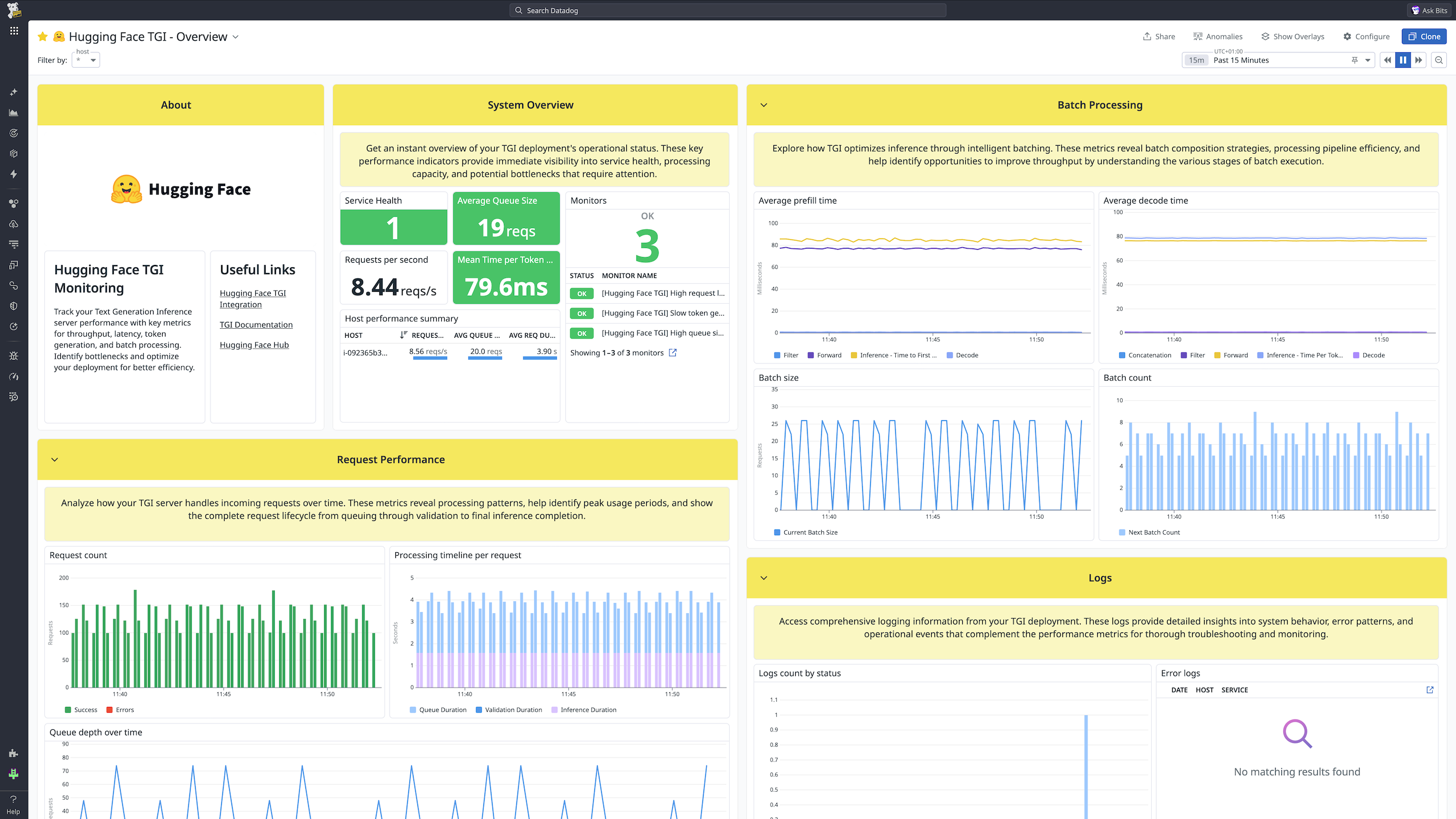
hugging_face_tgi.batch.concat.count
(count) | Number of batch concatenates |
hugging_face_tgi.batch.concat.duration.bucket
(count) | Batch concatenation duration distribution |
hugging_face_tgi.batch.concat.duration.count
(count) | Number of batch concatenation duration measurements |
hugging_face_tgi.batch.concat.duration.sum
(count) | Total batch concatenation duration
Shown as second |
hugging_face_tgi.batch.current.max_tokens
(gauge) | Maximum tokens the current batch will grow to
Shown as token |
hugging_face_tgi.batch.current.size
(gauge) | Current batch size
Shown as request |
hugging_face_tgi.batch.decode.duration.bucket
(count) | Batch decode duration distribution |
hugging_face_tgi.batch.decode.duration.count
(count) | Number of batch decode duration measurements |
hugging_face_tgi.batch.decode.duration.sum
(count) | Total batch decode duration
Shown as second |
hugging_face_tgi.batch.filter.duration.bucket
(count) | Batch filtering duration distribution |
hugging_face_tgi.batch.filter.duration.count
(count) | Number of batch filter duration measurements |
hugging_face_tgi.batch.filter.duration.sum
(count) | Total batch filter duration
Shown as second |
hugging_face_tgi.batch.forward.duration.bucket
(count) | Batch forward duration distribution |
hugging_face_tgi.batch.forward.duration.count
(count) | Number of batch forward duration measurements |
hugging_face_tgi.batch.forward.duration.sum
(count) | Total batch forward duration
Shown as second |
hugging_face_tgi.batch.inference.count
(count) | Total number of batch inferences |
hugging_face_tgi.batch.inference.duration.bucket
(count) | Batch inference duration distribution |
hugging_face_tgi.batch.inference.duration.count
(count) | Number of batch inference duration measurements |
hugging_face_tgi.batch.inference.duration.sum
(count) | Total batch inference duration
Shown as second |
hugging_face_tgi.batch.inference.success.count
(count) | Number of successful batch inferences |
hugging_face_tgi.batch.next.size.bucket
(count) | Next batch size distribution |
hugging_face_tgi.batch.next.size.count
(count) | Number of next batch size measurements |
hugging_face_tgi.batch.next.size.sum
(count) | Total next batch size
Shown as request |
hugging_face_tgi.queue.size
(gauge) | Number of requests waiting in the internal queue
Shown as request |
hugging_face_tgi.request.count
(count) | Total number of requests received
Shown as request |
hugging_face_tgi.request.duration.bucket
(count) | Request duration distribution |
hugging_face_tgi.request.duration.count
(count) | Number of request duration measurements |
hugging_face_tgi.request.duration.sum
(count) | Total request duration
Shown as second |
hugging_face_tgi.request.failure.count
(count) | Number of failed requests
Shown as request |
hugging_face_tgi.request.generated_tokens.bucket
(count) | Generated tokens per request distribution |
hugging_face_tgi.request.generated_tokens.count
(count) | Number of generated token measurements |
hugging_face_tgi.request.generated_tokens.sum
(count) | Total generated tokens
Shown as token |
hugging_face_tgi.request.inference.duration.bucket
(count) | Request inference duration distribution |
hugging_face_tgi.request.inference.duration.count
(count) | Number of request inference duration measurements |
hugging_face_tgi.request.inference.duration.sum
(count) | Total request inference duration
Shown as second |
hugging_face_tgi.request.input_length.bucket
(count) | Input token length per request distribution |
hugging_face_tgi.request.input_length.count
(count) | Number of input length measurements |
hugging_face_tgi.request.input_length.sum
(count) | Total input length
Shown as token |
hugging_face_tgi.request.max_new_tokens.bucket
(count) | Maximum new tokens per request distribution |
hugging_face_tgi.request.max_new_tokens.count
(count) | Number of max new tokens measurements |
hugging_face_tgi.request.max_new_tokens.sum
(count) | Total max new tokens
Shown as token |
hugging_face_tgi.request.mean_time_per_token.duration.bucket
(count) | Mean time per token duration distribution |
hugging_face_tgi.request.mean_time_per_token.duration.count
(count) | Number of mean time per token measurements |
hugging_face_tgi.request.mean_time_per_token.duration.sum
(count) | Total mean time per token duration
Shown as second |
hugging_face_tgi.request.queue.duration.bucket
(count) | Request queue duration distribution |
hugging_face_tgi.request.queue.duration.count
(count) | Number of request queue duration measurements |
hugging_face_tgi.request.queue.duration.sum
(count) | Total request queue duration
Shown as second |
hugging_face_tgi.request.skipped_tokens.count
(count) | Number of skipped token measurements |
hugging_face_tgi.request.skipped_tokens.quantile
(gauge) | Skipped tokens per request quantile
Shown as token |
hugging_face_tgi.request.skipped_tokens.sum
(count) | Total skipped tokens
Shown as token |
hugging_face_tgi.request.success.count
(count) | Number of successful requests
Shown as request |
hugging_face_tgi.request.validation.duration.bucket
(count) | Request validation duration distribution |
hugging_face_tgi.request.validation.duration.count
(count) | Number of request validation duration measurements |
hugging_face_tgi.request.validation.duration.sum
(count) | Total request validation duration
Shown as second |