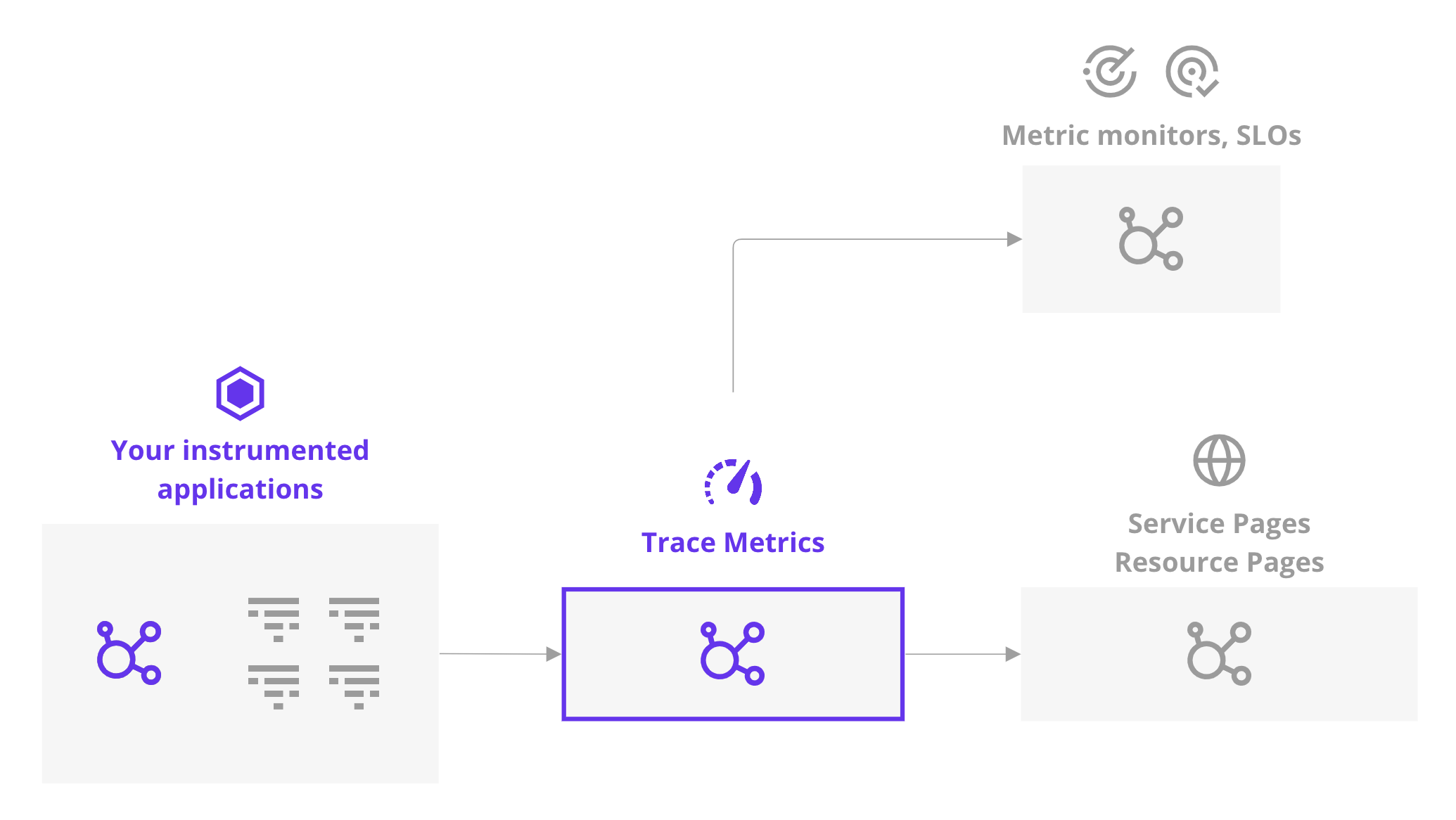
Las métricas de aplicaciones de rastreo se recopilan después de activar la recopilación de trazas e instrumentar tu aplicación.
Estas métricas capturan recuentos de solicitud, error y medidas de latencia. Se calculan basándose en el 100% del tráfico de la aplicación, independientemente de cualquier configuración de muestreo de ingesta de traza. Asegúrate de tener una visibilidad completa del tráfico de tu aplicación con estas métricas para detectar posibles errores en un servicio o un recurso, y creando dashboards, monitores y SLOs.
Nota: Si tus aplicaciones se instrumentan con bibliotecas de OpenTelemetry y el muestreo está configurado a nivel de SDK, las métricas de APM se calculan en función del conjunto de datos muestreados. Sin embargo, si el muestreo se configura a nivel de OpenTelemetry Collector y el procesador del muestreador está aguas arriba del conector Datadog, las métricas APM se calculan basándose en el 100% del tráfico de la aplicación.
Las métricas de traza se generan para los tramos (spans) de entrada del servicio y ciertas operaciones según el lenguaje de la integración. Por ejemplo, la integración de Django produce métricas de traza a partir de tramos que representan varias operaciones (1 tramo raíz para la solicitud de Django, 1 para cada middleware y 1 para la vista).
El espacio de nombre de las métricas de traza se formatea de esta manera:
trace.<SPAN_NAME>.<METRIC_SUFFIX>
Con las siguientes definiciones:
<SPAN_NAME>- Nombre de la operación o
span.name (ejemplos: redis.command, pylons.request, rails.request, mysql.query). <METRIC_SUFFIX>- Nombre de la métrica (ejemplos:
hits, errors, apdex, duration). Consulta la sección siguiente. <TAGS>- Rastrea etiquetas (tags) de métricas. Las etiquetas posibles son:
env, service, version, resource, http.status_code, http.status_class, rpc.grpc.status_code(requiere el Datadog Agent v7.65.0 o posterior) y etiquetas del Datadog Agent (incluyendo etiquetas primarias adicionales y del host). - Nota: Otras etiquetas configuradas en tramos no están disponibles como etiquetas en métricas de rastreo.
Sufijo de métrica
Solicitudes
trace (traza).<SPAN_NAME>.hits- Requisito previo: Esta métrica está disponible para cualquier servicio APM.
Descripción: Representa el recuento de tramos creados con un nombre específico (por ejemplo, redis.command, pylons.request, rails.request, o MySQL.query).
Tipo de métrica: COUNT.
Etiquetas: env, service, version, resource, resource_name, http.status_code, rpc.grpc.status_code, todas las etiquetas de host del Datadog Host Agent y las etiquetas primarias adicionales. trace.<SPAN_NAME>.hits.by_http_status- Requisito previo: Esta métrica está disponible para servicios HTTP/WEB APM si existen metadatos http.
Descripción: Representa el recuento de solicitudes de un determinado desglose de tramo por código de estado HTTP.
Tipo de métrica: COUNT.
Etiquetas: env, service, version, resource, resource_name, http.status_class, http.status_code, todas las etiquetas de host del Datadog Agent y las etiquetas primarias adicionales.
Distribución de la latencia
trace.<SPAN_NAME>- Requisito previo: Esta métrica está disponible para cualquier servicio APM.
Descripción: Representa la distribución de la latencia de todos los servicios, recursos y versiones en diferentes entornos y etiquetas primarias adicionales. Recomendado para todos los casos de uso de medición de la latencia.
Tipo de métrica: DISTRIBUTION.
Etiquetas: env, service,version, resource, resource_name, http.status_code, synthetics y las etiquetas primarias adicionales.
Errores
trace (traza).<SPAN_NAME>.errors- Requisito previo: Esta métrica está disponible para cualquier servicio APM.
Descripción: Representa el recuento de errores de un determinado tramo.
Tipo de métrica: COUNT.
Etiquetas: env, service, version, resource, resource_name, http.status_code, rpc.grpc.status_code, todas las etiquetas de host del host Datadog Agent y las etiquetas primarias adicionales. trace.<SPAN_NAME>.errors.by_http_status- Requisito previo: Esta métrica está disponible para cualquier servicio APM.
Descripción: Representa el recuento de errores de un determinado tramo.
Tipo de métrica: COUNT.
Etiquetas: env, service, version, resource, http.status_class, http.status_code, todas las etiquetas de host del Datadog Agent y las etiquetas primarias adicionales.
Apdex
trace.<SPAN_NAME>.apdex- Requisito previo: Esta métrica está disponible para cualquier servicio HTTP o APM web.
Descripción: Mide la puntuación Apdex de cada servicio web.
Tipo de métrica: GAUGE.
Etiquetas: env, service, version, resource / resource_name, synthetics y las etiquetas primarias adicionales.
Métricas legacy
Las siguientes métricas se mantienen con fines de compatibilidad con versiones anteriores. Para todos los casos de uso de medición de la latencia, Datadog recomienda especialmente utilizar métricas de distribución de la latencia.
Duración (legacy)
Importante: Las métricas de duración se mantienen solo por compatibilidad con versiones anteriores. Para todos los casos de uso de medición de latencia, Datadog recomienda encarecidamente utilizar
las métricas de distribución de latencia en su lugar, ya que proporcionan una mayor precisión para los cálculos de percentiles y el análisis general del rendimiento.
trace.<SPAN_NAME>.duration- Requisito previo: Esta métrica está disponible para cualquier servicio APM.
Descripción: Mide el tiempo total de una recopilación de tramos dentro de un intervalo de tiempo, incluyendo los tramos secundarios vistos en el servicio de recopilación. Para la mayoría de los casos de uso, Datadog recomienda utilizar la distribución de la latencia para el cálculo de la latencia media o de los percentiles. Para calcular la latencia media con filtros de etiqueta de host, puedes utilizar esta métrica con la siguiente fórmula:
sum:trace.<SPAN_NAME>.duration{<FILTER>}.rollup(sum).fill(zero) / sum:trace.<SPAN_NAME>.hits{<FILTER>}.rollup(sum).fill(zero)
Esta métrica no admite agregaciones de percentiles. Para obtener más información, consulta la sección Distribución de la latencia.
Tipo de métrica: GAUGE.
Etiquetas: env, service, resource, http.status_code, todas las etiquetas de host del Datadog Agent y las etiquetas primarias adicionales.
Duración (legacy)
Importante: Las métricas de duración se mantienen solo por compatibilidad con versiones anteriores. Para todos los casos de uso de medición de latencia, Datadog recomienda encarecidamente utilizar
las métricas de distribución de latencia en su lugar, ya que proporcionan una mayor precisión para los cálculos de percentiles y el análisis general del rendimiento.
trace.<SPAN_NAME>.duration.by_http_status- Requisito: Esta métrica existe para servicios APM HTTP/WEB si existen metadatos http.
Descripción: Mide el tiempo total de recopilación de tramos de cada estado HTTP. Específicamente, es la parte relativa del tiempo empleado por todos los tramos durante un intervalo y un estado HTTP concreto, incluyendo el tiempo de espera de los procesos secundarios.
Tipo de métrica: GAUGE.
Etiquetas: env, service, resource, http.status_class, http.status_code, todas las etiquetas del Datadog Host Agent y las etiquetas primarias adicionales.
Impacto del muestreo en métricas de rastreo
En la mayoría de los casos, las métricas de rastreo se calculan sobre la base de todo el tráfico de la aplicación. Sin embargo, con determinadas configuraciones de muestreo de la ingesta de trazas, las métricas representan solo un subconjunto de todas las solicitudes.
Muestreo del lado de la aplicación
Algunas bibliotecas de rastreo admiten el muestreo del lado de la aplicación, que reduce el número de tramos antes de que se envíen al Datadog Agent. Por ejemplo, la biblioteca de rastreo Ruby proporciona un muestreo del lado de la aplicación para reducir la sobrecarga de rendimiento. Sin embargo, esto puede afectar a las métricas de rastreo, ya que el Datadog Agent necesita todos los tramos para calcular métricas precisas.
Muy pocas bibliotecas de rastreo admiten esta configuración y por lo general no se recomienda su uso.
Muestreo OpenTelemetry
Los mecanismos de muestreo nativos del SDK de OpenTelemetry reducen el número de tramos enviados al Datadog Collector, lo que resulta en métricas de rastreo muestreadas y potencialmente imprecisas.
Muestreo X-Ray
Los tramos X-Ray se muestrean antes de enviarse a Datadog, lo que significa que las métricas de rastreo podrían no reflejar la totalidad del tráfico.
Referencias adicionales
Más enlaces, artículos y documentación útiles: