour un bloc de code spécifique dans l’application. Au sein de la span, ajoutez des tags de nom de service et de ressource, ainsi que des tags de gestion des erreurs. L’ajout de ces tags permet de générer un flamegraph qui présente la span et les métriques dans des visualisations Datadog. Supprimez la mise en commentaire des lignes qui tracent manuellement la méthode privée :
Tracertracer=GlobalTracer.get();// Tags can be set when creating the spanSpanspan=tracer.buildSpan("manualSpan1").withTag(DDTags.SERVICE_NAME,"NotesHelper").withTag(DDTags.RESOURCE_NAME,"privateMethod1").start();try(Scopescope=tracer.activateSpan(span)){// Tags can also be set after creationspan.setTag("postCreationTag",1);Thread.sleep(30);Log.info("Hello from the custom privateMethod1");
Faites de même pour les lignes qui définissent des tags sur les erreurs :
}catch(Exceptione){// Set error on spanspan.setTag(Tags.ERROR,true);span.setTag(DDTags.ERROR_MSG,e.getMessage());span.setTag(DDTags.ERROR_TYPE,e.getClass().getName());finalStringWritererrorString=newStringWriter();e.printStackTrace(newPrintWriter(errorString));span.setTag(DDTags.ERROR_STACK,errorString.toString());Log.info(errorString.toString());}finally{span.finish();}
Mettez à jour votre build Maven en ouvrant notes/pom.xml et en supprimant la mise en commentaire des lignes qui configurent les dépendances pour le tracing manuel. La bibliothèque dd-trace-api est utilisée pour les annotations @Trace. tandis que opentracing-util et opentracing-api servent à créer manuellement des spans.
Ajoutez l’Agent Datadog à chacune des définitions de tâche notes et calendar, en veillant à ajouter un Agent dans un conteneur aux côtés de chaque tâche AWS au lieu de l’installer n’importe où. Ouvrez terraform/Fargate/Instrumented/main.tf, puis assurez-vous que cet exemple comporte déjà les configurations de base nécessaires à l’exécution de l’Agent Datadog sur ECS Fargate et à la collecte de traces. Il doit comporter la clé d’API (configurée à l’étape suivante). De plus, ECS Fargate et APM doivent être activés. La définition est fournie dans les deux tâches (notes et calendar).
Spécifiez la variable de clé d’API avec une valeur. Ouvrez terraform/Fargate/global_constants/variables.tf, supprimez la mise en commentaire de la section output "datadog_api_key", puis fournissez la clé d’API Datadog de votre organisation.
Le tagging de service unifié identifie les services tracés sur différentes versions et différents environnements de déploiement. Ainsi, ces services peuvent être mis en corrélation au sein de Datadog, et vous pouvez les rechercher et appliquer des filtres basés sur ces services. Les trois variables d’environnement utilisées pour le tagging de service unifié sont DD_SERVICE, DD_ENV et DD_VERSION. Pour les applications déployées sur ECS, ces variables d’environnement sont définies au sein de la définition de tâche pour les conteneurs.
Dans le cadre de ce tutoriel, ces variables d’environnement sont déjà définies pour les applications notes et calendar au sein du fichier /terraform/Fargate/Instrumented/main.tf. Voici un exemple pour notes :
Les étiquettes Docker pour les tags de service unifié service, env et version sont également définies. Vous pouvez ainsi recueillir des métriques Docker une fois votre application exécutée.
Configuration du tracing
La bibliothèque de tracing Java tire parti de l’Agent intégré et des fonctionnalités de surveillance de Java. Le flag -javaagent:../dd-java-agent.jar présent dans le Dockerfile indique à la JVM l’emplacement de la bibliothèque de tracing Java, afin qu’elle puisse être exécutée en tant qu’Agent Java. Pour en savoir plus sur les Agents Java, consultez le site https://www.baeldung.com/java-instrumentation (en anglais).
Le flag dd.trace.sample.rate définit le taux d’échantillonnage de cette application. La commande ENTRYPOINT dans le fichier Dockerfile définit sa valeur sur 1, ce qui signifie que toutes les requêtes de service sont envoyées au backend Datadog à des fins d’analyse et d’affichage. Pour une application de test avec un faible volume, cette configuration fonctionne parfaitement. En revanche, elle n’est pas compatible avec un environnement de production ou un environnement avec un nombre de requêtes élevé, car cela générerait un énorme volume de données. Échantillonnez plutôt une partie de vos requêtes, en choisissant une valeur entre 0 et 1. Par exemple, -Ddd.trace.sample.rate=0.1 envoie des traces à Datadog pour 10 % de vos requêtes. Pour en savoir plus, consultez la documentation relative aux paramètres de configuration du tracing et aux mécanismes d’échantillonnage.
Le flag du taux d’échantillonnage spécifié dans les commandes précède le flag -jar. En effet, il s’agit d’un paramètre destiné à la Java Virtual Machine, et non à votre application. Assurez-vous de spécifier le flag au bon endroit lorsque vous ajoutez l’Agent Java à votre application.
Générer à nouveau l’image de l’application et l’importer
Votre application dotée de plusieurs services avec le tracing activé est conteneurisée et peut être récupérée par ECS.
Lancer l’application pour visualiser les traces
Déployez à nouveau l’application et entraînez l’API :
Déployez à nouveau l’application sur Amazon ECS à l’aide des mêmes commandes que précédemment, mais avec cette fois-ci la version instrumentée des fichiers de configuration. Dans le référentiel terraform/Fargate/Instrumented, exécutez les commandes suivantes :
terraform init
terraform apply
terraform state show 'aws_alb.application_load_balancer'
Notez le nom DNS du répartiteur de charge. Ce domaine de base servira dans les appels d’API vers l’exemple d’application.
Patientez quelques minutes, le temps que les instances démarrent. Attendez quelques minutes supplémentaires pour vous assurer que les conteneurs des applications sont prêts. Exécutez quelques commandes curl pour entraîner l’application instrumentée :
curl -X GET 'BASE_DOMAIN:8080/notes'
[]
curl -X POST 'BASE_DOMAIN:8080/notes?desc=hello'
{"id":1,"description":"hello"}
curl -X GET 'BASE_DOMAIN:8080/notes?id=1'
{"id":1,"description":"hello"}
curl -X GET 'BASE_DOMAIN:8080/notes'
[{"id":1,"description":"hello"}]
curl -X PUT 'BASE_DOMAIN:8080/notes?id=1&desc=UpdatedNote'
{"id":1,"description":"UpdatedNote"}
curl -X GET 'BASE_DOMAIN:8080/notes'
[{"id":1,"description":"hello"}]
curl -X POST 'BASE_DOMAIN:8080/notes?desc=NewestNote&add_date=y'
{"id":2,"description":"NewestNote with date 12/02/2022."}
Cette commande appelle à la fois les services notes et calendar.
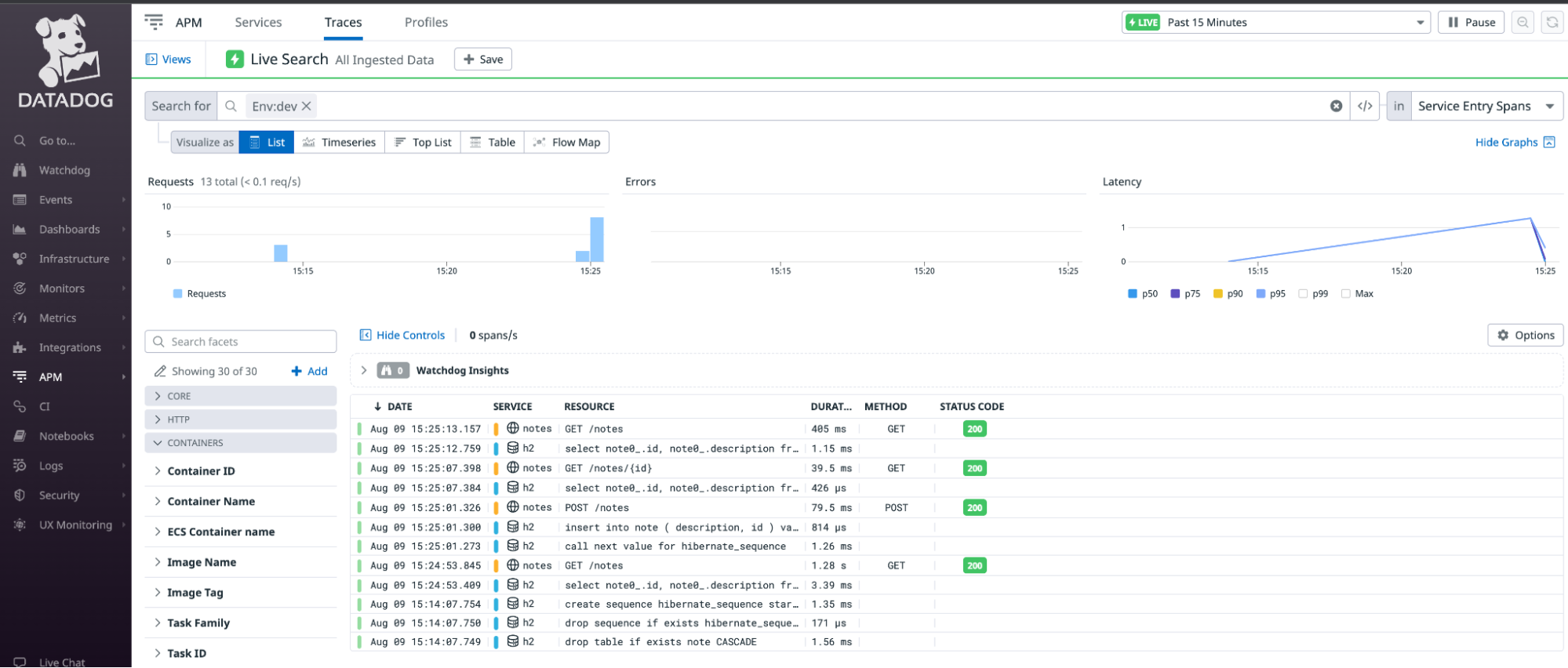
Patientez quelques instants, puis accédez à APM > Traces dans Datadog pour consulter la liste des traces correspondant à vos appels d’API :
h2 correspond à la base de données en mémoire intégrée de ce tutoriel, et notes à l’application Spring Boot. La liste des traces affiche toutes les spans, leur heure d’initialisation, la ressource suivie avec la span, ainsi que la durée du processus.
Si aucune trace ne s’affiche après quelques minutes, effacez les filtres actifs dans le champ Traces Search (il peut arriver qu’une variable d’environnement telle que ENV soit filtrée alors que vous ne l’utilisez pas).
Examiner une trace
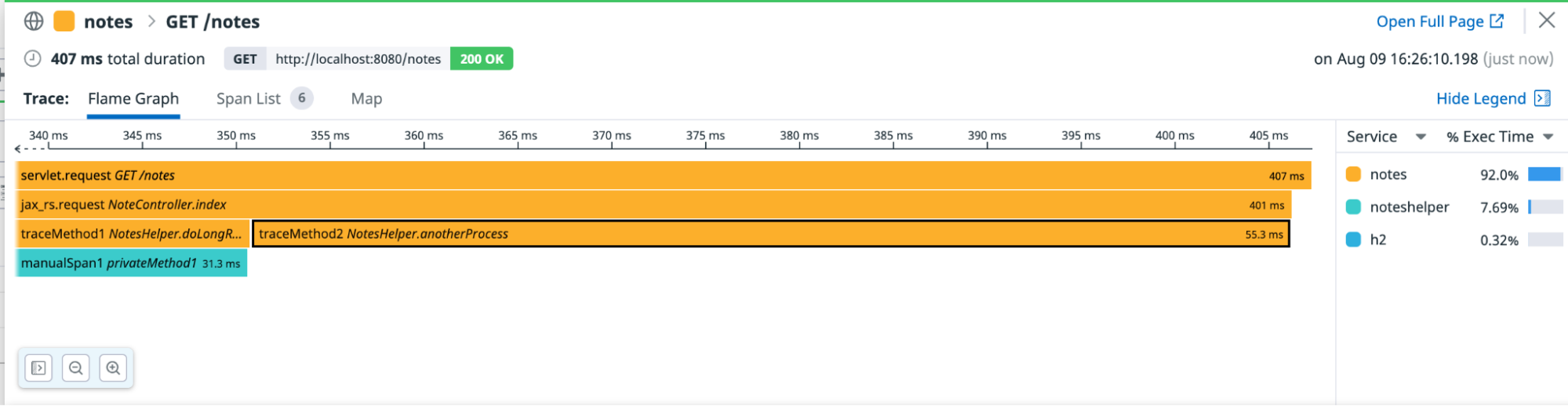
Sur la page Traces, cliquez sur une trace POST /notes. Cela affiche un flamegraph décrivant la durée de chaque span ainsi que les autres spans présentes avant la finalisation d’une span. La barre située en haut du graphique représente la span que vous avez sélectionnée sur l’écran précédent (dans le cas présent, le point d’entrée initial dans l’application notes).
La largeur d’une barre indique la durée totale de la span. Une barre moins large représente une span finalisée pendant le cycle de vie d’une barre plus large.
Sur le Trace Explorer, cliquez sur l’une des requêtes GET pour afficher un flamegraph similaire à ce qui suit :
La privateMethod autour de laquelle vous avez créé une span manuelle s’affiche sous la forme d’un bloc distinct des autres appels et dans une autre couleur. Les autres méthodes pour lesquelles vous avez utilisé l’annotation @Trace s’affichent sous le même service et dans la même couleur que la requête GET, qui correspond à l’application notes. L’instrumentation personnalisée s’avère très utile lorsque des parties essentielles du code doivent être mises en évidence et surveillées.
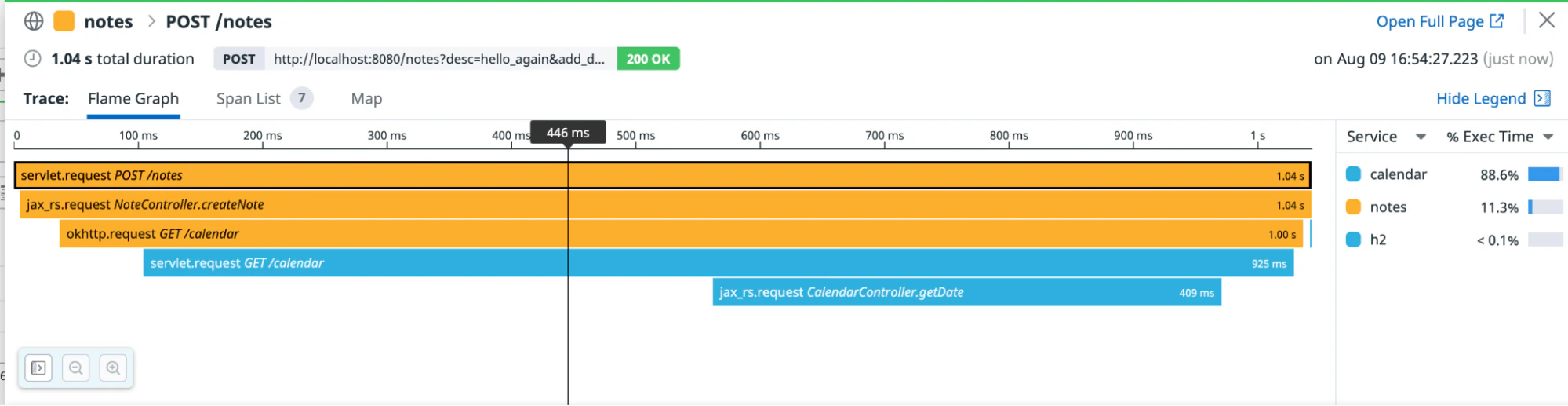
Le tracing d’un service unique constitue un bon point de départ, mais le véritable intérêt du tracing réside dans la capacité à visualiser le flux des requêtes dans vos services. On parle alors de tracing distribué. Cliquez sur la trace du dernier appel d’API, celui qui a ajouté une date à la note, pour visualiser une trace distribuée entre les deux services :
Veuillez noter que vous n’avez modifié aucun élément de l’application notes. Datadog instrumente automatiquement la bibliothèque okHttp utilisée pour envoyer l’appel HTTP du service notes vers le service calendar, ainsi que la bibliothèque Jetty utilisée pour écouter les requêtes HTTP dans les services notes et calendar. Cette instrumentation permet la transmission des informations de trace d’une application à une autre, ainsi que l’enregistrement d’une trace distribuée.
Une fois que vous avez terminé, nettoyez toutes les ressources et supprimez les déploiements :
Si vous ne recevez pas les traces comme prévu, configurez le mode debugging pour le traceur Java. Consultez la rubrique Activer le mode debugging pour en savoir plus.
Pour aller plus loin
Documentation, liens et articles supplémentaires utiles: