Consulta de búsqueda
Todos los parámetros de búsqueda se incluyen en la url de la página, lo que puede ser útil para compartir tu vista.
Sintaxis de búsqueda
Una consulta se compone de términos y operadores.
Existen dos tipos de términos:
- Atributo de tramo: contenido del tramo (span), recopilado con instrumentación automática o manual en la aplicación.
- Etiqueta de tramo: mejoras de contexto relacionados con el tramo. Por ejemplo, etiquetas de host o contenedor que describen la infraestructura en la que se ejecuta el servicio.
Para combinar varios términos en una consulta compleja, utiliza cualquiera de los siguientes operadores booleanos:
| Operador | Descripción | Ejemplo |
|---|
AND | Intersección: ambos términos están en los eventos seleccionados (si no se añade nada, se toma AND por defecto). | autenticación Y fallo |
OR | Unión: cualquiera de los términos está en los eventos seleccionados. | autenticación O contraseña |
- | Exclusión: el término siguiente NO figura en el evento | autenticación Y contraseña |
Búsqueda de atributo
Para buscar un atributo de span (tramo), debes añadir @ al principio de la clave del atributo.
Por ejemplo, si deseas acceder a un tramo con el siguiente atributo a continuación, puedes utilizar:
@git.commit.sha:12345
"git": {
"commit": {
"sha": "12345"
},
"repository": {
"id": "github.com/datadog/datadog"
}
}
Los atributos de spans (tramos) son visibles en la pestaña Información general del panel lateral de traces (trazas).
Nota: No es necesario utilizar @ en los atributos reservados: env, operation_name, resource_name, service, status, span_id, timestamp, trace_id, type, link
Búsqueda por etiquetas
Tus spans (tramos) heredan etiquetas de hosts e integraciones que los generan.
Por ejemplo:
| Consulta | Coincidencia |
|---|
(hostname:web-server OR env:prod) | Todas las trazas con la etiqueta de infraestructura hostname:web-server o el atributo reservado env:prod |
(availability-zone:us-east OR container_name:api-frontend) | Todas las trazas con cualquiera de estas etiquetas de infraestructura |
(service:api AND -kube_deployment:canary) | Todas las trazas del servicio api que no están desplegados en el despliegue canary |
Las etiquetas de spans (tramos) son visibles en la pestaña Infraestructura del panel lateral de trazas.
Si tus etiquetas no siguen las prácticas recomendadas de etiquetas, no utilices la sintaxis key:value. En su lugar, utiliza la siguiente consulta de búsqueda:
tags:<MY_TAG>
Por ejemplo, esta etiqueta no sigue las prácticas recomendadas:
auto-discovery.cluster-autoscaler.k8s.io/daffy
Para buscar en esta etiqueta, utiliza la siguiente consulta:
tags:"auto-discovery.cluster-autoscaler.k8s.io/daffy"
Comodines
Para realizar una búsqueda con un comodín de varios caracteres, utiliza el símbolo * como se indica a continuación:
service:web* coincide con cada traza que tenga un servicio que empiece por web@url:data* coincide con cada traza que tenga una url que empiece por data.
Valores numéricos
Utiliza <,>, <=, o >= para realizar una búsqueda sobre atributos numéricos. Por ejemplo, recupera todas las trazas que tengan un tiempo de respuesta superior a 100 ms con:
@http.response_time:>100
También es posible buscar atributos numéricos dentro de un rango específico. Por ejemplo, recupera todos tus errores 4xx con:
@http.status_code:[400 TO 499]
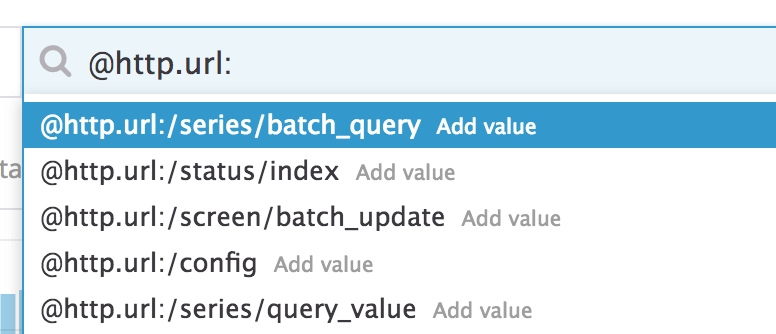
Autocompletar
Escribir una consulta compleja puede ser engorroso. Utiliza la función de autocompletar de la barra de búsqueda para completar tu consulta utilizando los valores existentes:
Caracteres especiales de escape
Los siguientes atributos se consideran especiales: ?, >, <, :, =,", ~, /, y \ requieren escape.
Por ejemplo, para buscar trazas que contengan user=JaneDoe en su url debe introducirse la siguiente búsqueda:
@url:*user\=JaneDoe*
La misma lógica debe aplicarse a los espacios dentro de los atributos de traza. No es recomendado tener espacios en los atributos de traza, pero en tales casos, los espacios requieren un escape.
Si un atributo se llama user.first name, realiza una búsqueda en este atributo con un espacio de escape:
@user.first\ name:myvalue
Búsquedas guardadas
No pierdas tiempo creando las mismas vistas todos los días. Las búsquedas guardadas contienen tu consulta de búsqueda, columnas y horizonte temporal. Están disponibles en la barra de búsqueda gracias a la coincidencia de autocompletar, ya sea por nombre de búsqueda o consulta.
Para eliminar una búsqueda guardada, haz clic en el icono de la papelera situado bajo el menú desplegable Buscar traza.
Buscar servicios y entidades
Para buscar un servicio, utiliza el atributo service. Para buscar otro tipo de entidad (por ejemplo, una base de datos, una cola o un proveedor externo), recurre a otros atributos de pares que Datadog utiliza para describir dependencias que no están instrumentadas con APM. Por ejemplo, para encontrar spans (tramos) que representen llamadas a una tabla users desde una base de datos postgres, utiliza la siguiente consulta: @peer.db.name:users @peer.db.system:postgres
Nota: La etiqueta service del tramo representa el servicio emitiendo el tramo si migraste a la nomenclatura del servicio global configurando DD_TRACE_REMOVE_INTEGRATION_SERVICE_NAME_ENABLED=true.
Rango de tiempo
El intervalo de tiempo te permite visualizar trazas dentro de un periodo determinado. Cambia rápidamente el intervalo de tiempo seleccionando un intervalo preestablecido en el menú desplegable (o introduciendo un intervalo de tiempo personalizado):
Tabla de tramo
La tabla de tramo es la lista de tramos que coinciden con el contexto seleccionado. Un contexto se define mediante un filtro de barra de búsqueda y un intervalo de tiempo.
La columna de servicio
Por defecto, la columna de servicio muestra el atributo reservado service del tramo.
Cuando el tramo representa una llamada de cliente desde un servicio instrumentado a un servicio inferido, la columna de servicio muestra:
el servicio, identificado por el atributo reservado service.
el servicio inferido: nombre de la entidad inferida a la que llama el servicio base, identificada por uno de los atributos de pares
Cuando el nombre del servicio es una modificación del nombre del servicio base, aparece la columna de servicio:
el servicio base: servicio desde el que se emite el tramo, identificado por el atributo @base_service.
la anulación del servicio: nombre del servicio, diferente del nombre de servicio base, establecido automáticamente en integraciones de Datadog o cambiado a través de la API programática. La anulación del servicio se identifica mediante el atributo reservado service.
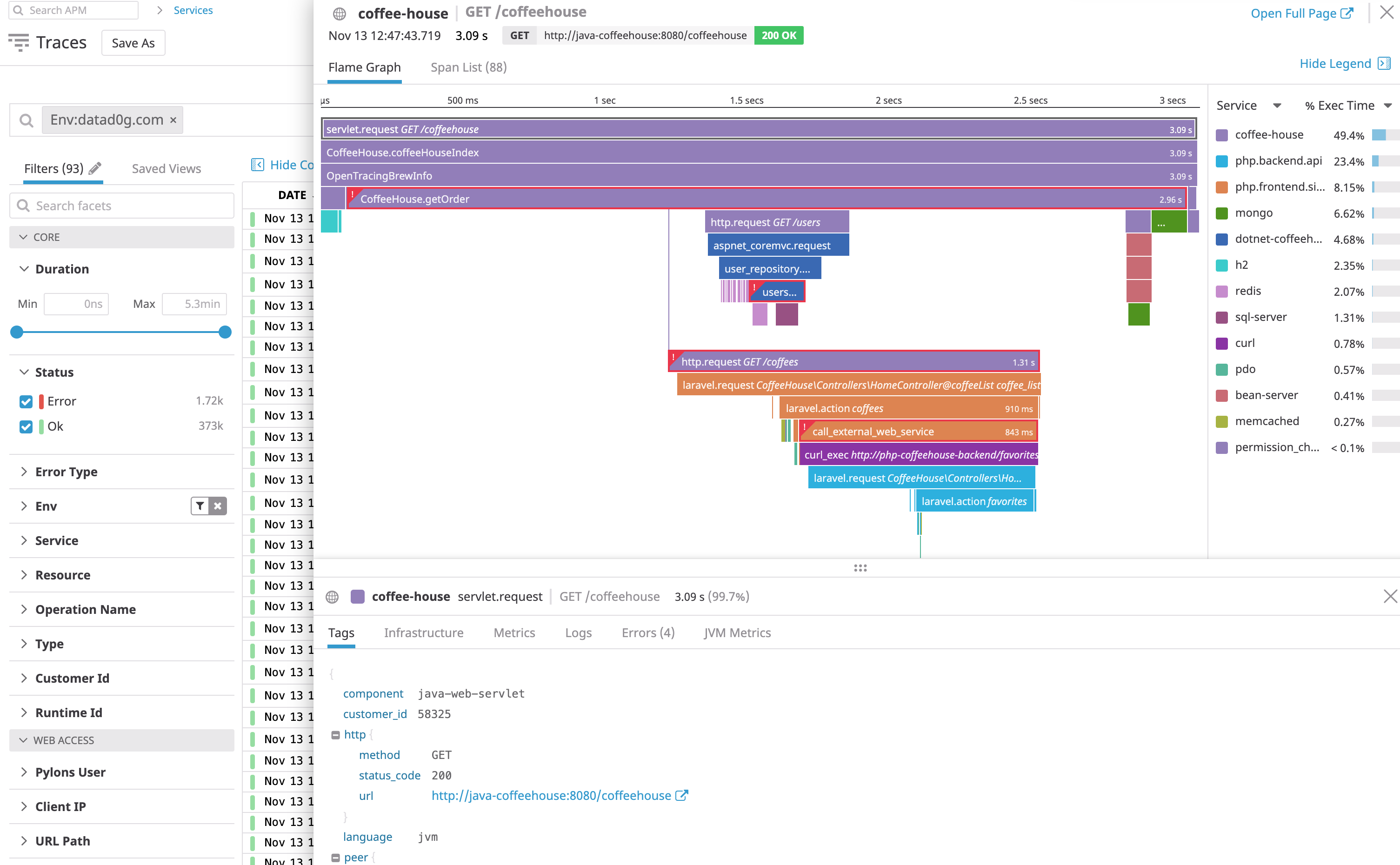
Visualización de una traza completa
Haz clic en cualquier tramo para ver los detalles sobre la traza asociada:
Columnas
Para añadir otras etiquetas de tramo o atributos como columnas a la lista, pulsa el botón Options (Opciones) y selecciona cualquier dimensión que desees añadir:
Grupos de rastreo
Agrupa la consulta por cualquier etiqueta o atributo de tramo para observar los recuentos de solicitudes, las tasas de error y las distribuciones de latencia en la vista de lista. Puedes seleccionar hasta cuatro dimensiones en la cláusula Agrupar por.
Consultas ‘Agrupar por’ avanzadas
Después de seleccionar una dimensión para la agrupación, puedes especificar de dónde obtener los valores de la dimensión utilizando el desplegable desde:
- Tramo: Agrupa utilizando la dimensión del tramo consultado (por defecto). Por ejemplo,
a. - Tramo principal: Agrupa utilizando la dimensión especificada del tramo principal de los tramos que coinciden con la consulta. Por ejemplo, para visualizar el rendimiento de un endpoint de API en función del servicio que lo llama, agrupa por
service desde parent(a). - Tramo raíz: Agrupa utilizando la dimensión especificada del tramo raíz de la traza. Por ejemplo, para analizar patrones de solicitudes de backend en función de las páginas de frontend desde las que se originan las solicitudes, agrupa por
@view.name desde root.
Ver grupos de rastreo en la lista de grupos
Los grupos de rastreo se muestran como valores únicos de la dimensión seleccionada. Cada grupo se muestra con tres métricas clave:
- SOLICITUDES: Recuento de tramos dentro del grupo.
- ERRORES: Tasa de error y recuento de errores.
- Latencia P95: Latencia p95 de los tramos.
Para ver estas métricas agregadas en el tramo principal o raíz, en lugar de en el tramo consultado, selecciona parent(a) o root en la sentencia Mostrar métricas desde.
Además, Latency Breakdown muestra el tiempo que transcurre entre diferentes servicios dentro de las solicitudes de cada grupo, lo que permite detectar visualmente los cuellos de botella de latencia de determinados grupos.
Para realizar un análisis más profundo, haz clic en cualquier grupo para examinar los eventos individuales de tramos que conforman las métricas agregadas.
Facetas
Una faceta muestra todos los valores distintos de un atributo o una etiqueta, además de proporcionar algunos análisis básicos, como la cantidad de trazas representada. También sirve para filtrar los datos.
Las facetas permiten girar o filtrar los conjuntos de datos en función de un atributo determinado. Ejemplos de facetas pueden incluir usuarios, servicios, etc…
Medidas
Las medidas son el tipo específico de facetas para valores cuantitativos.
Usa las medidas cuando necesites:
- Añadir valores de distintas trazas. Por ejemplo, crear una medida sobre el número de filas en Cassandra y visualizar los p95 o referenciadores superiores por la suma del tamaño de archivo solicitado.
- Calcular numéricamente los servicios con latencia más alta, por ejemplo, para valores del carrito de la compra superiores a $1000.
- Filtrar valores continuos, por ejemplo, el tamaño en bytes de cada segmento de carga útil en un flujo de vídeo.
Tipos
Las medidas vienen con un valor entero (largo) o doble, para capacidades equivalentes.
Unidades
Las medidas admiten unidades (tiempo en segundos o tamaño en bytes) para manejar órdenes de magnitud en el tiempo de consulta y el tiempo de visualización. La unidad es una propiedad de la propia medida, no del campo. Por ejemplo, considera una medida de duración en nanosegundos: tiene una etiqueta de tramo de service:A donde duration:1000 representa 1000 milliseconds, y otra etiqueta de tramo de service:B donde duration:500 representa 500 microseconds:
Escala la duración en nanosegundos para todas las etiquetas de tramo que fluyen con el procesador aritmético. Utiliza un multiplicador *1000000 en las etiquetas de tramo desde service:A, y un multiplicador *1000 en etiquetas de tramo desde service:B.
Utiliza duration:>20ms (consulta la sintaxis de búsqueda como referencia) para consultar sistemáticamente etiquetas de tramo desde ambos servicios a la vez, y ve un resultado agregado de un minuto como máximo.
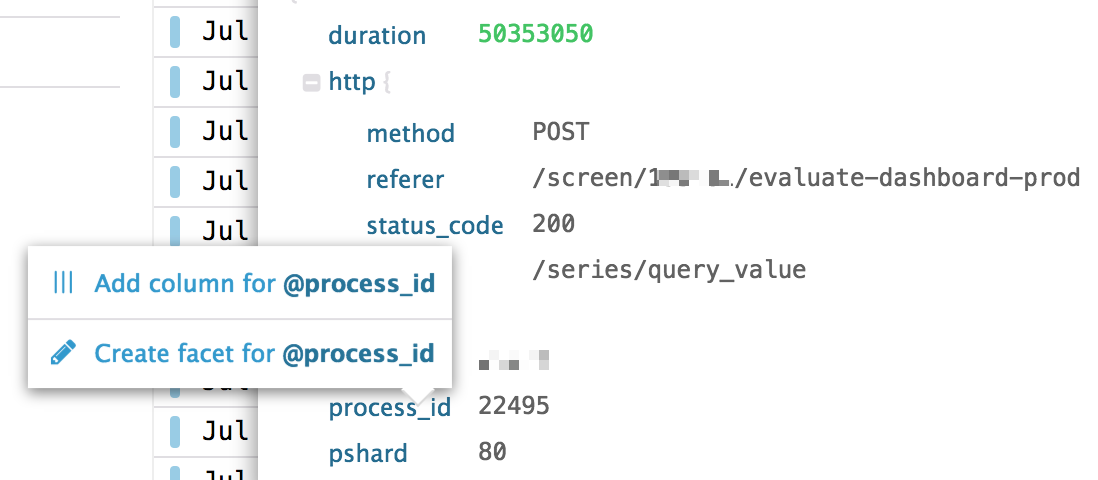
Crear una faceta
Para empezar a utilizar un atributo como faceta o en la búsqueda, haz clic en él y añádelo como faceta:
Después de crear una nueva faceta, está disponible en el panel de facetas para el filtrado y el análisis básico.
Panel de facetas
Utilice facetas para filtrar en tus trazas. La barra de búsqueda y la url reflejan automáticamente tus selecciones.
Visualizaciones
Selecciona un tipo de visualización de Analytics mediante el selector de Analytics:
Series temporales
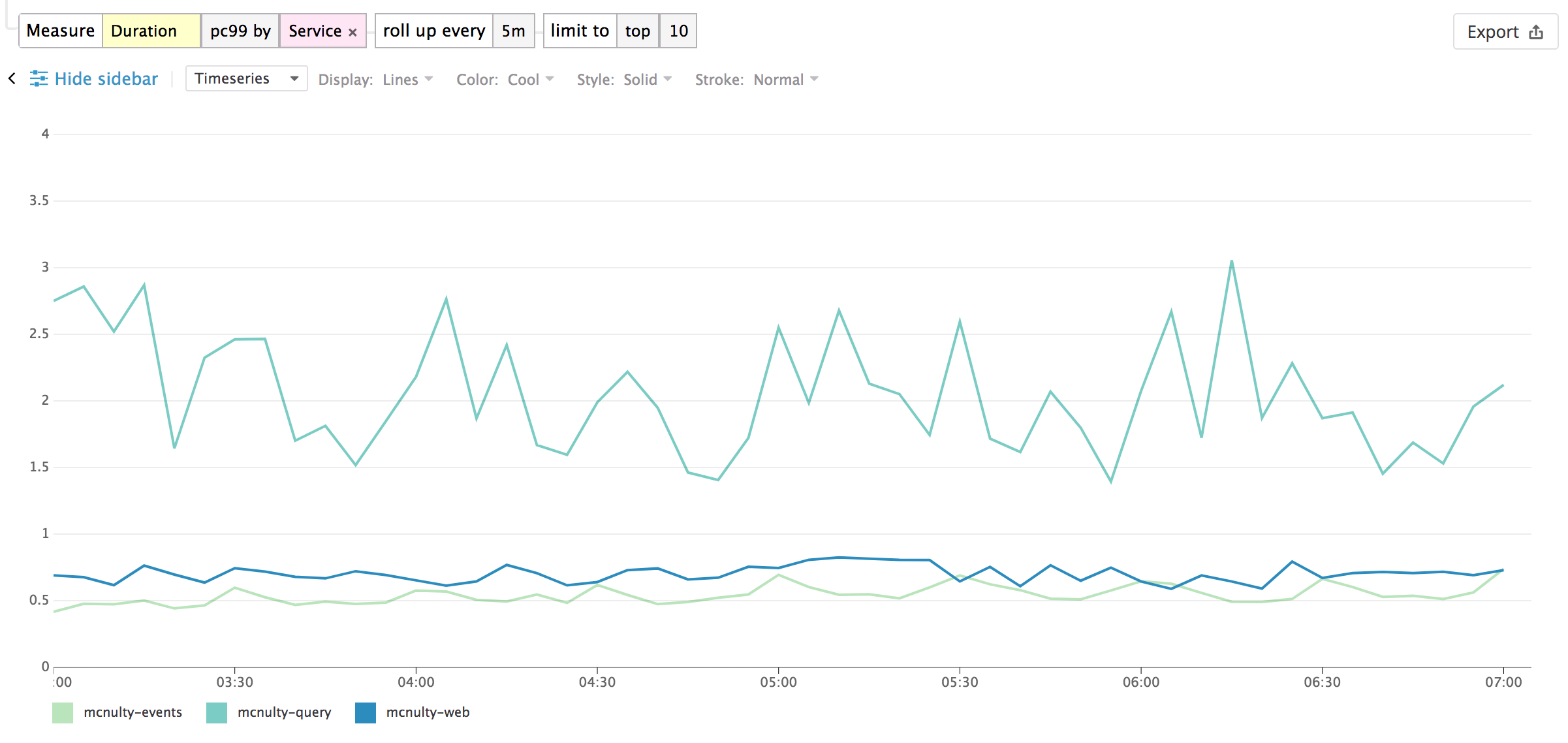
Visualiza la evolución de la métrica Duration (o una faceta de recuento único de valores) en un marco temporal seleccionado, y (opcionalmente) divide por una faceta disponible.
La siguiente serie temporal Analytics muestra la evolución de la duración pc99 por pasos de 5min para cada servicio
Lista principal
Visualiza los valores principales de una faceta según su Duration (o un recuento único de valores de la faceta).
La siguiente lista de principales de Analytics muestra los valores principales de duración pc99 del servicio:
Tabla
Visualiza los valores principales de una faceta según una medida elegida (la primera medida que elijas en la lista), y visualiza el valor de las medidas adicionales de los elementos que aparecen en esta lista de principales. Actualiza la consulta de búsqueda o investiga los logs correspondientes a cualquiera de las dimensiones.
- Cuando hay múltiples dimensiones, los valores máximos se determinan según la primera dimensión, luego según la segunda dimensión dentro de los valores máximos de la primera dimensión, luego según la tercera dimensión dentro de los valores máximos de la segunda dimensión.
- Cuando haya varias medidas, la lista superior o inferior se determina en función de la primera medida.
- El subtotal puede diferir de la suma real de valores de un grupo, ya que solo se muestra un subconjunto (principal o inferior). Los eventos con un valor nulo o vacío para esta dimensión no se muestran como subgrupo.
Nota: Una visualización de tabla utilizada para una sola medida y una sola dimensión es lo mismo que una lista, solo que con una visualización diferente.
La siguiente tabla de log de Analytics muestra la evolución de los códigos de estado principales en función de su rendimiento, junto con el número de IPs de cliente únicos, y durante los últimos 15 minutos:
Trazas relacionadas
Selecciona o haz clic en una sección del gráfico para ampliarlo o ver la página de lista de trazas correspondiente a tu selección:
Exportar
Exporta tus consultas:
También puedes generar una nueva métrica para la consulta.
Nota: Las consultas de APM en dashboards y notebooks se basan en todos los tramos indexados. Las consultas de APM en monitores se basan únicamente en tramos indexados por filtros de retención personalizados.
Referencias adicionales
Más enlaces, artículos y documentación útiles: