Ce produit n'est pas pris en charge par le site Datadog que vous avez sélectionné. ().
La solution Data Streams Monitoring permet aux équipes d’analyser et de gérer leurs pipelines à grande échelle via un outil centralisé. Vous pourrez ainsi facilement :
Analyser la santé des pipelines en mesurant les latences de bout en bout des événements qui transitent par votre système.
Identifier les producteurs, les consommateurs et les files d’attente défectueux, puis visualiser les logs ou clusters associés pour accélérer le dépannage.
Empêcher les ralentissements en cascade en offrant aux propriétaires de services les outils dont ils ont besoin pour empêcher les événements en retard de surcharger les services en aval.
Langages et technologies pris en charge
Data Streams Monitoring instrumente les clients Kafka (consommateurs/producteurs). Si vous pouvez instrumenter votre infrastructure cliente, vous pouvez utiliser Data Streams Monitoring.
Java
Python
.NET
Node.js
Go
Ruby
Apache Kafka (auto-hébergé, Amazon MSK, Confluent Cloud ou toute autre plateforme d’hébergement)
Amazon Kinesis
Amazon SNS
Amazon SQS
Azure Service Bus
Google Pub/Sub
IBM MQ
RabbitMQ
Data Streams Monitoring nécessite des versions minimales du traceur Datadog. Consultez chaque page de configuration pour en savoir plus.
Prise en charge d’OpenTelemetry
Data Streams Monitoring prend en charge OpenTelemetry. Si vous avez configuré Datadog APM pour fonctionner avec OpenTelemetry, aucune configuration supplémentaire n’est requise pour utiliser Data Streams Monitoring. Consultez la section Compatibilité OpenTelemetry.
Configuration
Par langage
Par technologie
Explorer Data Streams Monitoring
Visualiser l’architecture de vos pipelines de données en streaming
Data Streams Monitoring fournit une carte topologique prête à l’emploi pour visualiser le flux de données dans vos pipelines et identifier les services producteurs/consommateurs, les dépendances des files d’attente, la propriété des services et les métriques de santé clés.
Mesurez la santé de vos pipelines de bout en bout avec de nouvelles métriques
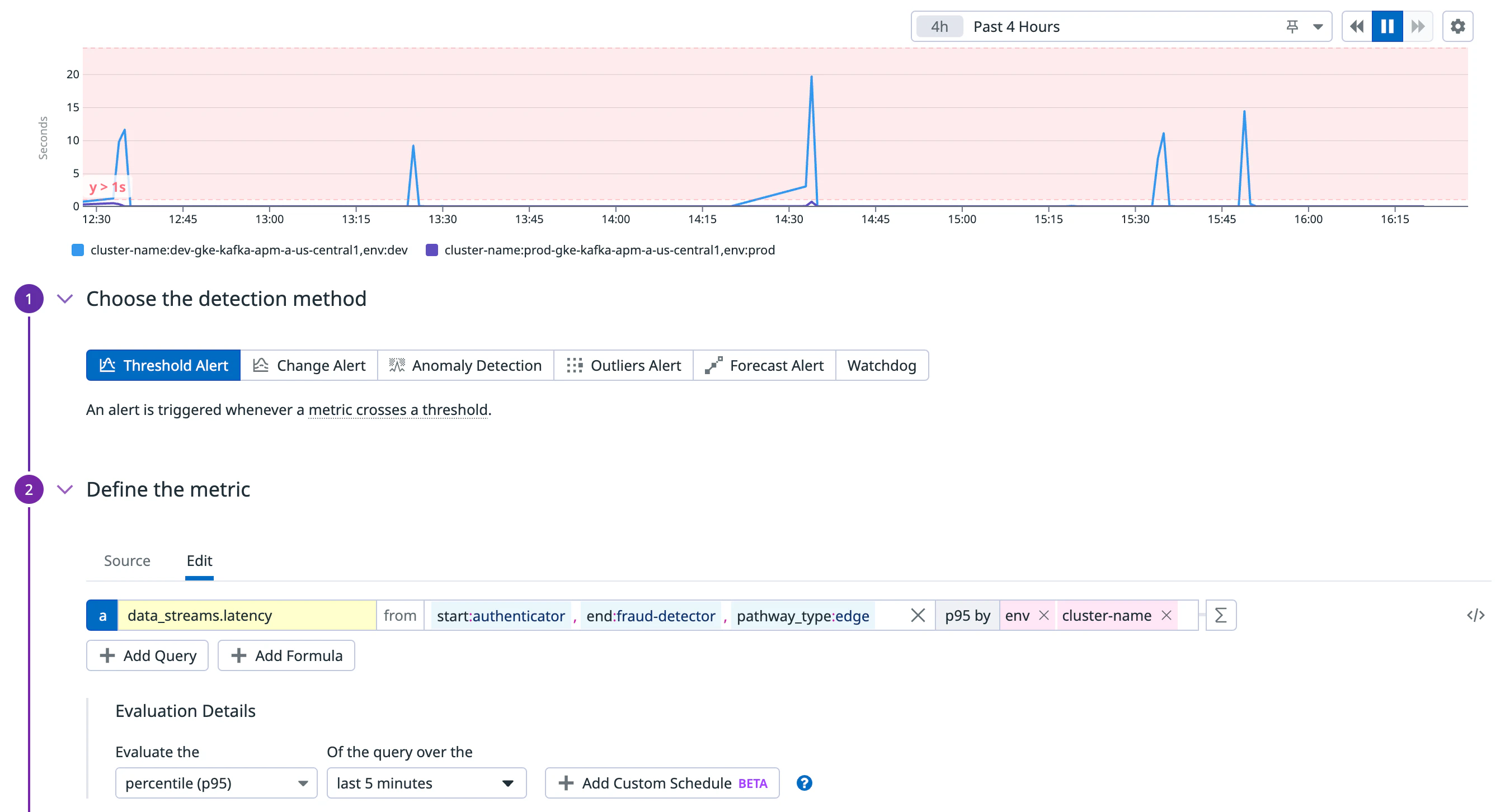
Avec Data Streams Monitoring, vous pouvez mesurer le temps qu’il faut habituellement aux événements pour traverser deux points quelconques de votre système asynchrone :
Nom de la métrique
Tags notables
Description
data_streams.latency
start, end, env
Latence de bout en bout d’un chemin entre une source spécifiée et un service de destination.
data_streams.kafka.lag_seconds
consumer_group, partition, topic, env
Délai mesuré entre le producteur et le consommateur, en secondes. Nécessite l’Agent Java v1.9.0 ou une version ultérieure.
data_streams.payload_size
consumer_group, topic, env
Débit entrant et sortant en octets
Vous pouvez également représenter graphiquement et visualiser ces métriques sur n’importe quel dashboard ou notebook :
Surveiller la latence de bout en bout d’un chemin
En fonction de la façon dont les événements transitent par votre système, certains chemins peuvent entraîner une latence plus élevée. Utilisez l’onglet Measure pour sélectionner un service de début et de fin pour obtenir des informations sur la latence de bout en bout, de façon à identifier les goulots d’étranglement et optimiser les performances. Vous pouvez facilement créer un monitor dédié à ce chemin ou exporter les données vers un dashboard.
Vous pouvez aussi cliquer sur un service pour ouvrir un volet latéral détaillé et consulter lʼonglet Pathways pour vérifier la latence entre le service et les services en amont.
Alerte sur les ralentissements dans les applications pilotées par des événements
Les ralentissements causés par des retards des consommateurs ou des messages trop anciens peuvent entraîner des défaillances en cascade et augmenter la fréquence des temps dʼarrêt. Grâce aux alertes prêtes à l’emploi, vous pouvez localiser les goulets d’étranglement dans vos pipelines et réagir immédiatement. Pour obtenir des métriques supplémentaires, Datadog propose des intégrations supplémentaires pour les technologies de file d’attente de messages telles que Kafka et SQS.
Grâce aux modèles de monitor prêts à l’emploi de Data Streams Monitoring, vous pouvez configurer des monitors sur des métriques telles que le lag des consommateurs, le débit et la latence en un seul clic.
Cliquez sur 'Add Monitors and Synthetic Tests' pour afficher les modèles de monitor
Attribuez des messages entrants à une file d’attente, un service ou un cluster
Un délai important sur un service consommateur, une utilisation accrue des ressources sur un broker Kafka ou une augmentation de la taille d’une file d’attente RabbitMQ ou Amazon SQS s’explique souvent par des changements dans la manière dont les services adjacents produisent ou consomment auprès de ces entités.
Cliquez sur l’onglet Throughput de n’importe quel service ou file d’attente dans Data Streams Monitoring pour détecter rapidement les changements de débit et identifier les services en amont ou en aval dont proviennent ces changements. Une fois le Software Catalog configuré, vous pouvez immédiatement accéder au canal Slack de l’équipe correspondante ou à l’ingénieur d’astreinte.
En affichant les données propres à un certain cluster Kafka, RabbitMQ ou Amazon SQS, vous pouvez détecter les variations du trafic entrant ou sortant pour l’ensemble des sujets ou files d’attente détectés sur le cluster en question :
Identifier rapidement les causes profondes dans l’infrastructure, les logs ou les traces
Datadog associe automatiquement l’infrastructure de vos services et les logs connexes via le tagging de service unifié, vous permettant ainsi d’identifier facilement les goulots d’étranglement. Cliquez sur l’onglet Infra, Logs ou Traces pour approfondir votre enquête et tenter de comprendre pourquoi la latence d’un chemin ou le délai d’un consommateur a augmenté.
Surveiller le débit et le statut des connecteurs
Datadog peut détecter automatiquement vos connecteurs Confluent Cloud gérés et les visualiser dans la carte topologique Data Streams Monitoring. Installez et configurez l’intégration Confluent Cloud pour collecter des informations sur vos connecteurs Confluent Cloud, notamment le débit, le statut et les dépendances des topics.
Pour aller plus loin
Documentation, liens et articles supplémentaires utiles: