(LEGACY) Diseño y principios de despliegue
Este producto no es compatible con el
sitio Datadog seleccionado. (
).
Observability Pipelines no está disponible en el sitio US1-FED Datadog.
If you upgrade your OP Workers version 1.8 or below to version 2.0 or above, your existing pipelines will break. Do not upgrade your OP Workers if you want to continue using OP Workers version 1.8 or below. If you want to use OP Worker 2.0 or above, you must migrate your OP Worker 1.8 or earlier pipelines to OP Worker 2.x.
Datadog recommends that you update to OP Worker versions 2.0 or above. Upgrading to a major OP Worker version and keeping it updated is the only supported way to get the latest OP Worker functionality, fixes, and security updates.
Cuando empieces a desplegar el Worker de Observability Pipelines en tu infraestructura, puede que te surjan preguntas como las siguientes:
- ¿Dónde debe desplegarse el Worker de Observability Pipelines en la red?
- ¿Cómo deben recopilarse los datos?
- ¿Dónde deben tratarse los datos?
Esta guía te mostrará lo que debes tener en cuenta a la hora de diseñar la arquitectura de tu Worker de Observability Pipelines, específicamente:
Redes
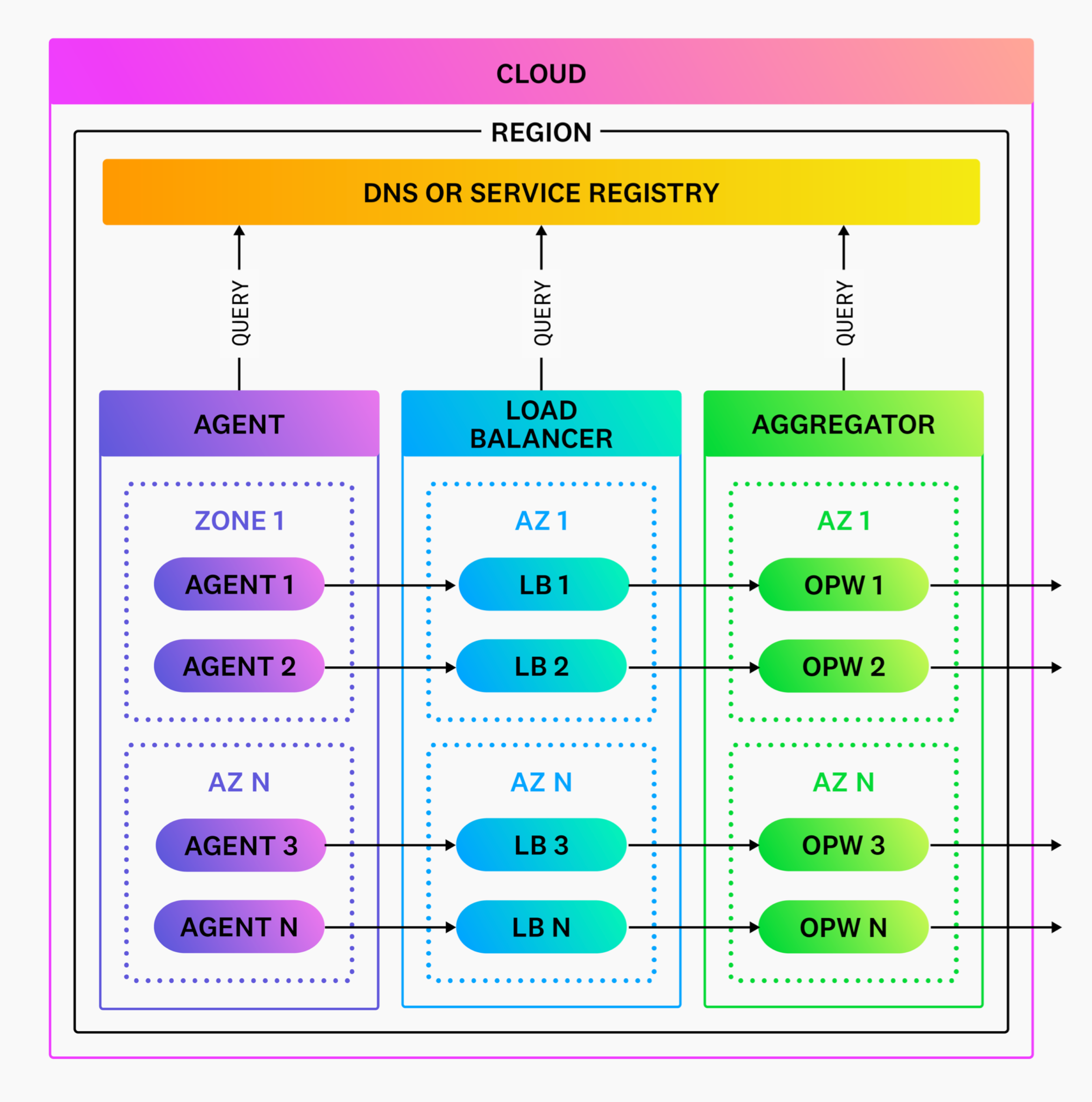
El primer paso en la arquitectura de tu despliegue del Worker de Observability Pipelines es comprender dónde encaja el Worker de Observability Pipelines dentro de tu red y dónde desplegarlo.
Trabajar con límites de red
Dado que el Worker de Observability Pipelines se despliega como agregador, debe desplegarse dentro de los límites de tu red para minimizar los costes de salida. La entrada al Worker de Observability Pipelines nunca debe circular por la Internet pública. Por lo tanto, Datadog recomienda empezar con un agregador por región para simplificar las cosas.
Uso de cortafuegos y proxies
Cuando utilices cortafuegos, restringe la comunicación del agente a tus agregadores y restringe la comunicación del agregador a tus fuentes y sumideros configurados.
Si prefieres utilizar un proxy HTTP, el Worker de Observability Pipelines ofrece una opción global de proxy para dirigir todo el tráfico HTTP del Worker de Observability Pipelines a través de un proxy.
Uso de la detección de DNS y de servicios
La detección de los agregadores y los servicios de tu Worker de Observability Pipelines debe resolverse mediante la detección de DNS o de servicios. Esta estrategia facilita el enrutamiento y el balanceo de carga de tu tráfico, y es la forma en que tus agentes y balanceadores de carga detectan tus agregadores. Para una separación adecuada de las inquietudes, el Worker de Observability Pipelines no resuelve las consultas DNS y, en su lugar, delega esta tarea a un resolvedor a nivel de sistema (por ejemplo, resolución Linux).
Elegir protocolos
Al enviar datos al Worker de Observability Pipelines, Datadog recomienda elegir un protocolo que permita una fácil confirmación del balanceo de carga y de la entrega a nivel de aplicación. Las opciones HTTP y gRPC son las preferidas debido a su naturaleza ubicua y a la cantidad de herramientas y documentación disponibles para ayudar a operar de forma eficaz y eficiente servicios basados en HTTP/gRPC.
Elige la fuente que se ajuste a tu protocolo. Cada fuente de Worker de Observability Pipelines implementa diferentes protocolos. Por ejemplo, las fuentes y sumideros del Worker de Observability Pipelines utilizan gRPC para la comunicación entre Workers de Observability Pipelines, y la fuente HTTP te permite recibir datos a través de HTTP. Para conocer sus respectivos protocolos, consulta Fuentes.
Recopilación de datos
Tu pipeline comienza con la recopilación de datos. Tus servicios y sistemas generan datos* que pueden recopilarse y enviarse a tus destinos. La recopilación de datos se realiza con agentes, y comprender qué agentes utilizar garantiza que se recopilen los datos deseados.
Elegir agentes
Debes elegir el agente que optimice las capacidades de tu equipo de ingeniería para monitorizar sus sistemas. Por lo tanto, integra el Worker de Observability Pipelines con el mejor agente para ese trabajo y despliega el Worker de Observability Pipelines como agregador en nodos separados.
Por ejemplo, Datadog Network Performance Monitoring integra el Datadog Agent con sistemas específicos del proveedor y produce datos específicos del proveedor. Por lo tanto, el Datadog Agent debe recopilar los datos y enviarlos directamente a Datadog, ya que los datos no son un tipo de datos compatible con el Worker de Observability Pipelines.
Otro ejemplo es cuando el Datadog Agent recopila métricas de servicio y las enriquece con etiquetas (tags) de Datadog específicas del proveedor. En este caso, el Datadog Agent debería enviar las métricas directamente a Datadog o dirigirlas a través del Worker de Observability Pipelines. El Worker de Observability Pipelines no debería sustituir al Datadog Agent, ya que los datos que se producen se enriquecen de una forma que es específica del proveedor.
Cuando te integres con un agente, configura el Worker de Observability Pipelines para recibir datos directamente del agente en la red local y dirigirlos a través del Worker de Observability Pipelines. Para recibir datos de tus agentes, utiliza componentes de origen como datadog_agent o open_telemetry.
Reducir los riesgos para el agente
Cuando te integres con un agente, configúralo para ser un simple forwarder de datos y dirigir los tipos de datos compatibles a través del Worker de Observability Pipelines. De este modo, se reduce el riesgo de pérdida de datos y la interrupción del servicio al minimizar las responsabilidades del agente.
Procesamiento de datos
Si quieres diseñar un pipeline eficiente entre las fuentes y los sumideros de tu Worker de Observability Pipelines, te resultará útil comprender qué tipos de datos procesar y dónde debes hacerlo.
Elegir datos para procesar
Puedes utilizar el Worker de Observability Pipelines para procesar datos*. Sin embargo, los datos en tiempo real específicos del proveedor, como los datos de perfiles continuos, no son interoperables y generalmente no se benefician del procesamiento.
Procesamiento remoto
En el caso del procesamiento remoto, el Worker de Observability Pipelines puede desplegarse como agregador en nodos independientes.
El procesamiento de datos se traslada de tus nodos a nodos del agregador remotos. Se recomienda el procesamiento remoto para entornos que requieren una alta durabilidad y una alta disponibilidad (la mayoría de los entornos). Además, es más fácil de configurar, ya que no requiere una reestructuración de la infraestructura, necesaria al añadir un agente.
Para obtener más información, consulta Arquitectura del agregador.
Almacenamiento de datos en buffer
El lugar y la forma en que almacenas tus datos en buffer también pueden afectar a la eficacia de tu pipeline.
Elegir dónde almacenar datos en buffer
El almacenamiento en buffer debe producirse cerca de los destinos y cada destino debe tener su propio buffer aislado. Esto ofrece las siguientes ventajas:
- Cada destino puede configurar su buffer para satisfacer los requisitos del sumidero. Para obtener más información, consulta Elegir cómo almacenar datos en buffer.
- Al aislar buffers para cada destino se evita que un destino con un comportamiento inadecuado detenga todo el pipeline hasta que el buffer alcance la capacidad configurada.
Por esta razón, el Worker de Observability Pipelines empareja los buffers con sus sumideros.
Elegir cómo almacenar datos en buffer
Los buffers integrados en el Worker de Observability Pipelines simplifican el funcionamiento y eliminan la necesidad de complejos buffers externos.
Al elegir un tipo de buffer de Worker de Observability Pipelines, selecciona el tipo que sea óptimo para el objetivo del destino. Por ejemplo, tu sistema de registro debería utilizar buffers de disco para una alta durabilidad y tu sistema de análisis debería utilizar buffers de memoria para una baja latencia. Además, ambos buffers pueden desbordarse en otro buffer para evitar que la contrapresión se propague a tus clientes.
Enrutamiento de datos
El enrutamiento de los datos, para que tus agregadores los envíen al destino adecuado, es la pieza final del diseño de tu pipeline. Utiliza los agregadores para dirigir los datos de forma flexible al mejor sistema para tus equipos.
Separar los sistemas de registro y de análisis
Separa tu sistema de registro de tu sistema de análisis para optimizar el coste sin comprometer su finalidad. Por ejemplo, el sistema de registro puede crear lotes de grandes cantidades de datos a lo largo del tiempo y comprimirlos para minimizar los costes, garantizando al mismo tiempo una alta durabilidad de todos los datos. Y tu sistema de análisis puede muestrear y limpiar los datos para reducir el coste, manteniendo baja la latencia para los análisis en tiempo real.
Enrutamiento a tu sistema de registro (archivado)
Optimiza tu sistema de registro para que sea duradero y minimiza los costes haciendo lo siguiente:
- Sólo escribe en tu archivo desde el rol de agregador, para reducir la pérdida de datos debida a reinicios de nodos y fallos de software.
- Enfrenta el sumidero con un buffer de disco.
- Activa las confirmaciones de extremo a extremo en todas las fuentes.
- Configura
batch.max_bytes en 5 MiB o más, batch.timeout_secs en 5 minutos o más, y activa la compresión (por defecto para el archivado de sumideros, como el sumidero aws_s3). - Archiva los datos en bruto, sin procesar, para permitir su reproducción y reducir el riesgo de corrupción accidental de los datos durante el procesamiento.
Enrutamiento a tu sistema de análisis
Optimiza tu sistema de análisis mientras reduces costes, haciendo lo siguiente:
- Enfrenta el sumidero con un buffer de memoria.
- Configura
batch.timeout_sec en 5 segundos o menos (por defecto para sumideros de analísis, como datadog_logs). - Utiliza la transformación de
remap para eliminar los atributos no utilizados en los análisis. - Filtrar eventos no utilizado en los análisis
- Considerar la posibilidad de muestrear logs con
level info o inferior para reducir su volumen
* Observability Pipelines admite logs. La compatibilidad de las métricas está en fase beta.