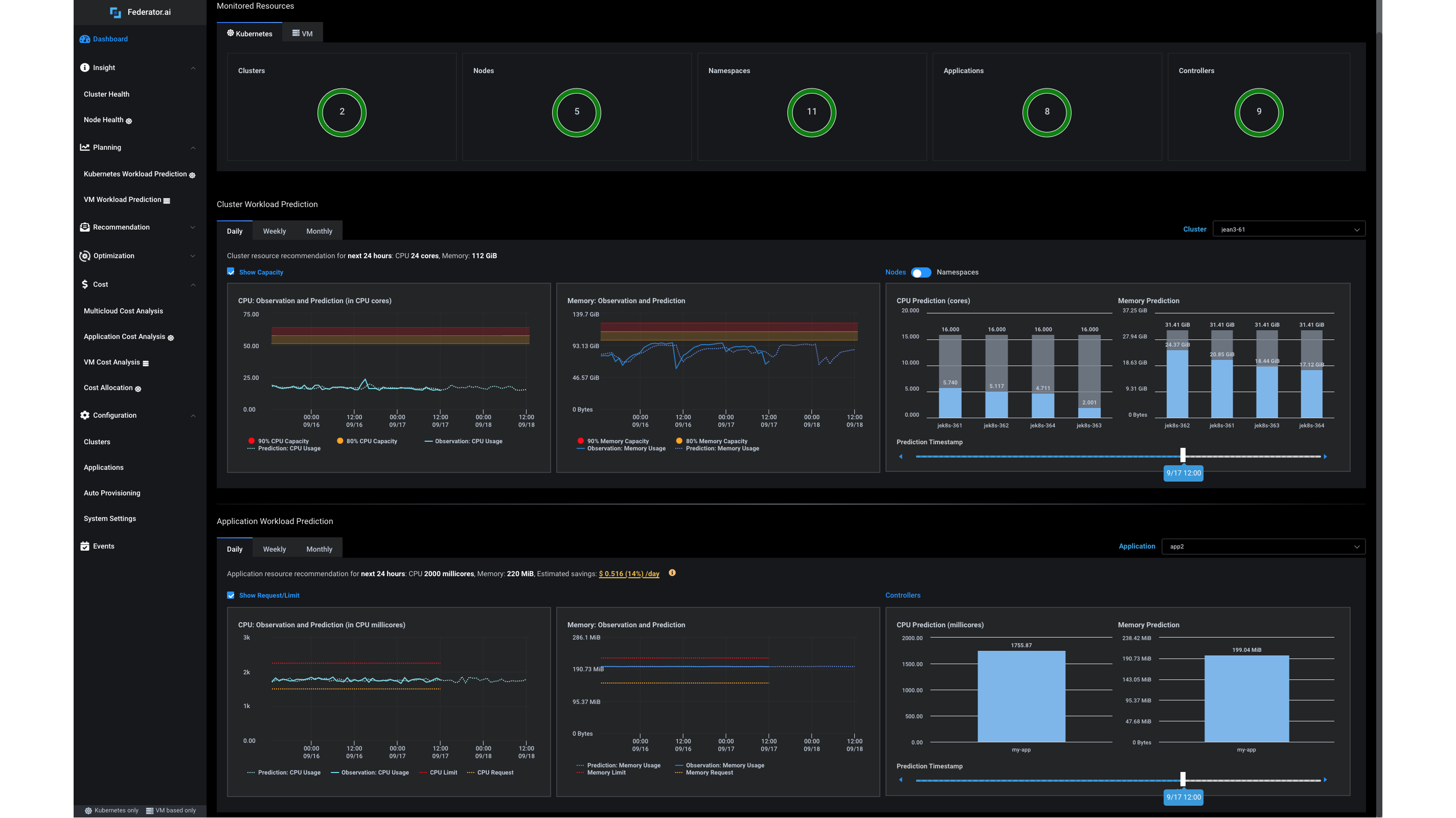
Le dashboard ProphetStor Federator.ai Cluster Overview affiche l'utilisation prévue des ressources et des recommandations pour les nœuds et clusters Kubernetes, ainsi que leur utilisation passée.
Le dashboard ProphetStor Federator.ai Application Overview affiche l'utilisation prévue du processeur et de la mémoire ainsi que des recommandations pour chaque application.
Le dashboard ProphetStor Federator.ai Kafka Overview affiche des données d'utilisation et des recommandations sur les réplicas de consommateurs Kafka.
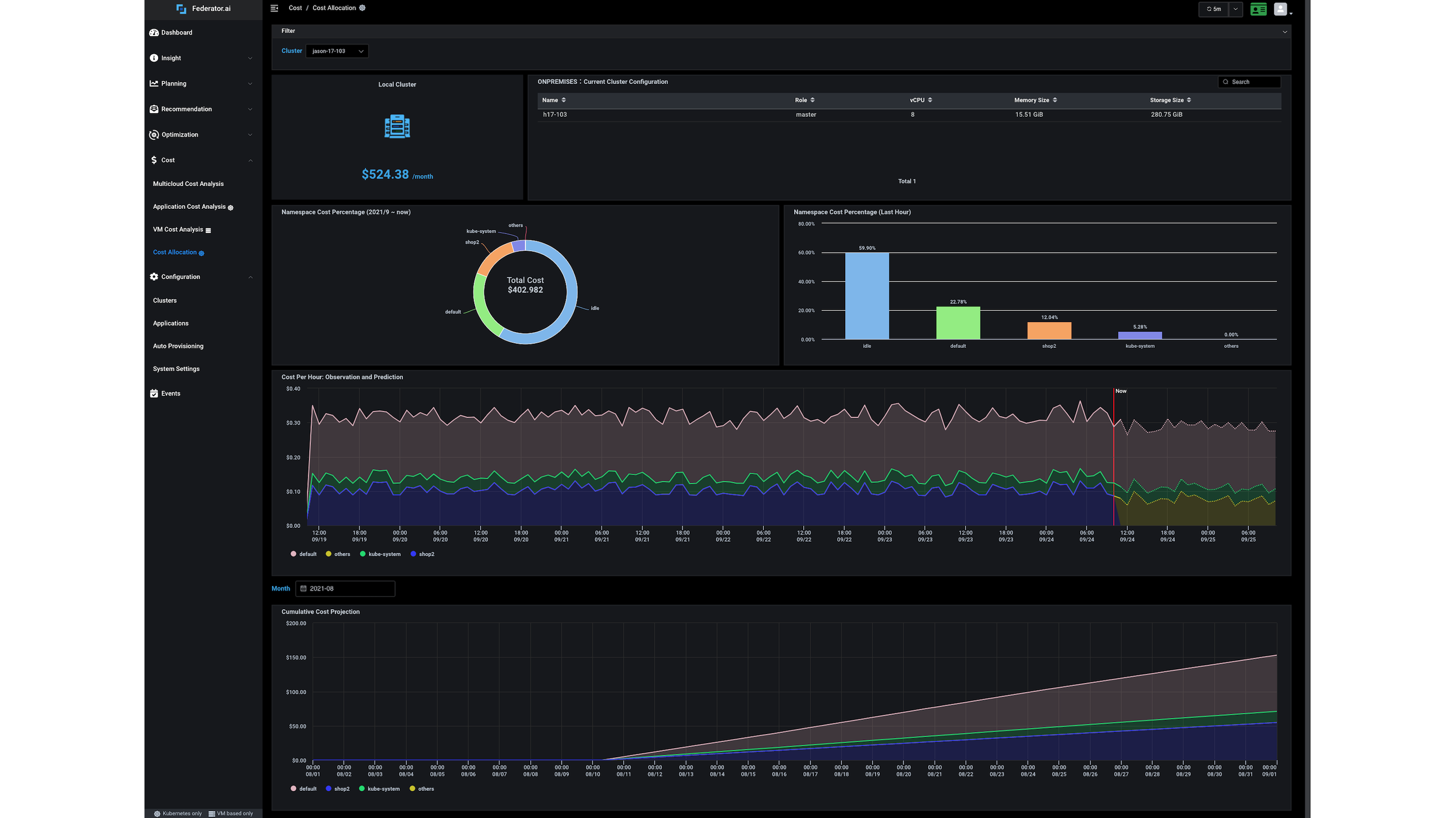
Le dashboard ProphetStor Federator.ai Cost Analysis Overview affiche le coût de déploiement d'un cluster Kubernetes, des recommandations concernant la configuration du cluster, ainsi qu'une estimation des coûts et économies associés au déploiement du cluster sur différents fournisseurs de cloud publics.
Le dashboard Federator.ai affiche la charge prévue ainsi que des recommandations pour les ressources des clusters et applications Kubernetes ou VMware.
Federator.ai offre des prédictions et des recommandations pour les ressources de vos clusters, nœuds, espaces de nommage, applications et contrôleurs
En fonction de la charge prévue d'un cluster, Federator.ai vous recommande la configuration la plus économique à utiliser pour chaque fournisseur de cloud public.
Federator.ai est capable d'analyser et de prévoir l'évolution des coûts pour chaque espace de nommage.
Présentation
ProphetStor Federator.ai est une solution basée sur l’IA conçue pour améliorer la gestion des ressources de calcul dans les clusters Kubernetes et de machines virtuelles (VM). Grâce à une observabilité holistique des opérations IT, notamment l’entraînement multi-tenant de modèles LLM, les ressources destinées aux applications critiques, aux espaces de nommage, aux nœuds et aux clusters peuvent être allouées efficacement, et les indicateurs de performance peuvent être atteints avec un minimum de gaspillage de ressources.
Prédiction de charge de travail basée sur l’IA pour les applications conteneurisées dans les clusters Kubernetes, ainsi que les VM dans VMware, Amazon Web Services (AWS) Elastic Compute Cloud (EC2), Azure Virtual Machine et Google Compute Engine
Recommandations intelligentes de ressources issues des prédictions de charge de travail, produites par des moteurs d’IA à partir des métriques opérationnelles
Un provisionnement automatique du CPU et de la mémoire pour les contrôleurs et espaces de nommage génériques des applications Kubernetes
Un autoscaling des conteneurs d’application Kubernetes, des groupes de consommateurs Kafka et des services en amont NGINX Ingress
Analyse des coûts MultiCloud optimale et recommandations basées sur les prédictions de charge de travail pour les clusters Kubernetes et les clusters de VM
Un système de calcul des coûts réels et des réductions de coûts potentielles reposant sur les recommandations de clusters, d’applications Kubernetes, de VM et d’espaces de nommage Kubernetes
Observabilité de l’entraînement LLM multi-tenants et optimisations de ressources exploitables sans compromettre les performances
ProphetStor Federator.ai fournit une observabilité full-stack via ses API intégrées aux Agents Datadog, depuis les charges applicatives, y compris l’entraînement LLM, jusqu’à la consommation de ressources au niveau du cluster. Cette intégration favorise une boucle dynamique entre supervision en temps réel et analytique prédictive, améliorant en continu la gestion des ressources, optimisant les coûts et garantissant un fonctionnement efficace des applications. Avec une licence ProphetStor Federator.ai, vous pouvez appliquer une solution basée sur l’IA pour suivre et prédire l’utilisation des ressources des conteneurs Kubernetes, des espaces de nommage et des nœuds de cluster, afin de formuler des recommandations permettant d’éviter à la fois la surprovisionnement coûteux et le sous-provisionnement néfaste pour les performances. En s’appuyant sur les prédictions de charge applicative, Federator.ai adapte automatiquement l’échelle des conteneurs au bon moment et optimise les performances avec le bon nombre de réplicas grâce à HPA Kubernetes ou au Watermark Pod Autoscaling (WPA) de Datadog.
Cette application est disponible via le Marketplace de Datadog et est prise en charge par un partenaire technologique de Datadog. Pour l’utiliser, achetez cette application dans le Marketplace.
1
2
rulesets:- %!s(<nil>) # Rules to enforce .
Request a personalized demo
Commencer avec Datadog
Datadog Docs AIYour use of this AI-powered assistant is subject to our Privacy Policy. Please do not submit sensitive or personal information.