init_config:instances:- ceph_cmd:/path/to/your/ceph# default is /usr/bin/cephuse_sudo:true# only if the ceph binary needs sudo on your nodes
Si has habilitado use_sudo, añade una línea como la siguiente a tu archivo sudoers:
dd-agent ALL=(ALL) NOPASSWD:/path/to/your/ceph
Recopilación de logs
Disponible para las versiones 6.0 o posteriores del Agent
La recopilación de logs está desactivada en forma predeterminada en el Datadog Agent, actívala en tu archivo datadog.yaml:
logs_enabled:true
Luego, edita ceph.d/conf.yaml al quitar los comentarios de las líneas logs de la parte inferior. Actualiza la path de los logs con la ruta correcta a tus archivos de logs de Ceph.
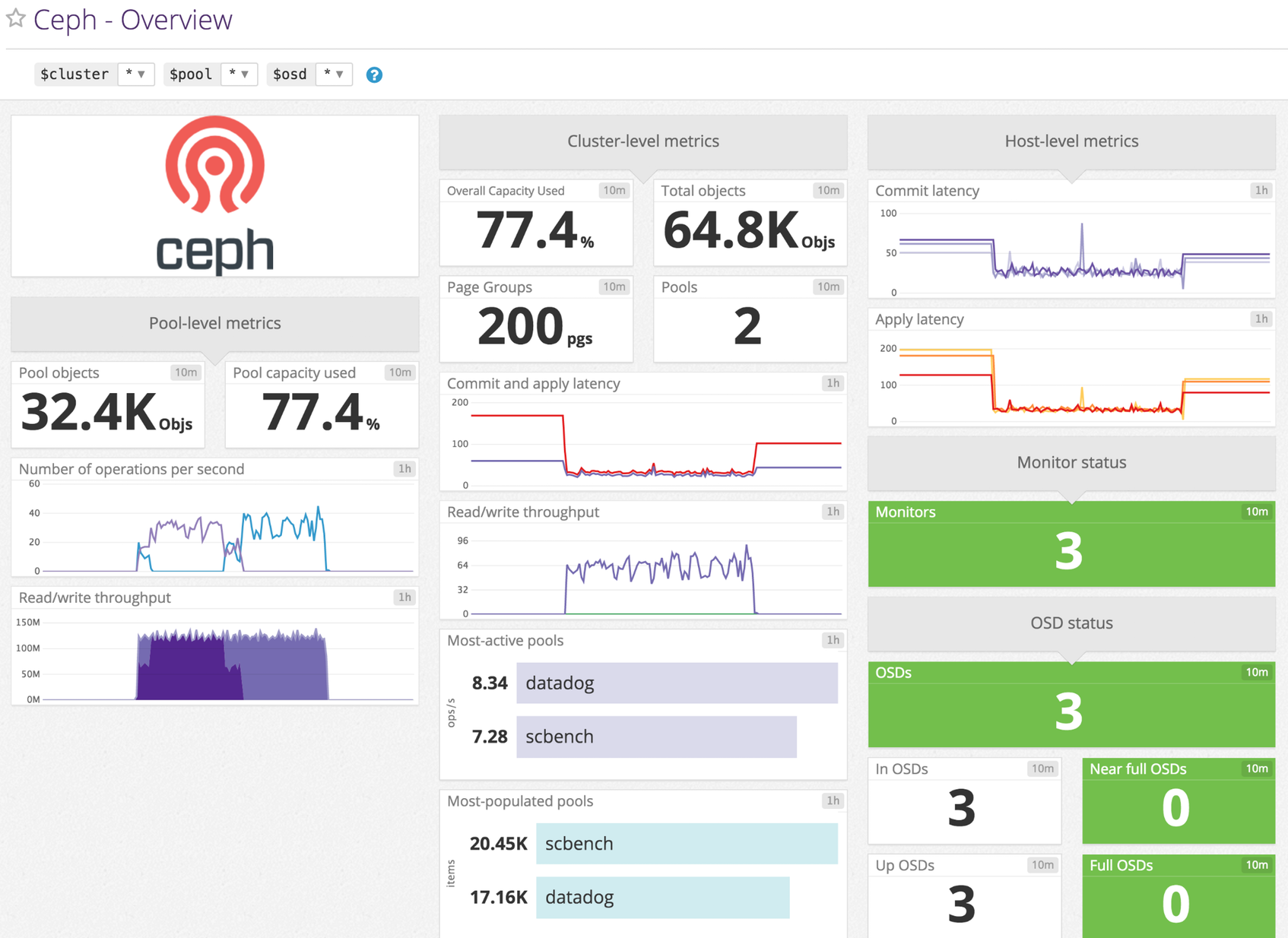
Métrica de uso de la capacidad global Se muestra como porcentaje.
ceph.apply_latency_ms (gauge)
Tiempo que se tarda en enviar una actualización a los discos Se muestra como milisegundo
ceph.class_pct_used (gauge)
Porcentaje por clase de almacenamiento bruto utilizado Se muestra como porcentaje
ceph.commit_latency_ms (gauge)
Tiempo que se tarda en confirmar una operación en el diario Se muestra como milisegundo
ceph.misplaced_objects (gauge)
Número de objetos extraviados Se muestra como elemento
ceph.misplaced_total (gauge)
Número total de objetos si hay objetos extraviados Se muestra como elemento
ceph.num_full_osds (gauge)
Número de OSD completas Se muestra como elemento
ceph.num_in_osds (gauge)
Número de daemons de almacenamiento participantes Se muestra como elemento
ceph.num_mons (gauge)
Número de daemons de monitor Se muestra como elemento
ceph.num_near_full_osds (gauge)
Número de OSD casi completas Se muestra como elemento
ceph.num_objects (gauge)
Recuento de objetos de un grupo determinado Se muestra como elemento
ceph.num_osds (gauge)
Número de daemons de almacenamiento conocidos Se muestra como elemento
ceph.num_pgs (gauge)
Número de grupos de colocación disponibles Se muestra como elemento
ceph.num_pools (gauge)
Número de grupos Se muestra como elemento
ceph.num_up_osds (gauge)
Número de daemons de almacenamiento en línea Se muestra como elemento
ceph.op_per_sec (gauge)
Operaciones de E/S por segundo para un grupo determinado Se muestra como operación
ceph.osd.pct_used (gauge)
Porcentaje utilizado de OSD completas/casi completas Se muestra como porcentaje.
ceph.pgstate.active_clean (gauge)
Número de grupos de colocación activos+limpios Se muestra como elemento
ceph.read_bytes (gauge)
Bytes de lectura por grupo Se muestra como byte
ceph.read_bytes_sec (gauge)
Bytes/segundo que se leen Se muestra como byte
ceph.read_op_per_sec (gauge)
Operaciones de lectura por grupo/segundo Se muestra como operación
ceph.recovery_bytes_per_sec (gauge)
Tasa de bytes recuperados Se muestra como byte
ceph.recovery_keys_per_sec (gauge)
Tasa de claves recuperadas Se muestra como elemento
ceph.recovery_objects_per_sec (gauge)
Tasa de objetos recuperados Se muestra como elemento
ceph.total_objects (gauge)
Recuento de objetos del almacén de objetos subyacente. [v<=3 only] Se muestra como elemento
ceph.write_bytes (gauge)
Bytes de escritura por grupo Se muestra como byte
ceph.write_bytes_sec (gauge)
Bytes/segundo que se escriben Se muestra como byte
ceph.write_op_per_sec (gauge)
Operaciones de escritura por grupo/segundo Se muestra como operación
Nota: Si estás ejecutando Ceph Luminous o posterior, la métrica ceph.osd.pct_used no está incluida.
Eventos
El check de Ceph no incluye eventos.
Checks de servicio
ceph.overall_status
Devuelve OK si el estado de tu clúster Ceph es HEALTH_OK, WARNING si es HEALTH_WARNING, CRITICAL en caso contrario.
Estados: ok, warning, critical
ceph.osd_down
Devuelve OK si no tienes ningún OSD caído. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.osd_orphan
Devuelve OK si no tienes ningún OSD huérfano. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.osd_full
Devuelve OK si tus OSD no están completas. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.osd_nearfull
Devuelve OK si tus OSD no están casi completas. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.pool_full
Devuelve OK si tus grupos no han alcanzado su cuota. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.pool_near_full
Devuelve OK si tus grupos no están cerca de alcanzar su cuota. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.pg_availability
Devuelve OK si hay plena disponibilidad de datos. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.pg_degraded
Devuelve OK si hay redundancia total de datos. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.pg_degraded_full
Devuelve OK si hay espacio suficiente en el cluster para la redundancia de datos. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.pg_damaged
Devuelve OK si no hay incoherencias tras la depuración de datos. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.pg_not_scrubbed
Devuelve OK si los PG fueron depurados recientemente. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.pg_not_deep_scrubbed
Devuelve OK si los PG fueron enteramente depurados recientemente. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.cache_pool_near_full
Devuelve OK si los grupos de caché no están casi llenos. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.too_few_pgs
Devuelve OK si el número de PG supera el umbral mínimo. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.too_many_pgs
Devuelve OK si el número de PG está por debajo del umbral máximo. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.object_unfound
Devuelve OK si se pueden encontrar todos los objetos. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.request_slow
Devuelve OK si las solicitudes tardan un tiempo normal en procesarse. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.
Estados: ok, warning, critical
ceph.request_stuck
Devuelve OK si las solicitudes tardan un tiempo normal en procesarse. En caso contrario, devuelve WARNING si la gravedad es HEALTH_WARN, si no devuelve CRITICAL.