Section Overview
Pour commencer à configurer le monitor, complétez les sections suivantes :
- Define the search query : créez une requête afin de compter le nombre d’événements, de mesurer des métriques, de regrouper une ou plusieurs dimensions, etc.
- Set alert conditions : configurez des seuils d’alerte et d’avertissement, des intervalles d’évaluation et des options d’alerte avancées.
- Configure notifications and automations : Rédigez un titre et un message personnalisés avec des variables. Choisissez comment les notifications sont envoyées à vos équipes (email, Slack ou PagerDuty). Incluez des automatisations de workflow ou des cas dans la notification d’alerte.
- Define permissions and audit notifications : Configurez des contrôles d’accès granulaires et désignez les rôles et utilisateurs autorisés à modifier un monitor. Activez les notifications d’audit pour être alerté en cas de modification d’un monitor.
Définir la requête de recherche
Pour découvrir comment créer la requête de syntaxe, consultez les pages de documentation de chaque type de monitor. Le graphique d’aperçu situé au-dessus des champs de recherche s’actualise au fur et à mesure que vous modifiez la requête de recherche.
Définir vos conditions d’alerte
Les conditions d’alerte varient en fonction du type de monitor. Vous pouvez configurer vos monitors de façon à ce qu’ils se déclenchent lorsque la valeur de la requête dépasse un certain seuil, ou si un certain nombre de checks consécutifs ont échoué.
- Envoyer une alerte lorsque la valeur
average, max, min ou sum de la métrique est above, above or equal to, below ou below or equal to (supérieure, supérieure ou égale, inférieure ou inférieure ou égale) au seuil- sur un intervalle de
5 minutes, 15 minutes ou 1 hour ou encore lors d’une période custom comprise entre 1 minute et 48 heures (jusqu’à 1 mois pour les monitors de métrique).
Méthode d’agrégation
La requête renvoie une série de points. Toutefois, le monitor ne doit comparer qu’une seule valeur au seuil. Les données transmises lors de la période d’évaluation doivent donc être converties en une valeur unique.
| Option | Rôle |
|---|
| average | La moyenne de la série est calculée afin de générer une valeur unique, qui est ensuite comparée au seuil. Cette option ajoute la fonction avg() à la requête de votre monitor. |
| max | Si une valeur dans la série générée dépasse le seuil, une alerte se déclenche alors. Cette option ajoute la fonction max() à la requête de votre monitor.* |
| min | Si chaque point compris dans l’intervalle d’évaluation de votre requête dépasse le seuil, une alerte se déclenche alors. Cette option ajoute la fonction min() à la requête de votre monitor.* |
| sum | Si la somme de tous les points de la série dépasse le seuil, une alerte se déclenche alors. Cette option ajoute la fonction sum() à la requête de votre monitor. |
* Ces descriptions de max et min supposent que le monitor alerte lorsque la métrique dépasse le seuil. Pour les monitors qui alertent lorsque la métrique est inférieure au seuil, le comportement de max et min est inversé. Pour plus d’exemples, consultez le guide Agrégateurs de monitor.
Remarque : trois comportements différents peuvent être appliqués lorsque vous utilisez as_count(). Consultez as_count() dans les évaluations de monitors pour en savoir plus.
Fenêtre d’évaluation
Un monitor peut être évalué en fonction d’une période cumulée ou d’une période glissante. Les périodes cumulées sont idéales pour les questions qui nécessitent d’examiner des données historiques, telles que « Quelle est la somme de l’ensemble des données disponibles jusqu’à maintenant ? » Les périodes mobiles sont adaptées aux questions qui ne nécessitent pas de contexte, telles que « Quelle est la moyenne des N derniers points de données ? »
Le schéma ci-dessous illustre la différence entre les périodes cumulées et les périodes mobiles.
Périodes mobiles
Les périodes mobiles ont une durée fixe, mais leur point de départ se décale au fil du temps. Les monitors peuvent analyser les dernières 5 minutes, 15 minutes, 1 hour ou un intervalle personnalisé allant jusqu’à 1 mois.
Remarque : les monitors de logs ont une période mobile maximale de 2 days.
Périodes cumulées
Les périodes cumulées ont un point de départ fixe et s’étendent au fil du temps. Les monitors prennent en charge trois périodes cumulées différentes :
Current hour : une période d’une heure maximum qui commence à la minute choisie. Par exemple, vous pouvez surveiller le nombre d’appels reçus par un endpoint HTTP sur une heure à partir de la minute 0.
Current day : une période de 24 heures maximum qui commence à l’heure et la minute choisies. Par exemple, vous pouvez surveiller un quota journalier d’indexation de logs en utilisant l’intervalle current day et en le faisant commencer à 14 h UTC.
Current month : analyse le mois en cours à partir d’un jour, d’une heure et d’une minute configurables. Cette option représente une fenêtre temporelle du mois en cours (month-to-date) et est uniquement disponible pour les monitors de métriques.
Les fenêtres cumulées sont réinitialisées dès que l’intervalle maximum est atteint. Par exemple, si une période cumulée est définie sur current month (mois actuel), celle-ci se réinitialise automatiquement le premier de chaque mois à minuit UTC. De la même façon, une période cumulée définie sur current hour avec un point de départ à la minute 30 se réinitialise toutes les heures : à 6 h 30, à 7 h 30, à 8 h 30.
Fréquence d’évaluation
La fréquence d’évaluation correspond à la fréquence à laquelle Datadog exécute la requête de monitor. Elle est généralement de 1 minute, ce qui signifie que chaque minute, le monitor évalue les données sélectionnées sur la fenêtre d’évaluation sélectionnée et compare la valeur agrégée aux seuils définis.
Par défaut, la fréquence d’évaluation dépend de la fenêtre d’évaluation utilisée. Une fenêtre plus longue entraîne une fréquence d’évaluation plus faible. Le tableau suivant illustre comment la fréquence d’évaluation est influencée par des périodes plus longues :
| Plages de fenêtres d’évaluation | Fréquence d’évaluation |
|---|
| fenêtre < 24 heures | 1 minute |
| 24 heures <= fenêtre < 48 heures | 10 minutes |
| fenêtre >= 48 heures | 30 minutes |
La fréquence d’évaluation peut également être configurée pour que la condition d’alerte du monitor soit vérifiée quotidiennement, chaque semaine ou chaque mois. Dans cette configuration, la fréquence d’évaluation ne dépend plus de la fenêtre d’évaluation, mais du planning configuré.
Pour plus d’informations, consultez le guide sur la manière de personnaliser la fréquence d’évaluation des monitors.
Seuils
Utilisez les seuils pour définir la valeur numérique à partir de laquelle une alerte doit se déclencher. En fonction de la métrique choisie, l’éditeur affiche l’unité utilisée (byte, kibibyte, gibibyte, etc).
Datadog peut envoyer des notifications d’alerte et des notifications d’avertissement. Les monitors sont rétablis automatiquement en fonction du seuil d’alerte ou d’avertissement, mais des conditions supplémentaires peuvent être spécifiées. Pour en savoir plus sur les seuils de rétablissement, consultez la section Qu’est-ce qu’un seuil de rétablissement ? Par exemple, si un monitor envoie une alerte lorsqu’une métrique dépasse la valeur 3 et qu’aucun seuil de rétablissement n’est défini, le monitor se rétablit lorsque la valeur de la métrique redescend sous 3.
| Option | Rôle |
|---|
| Seuil d’alerte (obligatoire) | La valeur utilisée pour déclencher une notification d’alerte. |
| Seuil d’avertissement | La valeur utilisée pour déclencher une notification d’avertissement. |
| Seuil de rétablissement de l’alerte | Un seuil facultatif pour indiquer une condition supplémentaire de rétablissement d’alerte. |
| Seuil de rétablissement de l’avertissement | Un seuil facultatif pour indiquer une condition supplémentaire de rétablissement d’avertissement. |
Lorsque vous modifiez un seuil, l’aperçu du graphique dans l’éditeur affiche un indicateur symbolisant la limite.
Remarque : lorsque vous saisissez des valeurs décimales pour des seuils, si votre valeur est <1, ajoutez un 0 au début du nombre. Par exemple, utilisez 0.5 et non ,5.
Une alerte de check récupère les statuts consécutifs envoyés pour chaque groupe de checks et les compare à vos seuils. Configurez une alerte de check pour :
Déclencher l’alerte après le nombre d’échecs consécutifs sélectionné : <NOMBRE>
Chaque exécution du check transmet un statut unique (OK, WARN ou CRITICAL). Choisissez le nombre de statuts WARN et CRITICAL consécutifs à partir duquel une notification doit être envoyée. Par exemple, il arrive que la connexion à un processus échoue pendant un bref instant seulement ; en définissant cette valeur sur > 1, les échecs ponctuels sont ignorés, tandis que les échecs prolongés déclenchent une notification.
Résoudre l’alerte après le nombre de réussites consécutives sélectionné : <NOMBRE>
Choisissez le nombre de statuts OK consécutifs à partir duquel l’alerte doit être résolue.
Consultez la documentation sur les monitors de check de processus, check d’intégration et check custom pour en savoir plus sur la configuration des alertes des checks.
Conditions d’alerte avancées
No data
Les notifications d’absence de données sont particulièrement utiles si une métrique est supposée envoyer des données en permanence. Par exemple, si un host sur lequel l’Agent est installé doit être disponible en continu, la métrique system.cpu.idle doit toujours envoyer des données.
Dans ce cas, nous vous conseillons d’activer ces notifications. Les sections ci-dessous expliquent comment procéder pour chaque option.
Remarque : le monitor doit pouvoir évaluer les données avant d’envoyer une alerte d’absence de données. Par exemple, si vous créez un monitor pour service:abc et que service n’a jamais transmis de données, le monitor n’envoie aucune alerte.
En cas d’absence de données pendant N minutes, sélectionnez une option dans le menu déroulant :
Evaluate as zero / Show last known statusShow NO DATAShow NO DATA and notifyShow OK.
Le comportement sélectionné est appliqué lorsque la requête d’un monitor ne renvoie aucune donnée. Contrairement à l’option Do not notify, la fenêtre d’absence de données n’est pas configurable.
| Option | Statut du monitor et notification |
|---|
Evaluate as zero | Les résultats vides sont remplacés par zéro et comparés aux seuils d’alerte/d’avertissement. Par exemple, si le seuil d’alerte est défini sur > 10, un zéro ne déclenchera pas cette condition et le statut du monitor sera défini sur OK. |
Show last known status | Le dernier statut connu du groupe ou monitor est défini. |
Show NO DATA | Le statut du monitor est défini sur NO DATA. |
Show NO DATA and notify | Le statut du monitor est défini sur NO DATA et une notification est envoyée. |
Show OK | Le monitor est résolu et le statut est défini sur OK. |
Les options Evaluate as zero et Show last known status s’affichent en fonction du type de requête :
- Evaluate as zero : cette option est disponible pour les monitors basés sur une requête
Count, sans la fonction default_zero(). - Show last known status : cette option est disponible pour les monitors basés sur un type de requête autre que
Count, par exemple Gauge, Rate et Distribution, ainsi que pour les requêtes Count avec default_zero().
Rétablissement automatique
Utilisez les options [Never], After 1 hour, After 2 hours, etc. pour choisir si et au bout de combien de temps un monitor doit être automatiquement rétabli après s’être déclenché.
Le rétablissement automatique s’applique lorsqu’aucune nouvelle donnée n’est transmise. Il n’est pas utilisé pour rétablir les monitors qui passent d’un statut ALERT à un statut WARN alors que des données continuent à être transmises. Si des données sont toujours envoyées, vous pouvez informer votre équipe que le problème n’est pas résolu grâce à la fonctionnalité de renvoi de notifications.
Lorsqu’une métrique n’envoie des données qu’à certains moments, il est logique de résoudre automatiquement une alerte après un certain temps. Par exemple, si un counter envoie uniquement des informations lorsqu’une erreur est détectée, l’alerte n’est jamais résolue car la métrique ne renvoie jamais un nombre d’erreurs égal à 0. Dans ce cas, il est préférable de résoudre l’alerte lorsque la métrique est inactive depuis un certain temps. Remarque : si un monitor est automatiquement rétabli et que la valeur de la requête ne satisfait pas le seuil de rétablissement lors de l’évaluation suivante, le monitor déclenche une nouvelle alerte.
Ce paramètre n’est pas utile dans la plupart des cas : il est préférable de résoudre une alerte uniquement lorsqu’elle a été traitée. Il convient donc généralement de le laisser sur [Never]. Les alertes sont alors uniquement résolues lorsque la métrique est supérieure ou inférieure au seuil défini.
Durée de rétention du groupe
Vous pouvez retirer le groupe du statut du monitor après N heures sans données. La durée peut être de minimum 1 heure et de maximum 72 heures. Pour les monitors multi alertes, sélectionnez Remove the non-reporting group after N (length of time).
Tout comme l’option de rétablissement automatique, la durée de rétention du groupe s’applique lorsque la requête ne renvoie plus de données. Cette option détermine la durée pendant laquelle le groupe conserve le statut du monitor à partir du moment où les données cessent d’être transmises. Par défaut, les groupes conservent le statut pendant 24 heures avant d’être exclus. Le délai de rétention du groupe et le délai de rétablissement automatique commencent au même moment, dès que la requête du monitor ne renvoie plus de données.
Les durées de rétention peuvent par exemple s’avérer utiles dans les cas suivants :
- Lorsque vous souhaitez exclure le groupe dès que la requête ne renvoie plus de données, ou peu de temps après
- Lorsque vous souhaitez que le groupe conserve le statut du monitor pendant toute la durée du dépannage
Remarque : pour configurer la durée de rétention, vous devez utiliser un monitor à alertes multiples qui prend en charge l’option On missing data. Cela englobe les monitors d’analyse de traces APM, de logs d’audit, de pipelines CI, de suivi des erreurs, d’événements, de logs et RUM.
Délai pour les nouveaux groupes
Retardez de N secondes le début de l’évaluation des nouveaux groupes.
Ce délai correspond à la durée, en secondes, après laquelle les alertes commencent à être envoyées. Il permet aux nouveaux groupes de se lancer et aux applications de terminer leur démarrage. Sa valeur doit être définie sur un nombre entier positif.
Par exemple, si votre architecture est conteneurisée, le délai pour les nouveaux groupes vous permet d’éviter de déclencher les groupes de monitors filtrés sur des conteneurs en cas d’utilisation élevée des ressources ou de latence importante au moment de la création d’un conteneur. Le délai est appliqué à tous les nouveaux groupes (qui n’ont pas été détectés lors des dernières 24 heures). Sa valeur est définie par défaut sur 60 secondes.
Cette option est disponible pour les monitors à alertes multiples.
Délai avant évaluation
Datadog recommande un délai de 15 minutes pour les métriques cloud, qui sont rétropolées par les fournisseurs de services. De plus, lorsque vous utilisez une formule de division, un délai de 60 secondes permet de s'assurer que le monitor s'évalue sur des valeurs complètes. Consultez la page
Délai de réception des métriques cloud pour connaître les délais estimés.
Choisissez de retarder l’évaluation de N secondes.
La durée (en secondes) correspondant au délai avant l’évaluation. La valeur doit être un nombre entier non négatif. Par exemple, si le délai est défini sur 900 secondes (15 min), que l’intervalle est défini sur les dernières 5 minutes et qu’il est 7 h, le monitor évalue les données mesurées entre 6 h 40 et 6 h 45. Le délai avant évaluation maximum est de 86400 secondes (24 heures).
Configurez vos messages de notification de façon à inclure les informations qui vous intéressent le plus. Indiquez les équipes auxquelles ces alertes doivent être envoyées, ainsi que les attributs pour lesquels les alertes doivent se déclencher.
Message
Utilisez cette section pour configurer les notifications envoyées à votre équipe et la façon dont elles sont envoyées :
Pour en savoir plus sur les options de configuration du message de notification, consultez la section Notifications d’alerte.
Ajouter des métadonnées
- Utilisez le menu déroulant Tags pour associer des tags à votre monitor.
- Utilisez le menu déroulant Teams pour associer des équipes à votre monitor.
- Utilisez le champ Priority pour choisir une priorité.
Définir l’agrégation des alertes
Les alertes sont regroupées automatiquement en fonction de l’agrégation choisie pour votre requête (par exemple, avg by service). Si la requête ne contient aucun regroupement, le type d’alerte par défaut est Simple Alert. Si la requête est groupée selon une ou plusieurs dimensions, le type passe à Multi Alert.
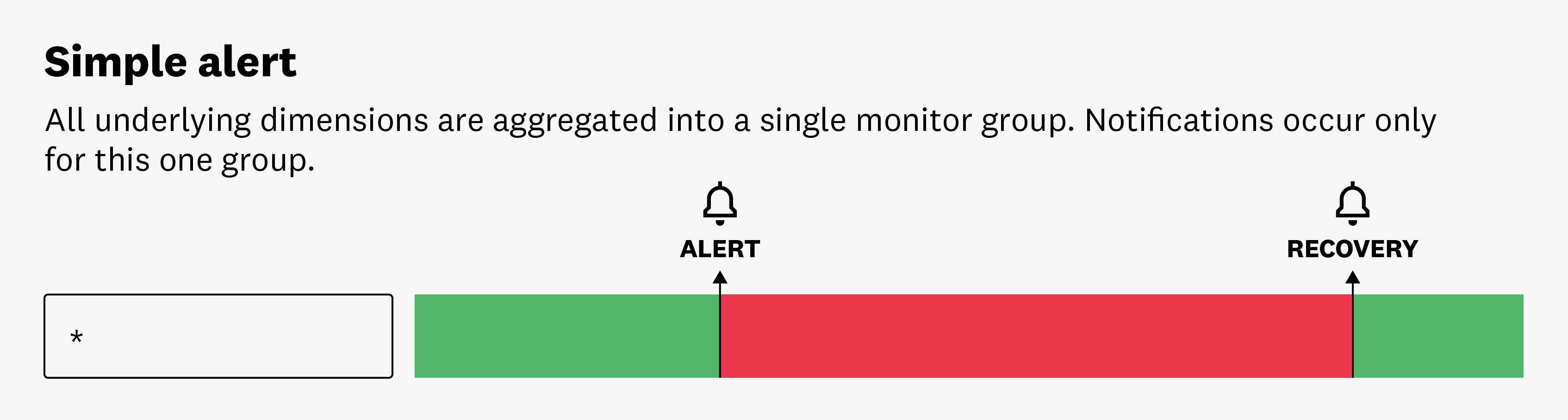
Alerte simple
Le mode Simple Alert déclenche une notification en agrégeant toutes les sources qui envoient des données. Vous recevez une seule alerte lorsque la valeur agrégée atteint les conditions définies. Par exemple, vous pouvez configurer un monitor pour vous alerter si la consommation moyenne de CPU de l’ensemble des serveurs dépasse un certain seuil. Si ce seuil est atteint, vous recevrez une seule notification, quel que soit le nombre de serveurs individuels ayant dépassé le seuil. Cela peut être utile pour surveiller des tendances ou des comportements globaux du système.
Alerte multiple
Un monitor Multi Alert déclenche des notifications individuelles pour chaque entité du monitor qui atteint le seuil d’alerte.
Par exemple, si vous configurez un monitor pour vous alerter lorsque la latence P99, agrégée par service, dépasse un certain seuil, vous recevrez une alerte distincte pour chaque service dont la latence P99 dépasse ce seuil. Cela peut être utile pour identifier et résoudre des problèmes spécifiques liés au système ou à une application. Ce mode permet de suivre les incidents à un niveau plus granulaire.
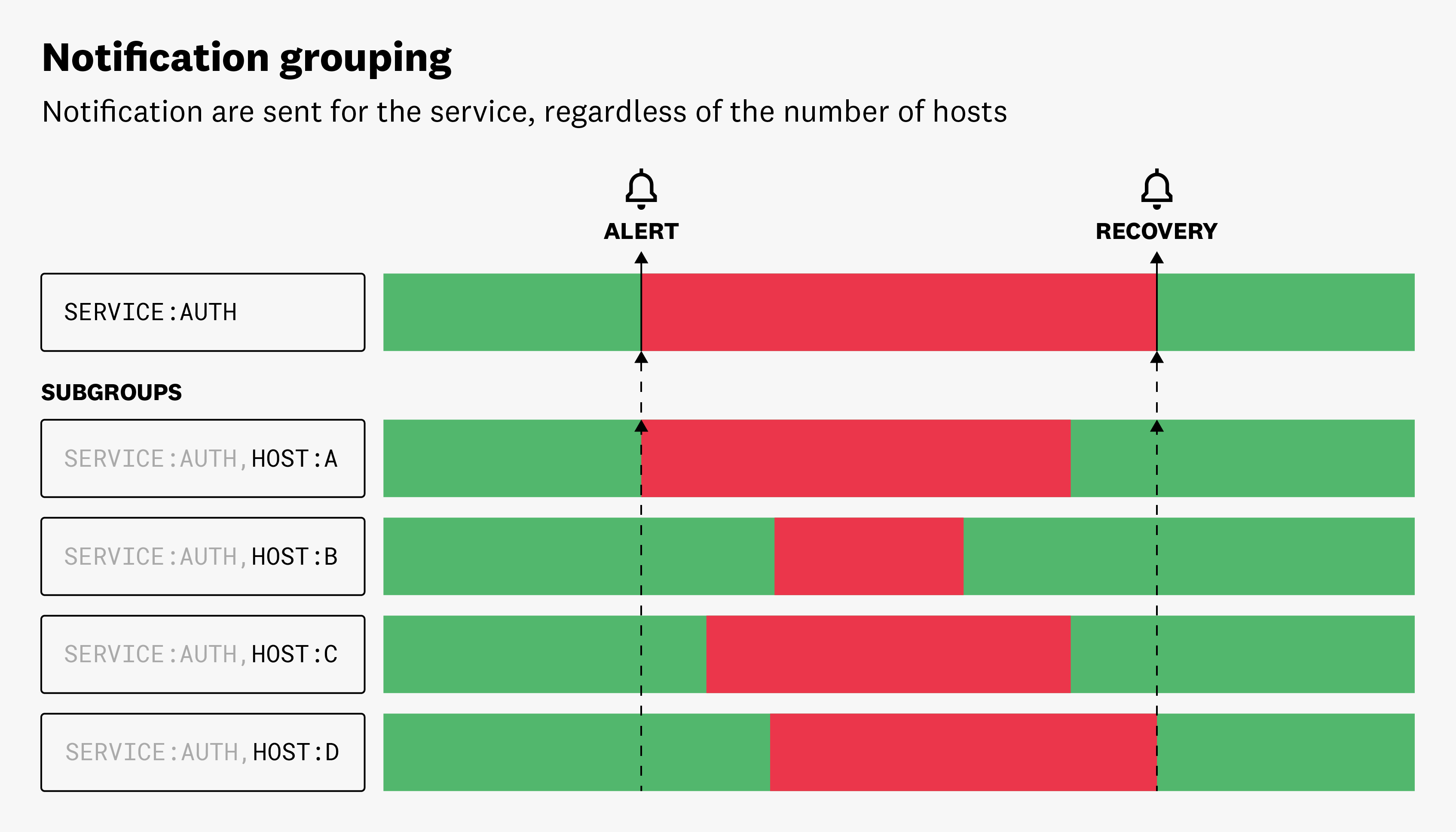
Regroupement des notifications
Lorsque vous surveillez un grand groupe d’entités, les multi alerts peuvent générer un trop grand nombre de notifications. Pour atténuer cela, personnalisez les dimensions qui déclenchent les alertes. Cela permet de réduire le bruit et de vous concentrer sur les alertes les plus importantes.
Par exemple, vous surveillez la consommation moyenne de CPU de tous vos hosts. Si vous regroupez votre requête par service et host mais souhaitez recevoir une alerte uniquement pour chaque attribut service dépassant le seuil, retirez l’attribut host des options de multi alert afin de réduire le nombre de notifications envoyées.
Lorsque vous agrégerez les notifications en mode Multi Alert, les dimensions non utilisées pour l’agrégation deviennent des Sub Groups dans l’interface.
Remarque : si votre métrique dispose uniquement du tag host sans tag service, elle ne sera pas détectée par le monitor. Les métriques qui disposent à la fois des tags host et service seront détectées par le monitor.
Si vous avez configuré des tags ou des dimensions dans votre requête, ces valeurs sont disponibles pour chaque groupe évalué dans l’alerte multiple afin d’ajouter des informations de contexte dynamiques dans les notifications. Consultez la section Variables d’attribut et de tag pour découvrir comment utiliser les valeurs de tag dans le message de notification.
| Regrouper en fonction de | Alertes simples | Alertes multiples |
|---|
| (tous les éléments) | Un seul groupe déclenchant une notification | S. O. |
| Une ou plusieurs dimensions | Envoi d’une notification si un ou plusieurs groupes répondent aux conditions de l’alerte | Envoi d’une notification par groupe respectant les conditions d’alerte |
Autorisations
Tous les utilisateurs peuvent consulter tous les monitors, quel que soit le rôle ou l’équipe auxquels ils sont associés. Par défaut, seuls les utilisateurs rattachés à des rôles disposant de la permission Monitors Write peuvent modifier des monitors. Les rôles Datadog Admin Role et Datadog Standard Role disposent de cette permission par défaut. Si votre organisation utilise des rôles personnalisés, ces derniers peuvent également inclure la permission Monitors Write. Pour en savoir plus sur la configuration du contrôle d’accès RBAC pour les monitors et sur la migration des monitors à partir du paramètre verrouillé vers l’utilisation de restrictions basées sur les rôles, consultez le guide Configuration du RBAC pour les monitors.
Vous pouvez restreindre davantage l’accès à votre monitor en spécifiant une liste d’équipes, de rôles ou d’utilisateurs autorisés à le modifier. Le créateur du monitor dispose des droits de modification par défaut. La modification inclut toute mise à jour de la configuration du monitor, sa suppression ou sa mise en sourdine pour une durée quelconque.
Remarque : les limites s’appliquent à la fois à l’IU et à l’API.
Contrôles d’accès granulaires
Utilisez les contrôles d’accès granulaires pour limiter les équipes, rôles ou utilisateurs autorisés à modifier un monitor :
- Lors de la modification ou de la configuration d’un monitor, accédez à la section Define permissions and audit notifications.
- Cliquez sur Edit Access.
- Cliquez sur Restrict Access.
- La boîte de dialogue affiche alors les membres de votre organisation disposant de l’autorisation Viewer par défaut.
- Utilisez le menu déroulant pour sélectionner un ou plusieurs rôles, équipes ou utilisateurs autorisés à modifier le monitor.
- Cliquez sur Add.
- La boîte de dialogue indique alors que le rôle sélectionné possède l’autorisation Editor.
- Cliquez sur Done.
Remarque : afin de toujours pouvoir accéder au monitor, vous devez inclure au moins un de vos rôles ou une de vos équipes avant d’enregistrer vos modifications.
Pour rétablir les autorisations globales d’un monitor restreint, procédez comme suit :
- Lorsque vous consultez un monitor, cliquez sur le menu déroulant More.
- Sélectionnez Permissions.
- Cliquez sur Restore Full Access.
- Cliquez sur Save.
Pour aller plus loin
Documentation, liens et articles supplémentaires utiles: