Parsing de log : bonnes pratiques à adopter
Datadog vous permet de définir des parsers afin d’extraire toutes les informations pertinentes figurant dans vos logs. Consultez notre documentation pour en savoir plus sur le langage de parsing et sur ses applications.
Cet article décrit comment procéder au parsing d’un log à partir du log du Collector de l’Agent Datadog :
2017-10-12 08:54:44 UTC | INFO | dd.collector | checks.collector(collector.py:530) | Finished run #1780. Collection time: 4.06s. Emit time: 0.01s
Ajoutez toujours en commentaire à votre règle l’exemple de log sur lequel vous travaillez :
Il est possible de tester votre règle de parsing dans un exemple de log. Cet exemple simplifie la rédaction initiale de la règle et peut s’avérer utile si jamais vous cherchez à résoudre un problème ou à prendre en charge un nouveau format de log.**Pour que le parsing ne cible qu’un seul attribut, utilisez l’astérisque (*) ** :
Il n’est pas nécessaire d’écrire une règle de parsing du log entier en une seule fois. Vérifiez un par un les attributs de votre règle en ajoutant un astérisque .* à la fin de la règle. Vous obtiendrez ainsi tous les résultats correspondant à la fin de votre règle.
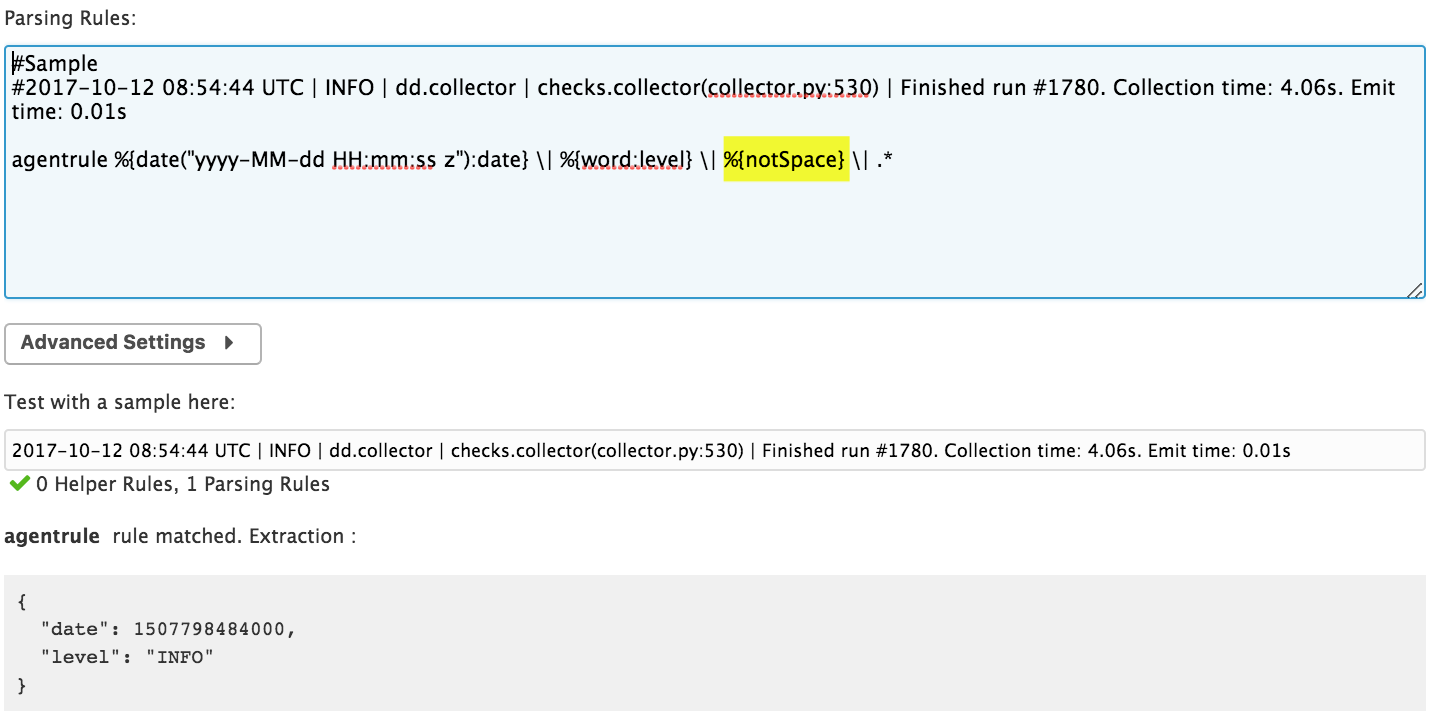
Ici, vous voulez par exemple parser la date du log, peu importe ce qui suit. Créez la règle ci-dessous :
Vous savez alors que la date est parsée correctement. Vous pouvez maintenant passer à l’attribut suivant : la gravité.
Vous devez commencer par échapper la barre verticale (il est obligatoire d’échapper les caractères spéciaux), puis faire correspondre le mot :Vous pouvez ensuite continuer jusqu’à l’extraction de tous les attributs souhaités de ce log.Utilisez les bons matchers :
pourquoi faire compliqué quand on peut faire simple. Souvent, il n’y a pas besoin d’essayer de définir une expression régulière complexe pour faire correspondre une expression spécifique, alors qu’un simple notSpace peut s’en charger.
Tenez compte des matchers suivants lors de la création d’une règle de parsing :
- notSpace : renvoie tous les caractères jusqu’à la prochaine espace.
- data : renvoie tous les caractères (similaire à « .* »).
- word : renvoie tous les prochains caractères alphanumériques.
- integer : renvoie un nombre entier décimal et l’analyse en tant que nombre entier.
La plupart des règles peuvent être rédigées avec ces quatre matchers. Vous pouvez consulter la liste complète des matchers disponibles dans la documentation relative au parsing.
KeyValue :
sachez qu’il existe un filtre keyvalue vous permettant d’extraire automatiquement tous vos attributs.
Consultez nos exemples pour en savoir plus.
Ignorer une partie de votre message de log qui ne devrait pas être extraite en tant qu’attributs :
reprenons l’exemple :
2017-10-12 08:54:44 UTC | INFO | dd.collector | checks.collector(collector.py:530) | Finished run #1780. Collection time: 4.06s. Emit time: 0.01s
Supposez que l’information dd.collector ne vous intéresse pas. Vous ne souhaitez donc pas l’extraire en tant qu’attribut.
Vous devez alors supprimer la section d’extraction de la règle :
Pour aller plus loin
Documentation, liens et articles supplémentaires utiles: