Monitor de check de processus
Présentation
Un monitor de check de processus surveille le statut généré par le check de l’Agent process.up. Au niveau de l’Agent, vous pouvez configurer les seuils de votre check en fonction du nombre processus correspondants.
Création d’un monitor
Pour créer un monitor de check de processus dans Datadog, utilisez la navigation principale : Monitors –> New Monitor –> Process Check.
Choisir un processus
Dans la liste déroulante, sélectionnez un processus à surveiller. Filtrez la liste en saisissant vos critères de recherche.
Choisir le contexte du monitor
Sélectionnez les hosts à surveiller en spécifiant les hostnames ou des tags, ou sélectionnez All Monitored Hosts. Seuls les hosts ou tags transmettant un statut pour le processus sélectionné s’affichent. Si vous souhaitez exclure certains hosts, spécifiez leurs noms ou des tags dans le second champ.
- Le champ Include utilise la logique
AND. Tous les hostnames et tags spécifiés doivent correspondre à un host pour que celui-ci soit inclus. - Le champ Exclude utilise la logique
OR. Tout host correspondant à l’un des hostnames ou tags est exclu.
Définir vos conditions d’alerte
Une alerte de check récupère les statuts consécutifs envoyés pour chaque groupe de checks et les compare à vos seuils. Pour les monitors de check de processus, les groupes sont statiques : host et process.
Paramètres d’une alerte de check :
Déclencher l’alerte après le nombre d’échecs consécutifs sélectionné : <NOMBRE>
Chaque exécution du check transmet un statut unique (OK, WARN ou CRITICAL). Choisissez le nombre de statuts WARN et CRITICAL consécutifs à partir duquel une notification doit être envoyée. Par exemple, il arrive que la connexion à un processus échoue pendant un bref instant seulement ; en définissant cette valeur sur > 1, les échecs ponctuels sont ignorés, tandis que les échecs prolongés déclenchent une notification.
Résoudre l’alerte après le nombre de réussites consécutives sélectionné : <NOMBRE>
Choisissez le nombre de statuts OK consécutifs à partir duquel l’alerte doit être résolue.
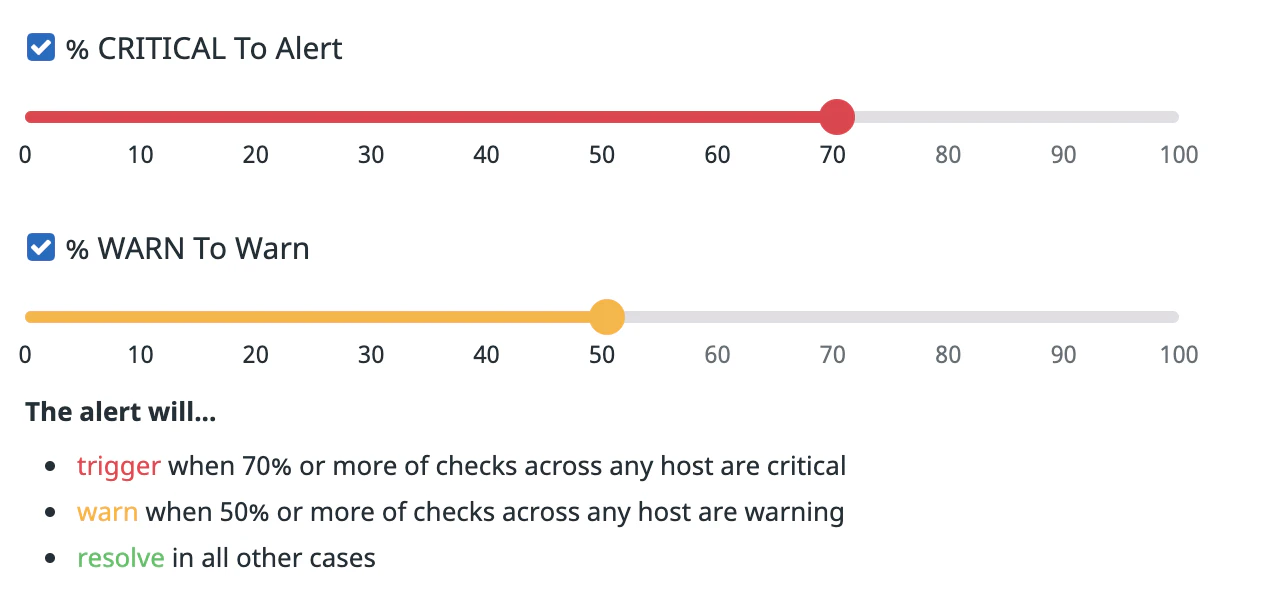
Une alerte de cluster calcule le pourcentage de checks de processus présentant un statut donné et le compare à vos seuils.
Paramètres d’une alerte de cluster :
Choisissez si vos checks de processus doivent être regroupés en fonction d’un tag ou non. Ungrouped calcule le pourcentage de statuts sur l’ensemble des sources. Grouped calcule le pourcentage de statuts pour chaque groupe.
Sélectionnez les seuils d’alerte et d’avertissement en pourcentage. Il est possible de ne définir qu’un seul de ces paramètres (alerte ou avertissement).
Chaque check possédant une combinaison spécifique de tags est considéré comme un check distinct dans le cluster. Seul le statut du dernier check de chaque combinaison de tags est pris en compte lors du calcul du pourcentage du cluster.
Par exemple, un monitor de check de cluster regroupé par environnement peut envoyer des alertes si plus de 70 % des checks d’un environnement renvoient le statut CRITICAL, et envoyer un avertissement si plus de 70 % des checks d’un environnement renvoient le statut WARN.
Conditions d’alerte avancées
Consultez la documentation relative à la configuration des monitors pour en savoir plus sur les notifications en absence de données (No data), la résolution automatique et le délai pour les nouveaux groupes.
Notifications
Pour obtenir des instructions détaillées sur l’utilisation des sections Say what’s happening et Notify your team, consultez la page Notifications.
Pour aller plus loin
Documentation, liens et articles supplémentaires utiles: