Comment surveiller des seuils non statiques
Présentation
Un monitor de métrique typique déclenche une alerte si une seule métrique dépasse un certain seuil. Par exemple, vous pouvez définir une alerte qui se déclenche si l’utilisation de votre disque dépasse 80 %. Cette approche est efficace pour de nombreux cas d’utilisation, mais que se passe-t-il lorsque le seuil est une variable plutôt qu’un nombre absolu ?
Les monitors alimentés par Watchdog (à savoir anomaly et outlier) sont particulièrement utiles lorsqu’il n’existe pas de définition expliquant le fait que votre métrique n’est pas juste. Cependant, dans la mesure du possible, vous devriez utiliser des moniteurs classiques avec des conditions d’alerte adaptées pour maximiser la précision et minimiser le délai d’alerte pour votre cas d’utilisation spécifique.
Ce guide couvre les cas d’utilisation courants dʼalertes sur les seuils non statiques :
Seuil saisonnier
Contexte
Vous êtes le chef d’équipe en charge d’un site de commerce électronique. Vous souhaitez :
- recevoir des alertes en cas de baisse inattendue du trafic sur votre page d’accueil
- capturer les incidents plus localisés, comme ceux qui affectent les fournisseurs d’accès à Internet publics
- couvrir des scénarios dʼéchecs inconnus
Le trafic de votre site web varie d’une nuit à l’autre et d’un jour de semaine à l’autre. Il n’existe pas de chiffre absolu permettant de quantifier ce que signifie une baisse inattendue. Toutefois, le trafic suit un schéma prévisible qui vous permet de considérer une différence de 10 % comme pouvant indiquer un problème de façon fiable, comme pour un incident localisé affectant les fournisseurs d’accès à Internet publics.
Monitor
Votre équipe mesure le nombre de connexions sur votre serveur web NGINX à l’aide de la métrique nginx.requests.total_count.
La requête se compose de 3 parties :
- Une requête pour obtenir le nombre actuel de demandes.
- Une requête pour obtenir le nombre de demandes à la même heure une semaine auparavant.
- les requêtes en formule, qui calculent le rapport entre les deux premières requêtes.
Décidez ensuite de l’agrégation temporelle :
- Vous choisissez l’intervalle. Plus la période est longue, plus le système évalue de données pour détecter une anomalie. Les périodes plus longues peuvent également donner lieu à des alertes plus nombreuses du monitor. Commencez donc par une heure, puis adaptez votre choix à vos besoins.
- Vous choisissez l’agrégation. Puisqu’il s’agit d’une métrique count effectuant un ratio,
average (ou sum) est un bon choix.
Le seuil affiché dans la capture d’écran ci-dessous a été configuré sur 0,9 pour tenir compte d’une différence de 10 % entre la valeur de la première requête (actuelle) et celle de la deuxième requête (semaine précédente).
{
"name": "[Seasonal threshold] Amount of connection",
"type": "query alert",
"query": "sum(last_10m):sum:nginx.requests.total_count{env:prod} by {datacenter} / week_before(sum:nginx.requests.total_count{env:prod} by {datacenter}) <= 0.9",
"message": "Le nombre de connexions est inférieur à celui dʼhier de {{value}} !",
"tags": [],
"options": {
"thresholds": {
"critical": 0.9
},
"notify_audit": false,
"require_full_window": false,
"notify_no_data": false,
"renotify_interval": 0,
"include_tags": true,
"new_group_delay": 60,
"silenced": {}
},
"priority": null,
"restricted_roles": null
}
Seuil de référence
Contexte
Vous êtes le chef de l’équipe d’assurance qualité, responsable du processus de paiement de votre site de commerce électronique. Vous voulez vous assurer que vos clients ont une bonne expérience et qu’ils peuvent acheter vos produits sans problème. Le taux d’erreur en est un indicateur.
Le trafic n’est pas le même tout au long de la journée, de sorte que 50 erreurs/minute le vendredi soir sont moins inquiétantes que 50 erreurs/minute le dimanche matin. La surveillance d’un taux d’erreur plutôt que des erreurs elles-mêmes vous donne un aperçu fiable de ce que sont des métriques saines et malsaines.
Vous êtes alerté lorsque le taux d’erreur est élevé, mais aussi lorsque le volume des occurrences est suffisamment important.
Monitor
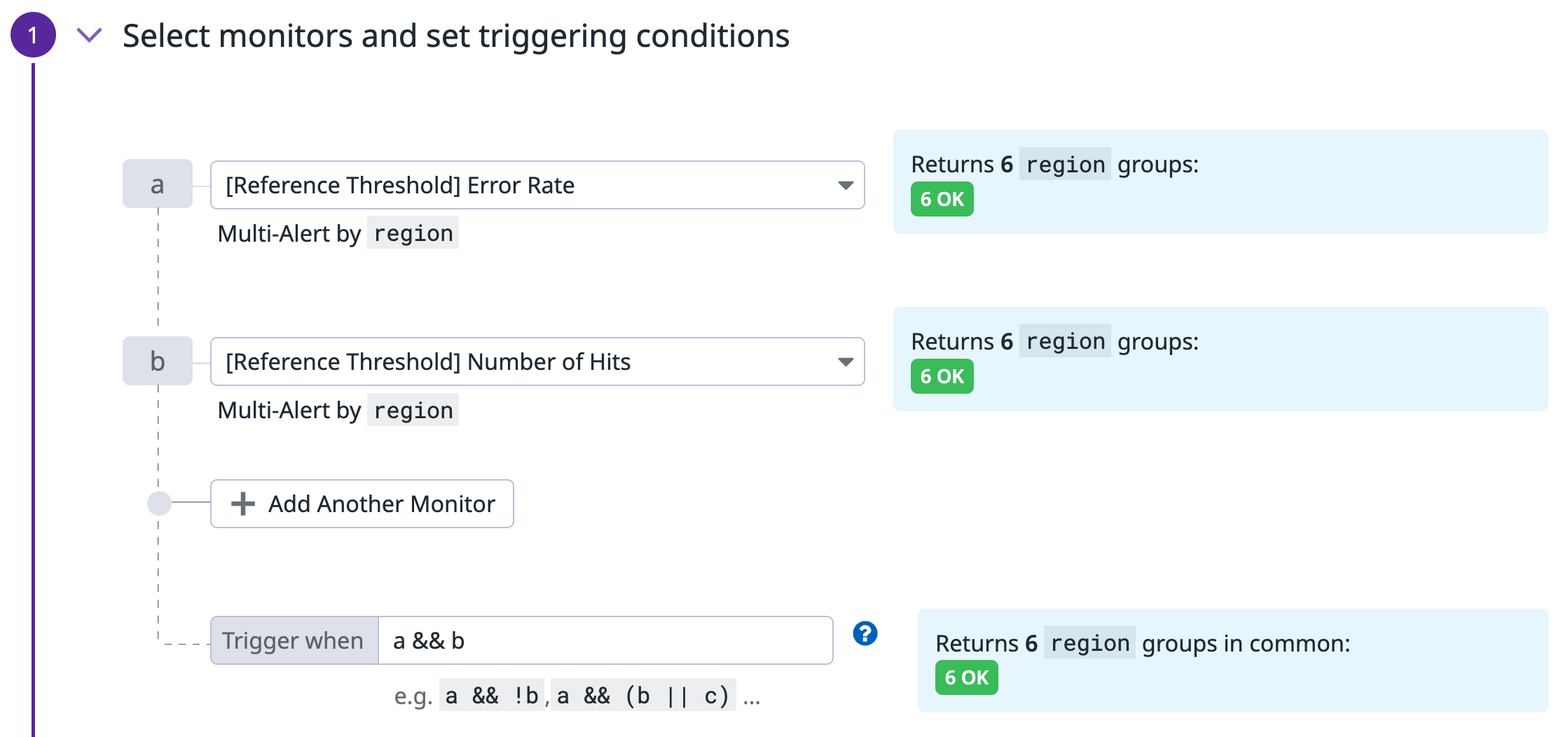
Créer 3 monitors au total :
- Monitor de métrique pour alerter sur le nombre total dʼoccurrences
- [Monitor de métrique pour calculer le taux d’erreur] (#monitor-de-metrique-pour-calculer-le-taux-d-erreur)
- [Monitor composite qui déclenche une alerte si les deux premiers monitors sont en état ALERTE] (#monitor-composite)
Monitor de métrique pour recevoir une alerte sur le nombre total dʼoccurrences
Le premier monitor suit le nombre total dʼoccurrences, qu’il s’agisse de succès ou d’échecs. Ce monitor détermine si le taux d’erreur doit déclencher une alerte.
<div class="shortcode-wrapper shortcode-img expand"><figure class="text-center"><a href="https://datadog-docs.imgix.net/images/monitors/guide/non_static_thresholds/reference_total_hits.55947f19b807662039b288eb84aee014.png?fit=max&auto=format" class="pop" data-bs-toggle="modal" data-bs-target="#popupImageModal"><picture class="" style="width:100%;" >
<img
class="img-fluid"
srcset="https://datadog-docs.imgix.net/images/monitors/guide/non_static_thresholds/reference_total_hits.55947f19b807662039b288eb84aee014.png?auto=format"
style="width:100%;" alt="Configuration de monitor de métrique avec une formule pour calculer le nombre total dʼoccurrences" />
</picture></a></figure>
</div>
{
"name": "Nombre dʼoccurrences",
"type": "query alert",
"query": "sum(last_5m):sum:shopist.checkouts.failed{env:prod} by {region}.as_count() + sum:shopist.checkouts.success{env:prod} by {region}.as_count() > 4000",
"message": "Il y a eu plus de 4 000 occurrences pour cette région !",
"tags": [],
"options": {
"thresholds": {
"critical": 1000
},
"notify_audit": false,
"require_full_window": false,
"notify_no_data": false,
"renotify_interval": 0,
"include_tags": true,
"new_group_delay": 60
}
}
Monitor de métrique pour calculer le taux d’erreur
Le deuxième monitor calcule le taux d’erreur. Créez une requête sur le nombre d’erreurs divisé par le nombre total d’occurrences pour obtenir le taux d’erreur a / a+b :
<div class="shortcode-wrapper shortcode-img expand"><figure class="text-center"><a href="https://datadog-docs.imgix.net/images/monitors/guide/non_static_thresholds/reference_error_rate.5c0f5ca88cbc364b6446841751c99a58.png?fit=max&auto=format" class="pop" data-bs-toggle="modal" data-bs-target="#popupImageModal"><picture class="" style="width:100%;" >
<img
class="img-fluid"
srcset="https://datadog-docs.imgix.net/images/monitors/guide/non_static_thresholds/reference_error_rate.5c0f5ca88cbc364b6446841751c99a58.png?auto=format"
style="width:100%;" alt="Configuration de monitor de métrique avec une formule pour calculer le taux dʼerreur" />
</picture></a></figure>
</div>
{
"name": "Taux dʼerreur",
"type": "query alert",
"query": "sum(last_5m):sum:shopist.checkouts.failed{env:prod} by {region}.as_count() / (sum:shopist.checkouts.failed{env:prod} by {region}.as_count() + sum:shopist.checkouts.success{env:prod} by {region}.as_count()) > 0.5",
"message": "Le taux dʼerreur est actuellement de {{value}} ! Faites attention !",
"tags": [],
"options": {
"thresholds": {
"critical": 0.5
},
"notify_audit": false,
"require_full_window": false,
"notify_no_data": false,
"renotify_interval": 0,
"include_tags": true,
"new_group_delay": 60
}
}
Monitor composite
Le dernier monitor est un monitor composite, qui n’envoie une alerte que si les deux monitors précédents sont également tous deux dans un état ALERT.
Pour aller plus loin
Documentation, liens et articles supplémentaires utiles: