Tracing distribué avec des applications sans serveur AWS Lambda
Associez vos traces sans serveur à vos métriques pour permettre à Datadog de vous offrir une vue d’ensemble détaillée et contextualisée des performances de votre application. Compte tenu de la nature distribuée des applications sans serveur, vous pouvez ainsi résoudre plus efficacement les problèmes de performance.
Les bibliothèques de tracing Python, Node.js, Ruby, Go, Java et .NET Datadog prennent en charge le tracing distribué pour AWS Lambda.
Envoyer des traces à partir de votre application sans serveur
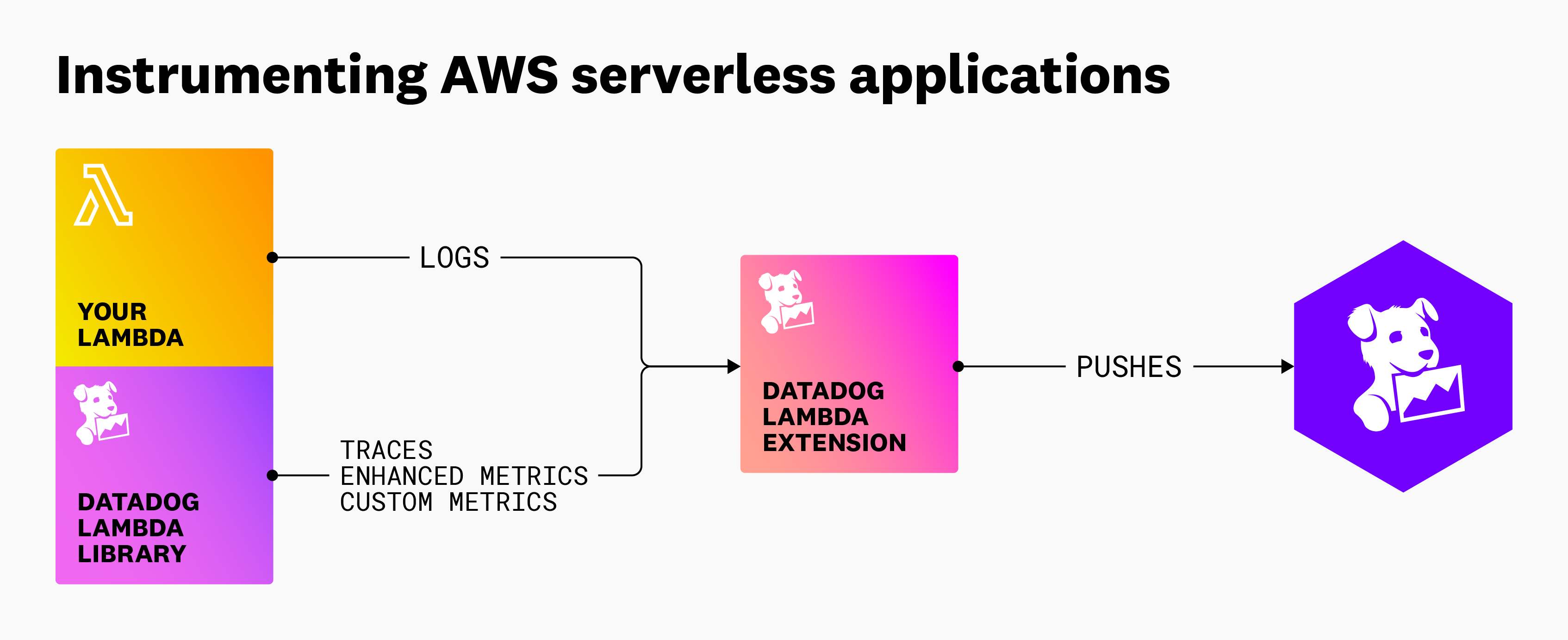
Les bibliothèques de tracing Python, Node.js, Ruby, Go, Java et .NET Datadog prennent en charge le tracing distribué pour AWS Lambda. Vous pouvez installer le traceur en suivant les instructions d’installation. Si vous avez déjà installé l’extension, vérifiez que la variable d’environnement DD_ENABLE_ENABLED est définie sur true.
Recommandations de runtime
Python et Node.js
La bibliothèque Lambda Datadog et les bibliothèques de tracing pour Python et Node.js prennent en charge les fonctionnalités suivantes :
- Corrélation automatique des logs Lambda et des traces avec l’ID de trace et l’injection de traces
- Installation sans modification du code à l’aide des intégrations Serverless Framework, AWS SAM et AWS CDK
- Tracing des requêtes HTTP appelant des conteneurs ou des fonctions Lambda en aval
- Tracing des appels Lambda consécutifs effectués avec AWS SDK.
- Tracing des démarrages à froid
- Tracing des appels Lambda asynchrones via AWS Managed Services
- API Gateway
- SQS
- SNS
- Intégration directe de SNS et SQS
- Kinesis
- EventBridge
- Tracing de dizaines de bibliothèques supplémentaires Python et Node.js prêtes à l’emploi
Pour les applications Python et Node.js sans serveur, Datadog vous conseille d’installer les bibliothèques de tracing Datadog.
Vous souhaitez tracer d’autres ressources sans serveur ? Créez une demande de fonctionnalité sur cette page.
Ruby
La bibliothèque Lambda Datadog et les bibliothèques de tracing pour Ruby prennent en charge les fonctionnalités suivantes :
- Corrélation automatique des logs Lambda et des traces avec l’ID de trace et l’injection de traces
- Tracing des requêtes HTTP appelant des conteneurs ou des fonctions Lambda en aval
- Tracing de dizaines de bibliothèques supplémentaires Ruby prêtes à l’emploi
Vous pouvez tracer vos fonctions sans serveur dans Datadog grâce aux bibliothèques de tracing Datadog.
Vous souhaitez tracer d’autres ressources sans serveur ? Créez une demande de fonctionnalité sur cette page.
Go
La bibliothèque Lambda Datadog et les bibliothèques de tracing pour Go prennent en charge les fonctionnalités suivantes :
- Corrélation manuelle des logs Lambda et des traces avec l’ID de trace et l’injection de traces
- Tracing des requêtes HTTP appelant des conteneurs ou des fonctions Lambda en aval
- Tracing de dizaines de bibliothèques supplémentaires Go prêtes à l’emploi
Pour les applications Go sans serveur, Datadog vous conseille d’installer les bibliothèques de tracing Datadog.
Vous souhaitez tracer d’autres ressources sans serveur ? Créez une demande de fonctionnalité sur cette page.
Java
La bibliothèque Lambda Datadog et les bibliothèques de tracing pour Java prennent en charge les fonctionnalités suivantes :
- Mise en corrélation des logs Lambda et des traces avec l’ID de trace et l’injection de traces (voir la section Associer vos logs Java à vos traces pour en savoir plus)
- Tracing des requêtes HTTP appelant des conteneurs ou des fonctions Lambda en aval
- Tracing de dizaines de bibliothèques supplémentaires Java prêtes à l’emploi
Pour les applications Java sans serveur, Datadog vous conseille d’installer les bibliothèques de tracing Datadog.
Vous souhaitez partager votre avis sur les bibliothèques de tracing Datadog pour les fonctions Lambda Java ? N’hésitez pas à rejoindre le canal #serverless de la communauté Slack Datadog pour participer aux discussions.
.NET
La bibliothèque de tracing pour .NET prend en charge les fonctionnalités suivantes :
- Tracing des requêtes HTTP appelant des conteneurs ou des fonctions Lambda en aval
- Tracing de dizaines de bibliothèques supplémentaires .NET prêtes à l’emploi
Pour les applications .NET sans serveur, Datadog vous conseille d’installer les bibliothèques de tracing Datadog.
En savoir plus sur le tracing via des applications sans serveur Azure .NET.
Environnements hybrides
Si vous avez installé les bibliothèques de tracing Datadog (dd-trace) sur vos fonctions Lambda et vos hosts, vos traces dressent automatiquement un tableau complet des requêtes qui franchissent les limites de votre infrastructure, qu’il s’agisse de fonctions AWS Lambda, de hosts sur site ou de services gérés.
Si vous avez installé dd-trace sur vos hosts avec l’Agent Datadog, et si le tracing de vos fonctions sans serveur passe par AWS X-Ray, il est nécessaire de fusionner les traces pour afficher une trace unique et associée dans votre infrastructure. Consultez la section Fusion de traces sans serveur pour en savoir plus sur la fusion de traces entre dd-trace et AWS X-Ray.
L’intégration Datadog/AWS X-Ray fournit uniquement des traces pour les fonctions Lambda. Consultez la documentation relative à la solution APM Datadog pour en savoir plus sur le tracing dans des environnements basés sur des conteneurs ou des hosts.
Profiler vos fonctions Lambda (fonctionnalité en bêta publique)
Durant la version bêta, le profiling est disponible gratuitement.
Le profileur en continu de Datadog est disponible en version bêta pour la version 4.62.0 de Python et les versions 62 et ultérieures de la couche. Pour activer cette fonctionnalité facultative, définissez la variable d’environnement DD_PROFILING_ENABLED sur true.
Le profileur en continu fonctionne en générant un thread qui s’active régulièrement afin de générer un snapshot du processeur et de l’ensemble du code Python exécuté. Ce snapshot peut inclure le profileur lui-même. Si vous voulez que le profileur s’ignore, définissez DD_PROFILING_IGNORE_PROFILER sur true.
Fusion de traces
Cas d’utilisation
Datadog vous recommande d’utiliser uniquement la bibliothèque de tracing APM Datadog (dd-trace). Cependant, dans certaines situations particulières, les utilisateurs peuvent combiner le tracing Datadog et AWS X-Ray à l’aide de la fusion de traces. La fusion de traces est disponible pour les fonctions et AWS Lambda Node.js et Python. Si vous ne savez pas quelle bibliothèque de tracing utiliser, découvrez comment choisir votre bibliothèque de tracing.
Il existe deux scénarios justifiant l’instrumentation des bibliothèques de tracing dd-trace et AWS X-Ray :
- Dans un environnement AWS sans serveur, vous effectuez déjà le tracing de vos fonctions Lambda avec
dd-trace. De plus, un tracing actif d’AWS X-Ray est requis pour les services AWS gérés, comme AppSync et Step Functions. Or, vous devez visualiser les spans dd-trace et AWS X-Ray au sein d’une unique trace. - Dans un environnement hybride comprenant des fonctions Lambda et des hosts,
dd-trace instrumente vos hosts, tandis qu’AWS X-Ray instrumente vos fonctions Lambda. Or, vous devez visualiser les traces connectées pour les transactions de l’ensemble de vos fonctions Lambda et de vos hosts.
Remarque : la fusion des traces peut entraîner une augmentation de vos coûts. Les spans X-Ray restent disponibles dans vos traces fusionnées pendant une durée de deux à cinq minutes. Dans la plupart des cas, Datadog vous conseille d’utiliser une seule bibliothèque de tracing. Découvrez comment choisir votre bibliothèque de tracing.
Voici des instructions de configuration pour les deux scénarios évoqués ci-dessus :
Fusion de traces dans un environnement AWS sans serveur
AWS X-Ray propose à la fois un service AWS backend (le tracing actif d’AWS X-Ray) et un ensemble de bibliothèques client. Lorsque le service AWS backend est activé indépendamment dans la console Lambda, vous disposez des spans Initialization et Invocation pour vos fonctions AWS Lambda. Vous pouvez également activer le tracing actif d’AWS X-Ray depuis les consoles API Gateway et Step Function.
Le SDK AWS X-Ray et les bibliothèques client de l’APM Datadog (dd-trace) accèdent directement à la fonction pour ajouter des métadonnées et des spans aux appels en aval. Si vous utilisez dd-trace pour effectuer le tracing au niveau du gestionnaire, voici à quoi ressemble la configuration finale :
- Vous avez activé le tracing actif d’AWS X-Ray sur vos fonctions Lambda depuis la console AWS Lambda, ainsi que l’intégration Datadog/AWS X-Ray.
- Vous avez instrumenté vos fonctions Lambda avec la solution APM Datadog (
dd-trace) en suivant les instructions d’installation pour votre runtime Lambda. - Les bibliothèques tierces sont automatiquement patchées par
dd-trace ; les bibliothèques client AWS X-Ray n’ont donc pas besoin d’être installées. - Vous avez défini la variable d’environnement
DD_MERGE_XRAY_TRACES sur true (ou la variable d’environnement DD_MERGE_DATADOG_XRAY_TRACES pour Ruby) sur vos fonctions Lambda afin de fusionner les traces X-Ray et dd-trace.
Si vous avez installé les bibliothèques de tracing Datadog (dd-trace) sur vos fonctions Lambda et vos hosts, vos traces dressent automatiquement un tableau complet des requêtes qui franchissent les limites de votre infrastructure, qu’il s’agisse de fonctions AWS Lambda, de hosts sur site ou de services gérés.
Si vous avez installé dd-trace sur vos hosts avec l’Agent Datadog, et si le tracing de vos fonctions sans serveur Node.js ou Python passe par AWS X-Ray, voici à quoi ressemble la configuration finale :
- Vous avez installé l’intégration AWS X-Ray pour le tracing de vos fonctions Lambda. Par la même occasion, vous avez activé le tracing actif d’AWS X-Ray et installé les bibliothèques client X-Ray.
- Vous avez installé la bibliothèque Lambda Datadog pour votre runtime Lambda et défini la variable d’environnement
DD_TRACE_ENABLED sur false. - La solution APM Datadog est configurée sur vos hosts et votre infrastructure à base de conteneurs.
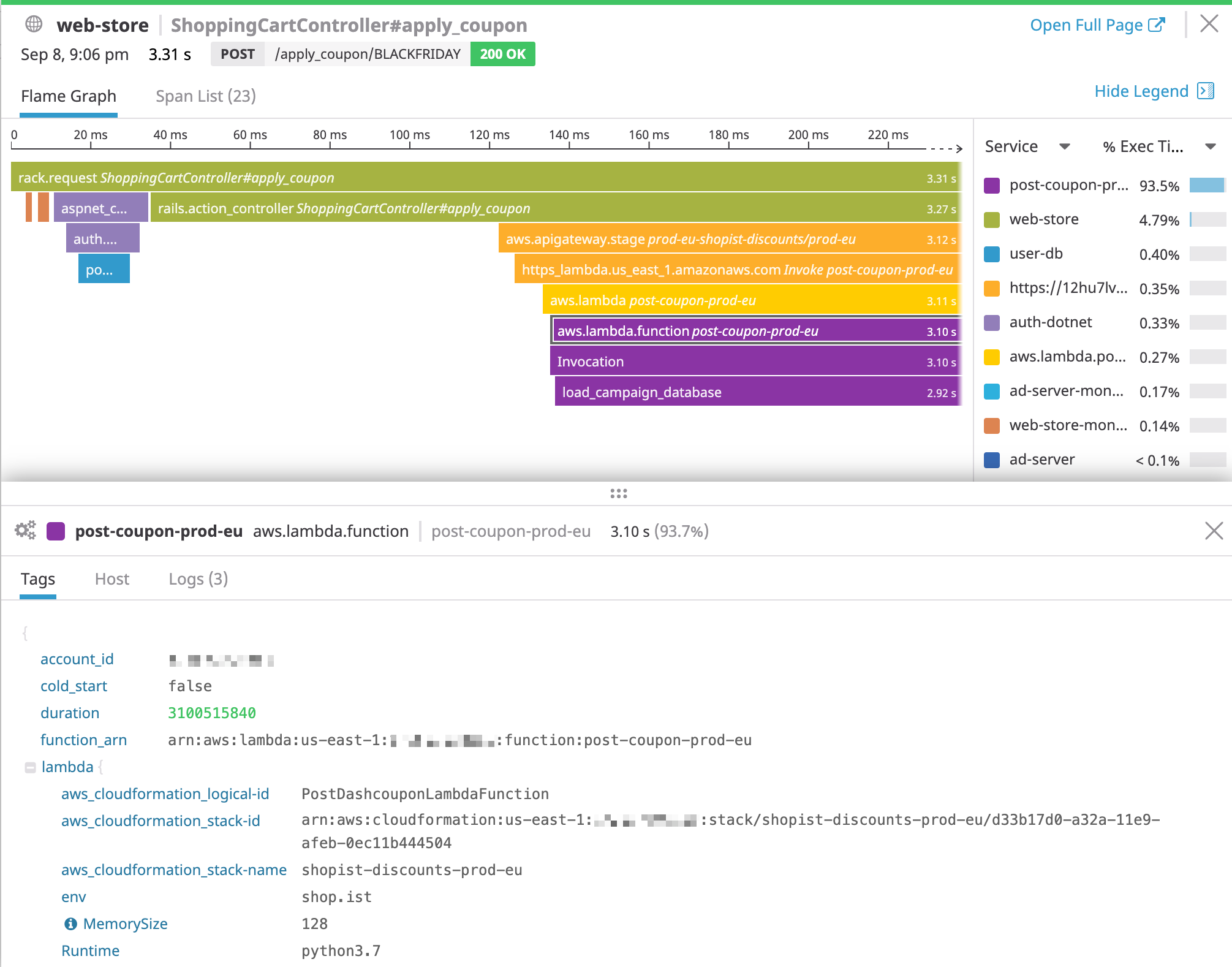
Pour que les traces d’AWS X-Ray et de l’APM Datadog s’affichent dans le même flamegraph, tous les services doivent avoir le même tag env.
Remarque : le tracing distribué est pris en charge pour tout runtime d’application basée sur des hosts ou des conteneurs. Vos hosts et vos fonctions Lambda n’ont pas besoin d’être dans le même runtime.
Propagation des traces
Configuration requise
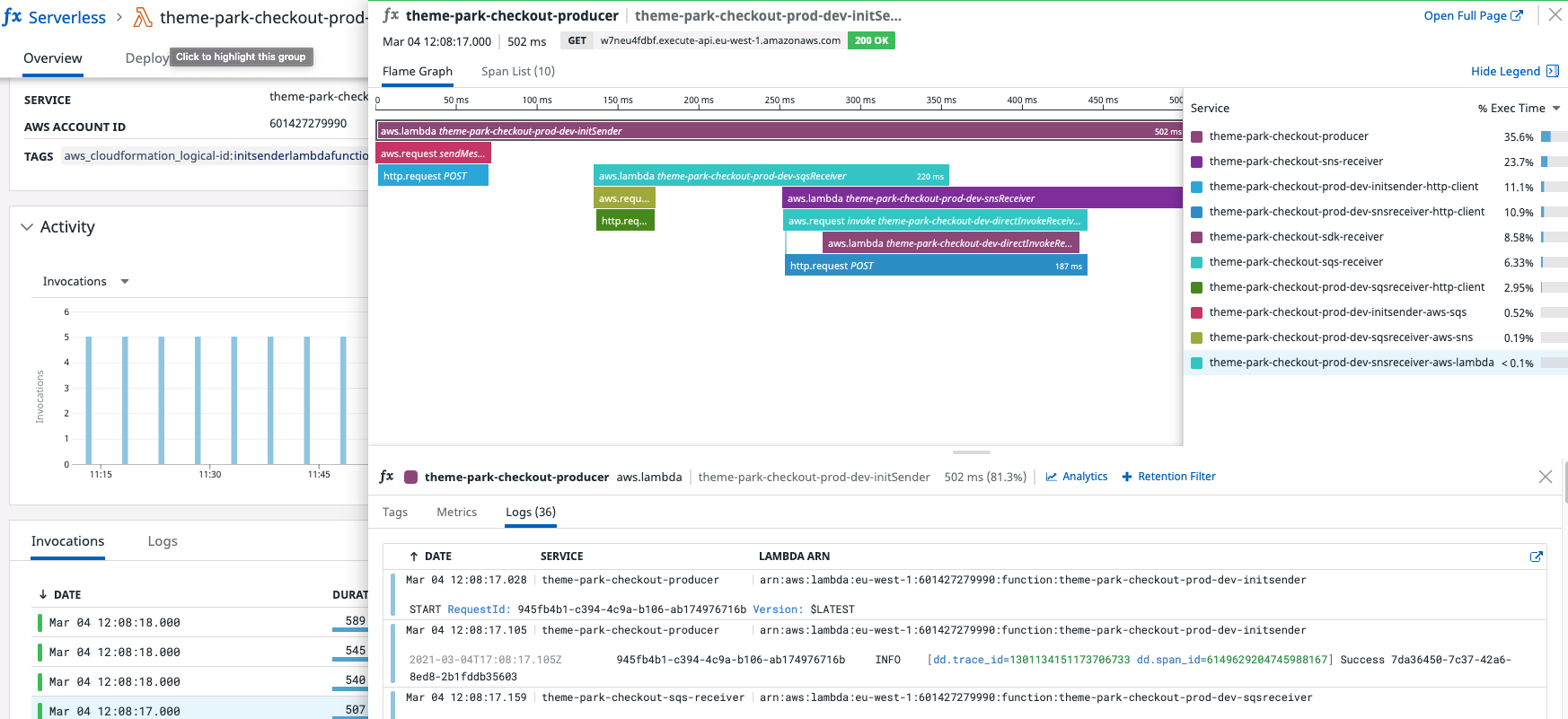
Une instrumentation supplémentaire est parfois nécessaire pour obtenir une trace unique et connectée dans les applications sans serveur Node et Python qui déclenchent des fonctions Lambda de manière asynchrone. Si vous commencez tout juste à surveiller des applications sans serveur dans Datadog, suivez les principales étapes d’installation et accédez à cette page pour choisir votre bibliothèque de tracing. Une fois que vous envoyez des traces depuis vos fonctions Lambda à Datadog à l’aide de la bibliothèque Lambda Datadog, vous pouvez choisir de suivre les étapes ci-dessous afin d’associer des traces entre deux fonctions Lambda pour l’un des scénarios suivants :
- Déclenchement de fonctions Lambda via Step Functions
- Invocation de fonctions Lambda via des protocoles non HTTP, comme MQTT
Le tracing d’un grand nombre de services AWS gérés (liste complète) est pris en charge par défaut. Il n’est pas nécessaire de suivre les étapes décrites sur cette page.
Pour associer le contexte des traces entre plusieurs ressources générant des traces, vous devez procéder comme suit :
- Incluez le contexte des traces Datadog dans les événements sortants. Ces événements peuvent provenir d’un host ou d’une fonction Lambda doté(e) de
dd-trace. - Extrayez le contexte des traces dans la fonction Lambda du consommateur.
Transmission du contexte des traces
Les extraits de code suivants permettent de transmettre le contexte des traces, par le biais des charges utiles sortantes, aux services qui ne prennent par en charge les en-têtes HTTP ou aux services gérés qui ne sont pas pris en charge de façon native par Datadog en Node et Python :
En Python, vous pouvez utiliser la fonction auxiliaire get_dd_trace_context pour transmettre le contexte des traces aux événements sortants dans une fonction Lambda :
import json
import boto3
import os
from datadog_lambda.tracing import get_dd_trace_context # Fonction auxiliaire de tracing Datadog
def handler(event, context):
my_custom_client.sendRequest(
{
'myCustom': 'data',
'_datadog': {
'DataType': 'String',
'StringValue': json.dumps(get_dd_trace_context()) # Inclure le contexte des traces dans les charges utiles sortantes
},
},
)
En Node, vous pouvez utiliser la fonction auxiliaire getTraceHeaders pour transmettre le contexte des traces aux événements sortants dans une fonction Lambda :
const { getTraceHeaders } = require("datadog-lambda-js"); // Fonction auxiliaire de tracing Datadog
module.exports.handler = async event => {
const _datadog = getTraceHeaders(); // Capture le contexte des traces Datadog actuel
var payload = JSON.stringify({ data: 'sns', _datadog });
await myCustomClient.sendRequest(payload)
À partir de hosts
Si vous ne transmettez pas le contexte des traces depuis vos fonctions Lambda, vous pouvez utiliser le modèle de code suivant à la place des fonctions auxiliaires getTraceHeaders et get_dd_trace_context pour obtenir le contexte de la span active. Consultez cette page pour obtenir les instructions permettant de récupérer ce contexte à chaque exécution.
const tracer = require("dd-trace");
exports.handler = async event => {
const span = tracer.scope().active();
const _datadog = {}
tracer.inject(span, 'text_map', _datadog)
// ...
Pour extraire le contexte des traces indiqué ci-dessus à partir de la fonction Lambda du consommateur, vous devez définir une fonction d’extraction qui capture le contexte avant l’exécution de votre gestionnaire de fonctions Lambda. Pour ce faire, pointez la variable d’environnement DD_TRACE_EXTRACTOR vers votre fonction d’extraction. Le format <NOM_FICHIER>.<NOM_FONCTION> doit être respecté. Par exemple, indiquez extractors.json si la fonction d’extraction json se trouve dans le fichier extractors.js. Datadog vous conseille de rassembler vos méthodes d’extraction au sein d’un unique fichier, afin de pouvoir les réutiliser pour plusieurs fonctions Lambda. Ces fonctions d’extraction peuvent être entièrement personnalisées selon vos besoins.
Remarques :
- Si vous utilisez TypeScript ou un bundler comme webpack, vous devez
import ou require votre module Node.js à l’emplacement où les fonctions d’extraction sont définies. Ainsi, le module est compilé et groupé au sein de votre package de déploiement Lambda. - Si vos fonctions Lambda Node.js s’exécutent sur
arm64, vous devez définir la fonction d’extraction dans le code de votre fonction au lieu d’utiliser la variable d’environnement DD_TRACE_EXTRACTOR.
Le code suivant comporte des extraits de fonction d’extraction que vous pouvez utiliser pour propager le contexte des traces à l’échelle d’un système tiers ou d’une API ne prenant pas en charge les en-têtes HTTP standard.
def extractor(payload):
trace_headers = json.loads(payload["_datadog"]);
trace_id = trace_headers["x-datadog-trace-id"];
parent_id = trace_headers["x-datadog-parent-id"];
sampling_priority = trace_headers["x-datadog-sampling-priority"];
return trace_id, parent_id, sampling_priority
exports.json = (payload) => {
const traceData = payload._datadog
const traceID = traceData["x-datadog-trace-id"];
const parentID = traceData["x-datadog-parent-id"];
const sampledHeader = traceData["x-datadog-sampling-priority"];
const sampleMode = parseInt(sampledHeader, 10);
return {
parentID,
sampleMode,
source: 'event',
traceID,
};
};
var exampleSQSExtractor = func(ctx context.Context, ev json.RawMessage) map[string]string {
eh := events.SQSEvent{}
headers := map[string]string{}
if err := json.Unmarshal(ev, &eh); err != nil {
return headers
}
// Puisque SQS est utilisé comme déclencheur avec batchSize=1, il est important d'effectuer cette vérification,
// car un seul message SQS initiera l'exécution du gestionnaire.
if len(eh.Records) != 1 {
return headers
}
record := eh.Records[0]
lowercaseHeaders := map[string]string{}
for k, v := range record.MessageAttributes {
if v.StringValue != nil {
lowercaseHeaders[strings.ToLower(k)] = *v.StringValue
}
}
return lowercaseHeaders
}
cfg := &ddlambda.Config{
TraceContextExtractor: exampleSQSExtractor,
}
ddlambda.WrapFunction(handler, cfg)
Envoyer des traces à Datadog avec l’intégration X-Ray
Si vous effectuez déjà le tracing de votre application sans serveur avec X-Ray, et que vous souhaitez continuer à utiliser ce service, vous pouvez installer l’intégration AWS X-Ray afin d’envoyer des traces depuis X-Ray vers Datadog.
Pour aller plus loin
Documentation, liens et articles supplémentaires utiles: