For AI agents: A markdown version of this page is available at https://docs.datadoghq.com/data_streams/setup/language/python.md.
A documentation index is available at /llms.txt.
Python uses auto-instrumentation to inject and extract additional metadata required by Data Streams Monitoring for measuring end-to-end latencies and the relationship between queues and services. To enable Data Streams Monitoring, set the DD_DATA_STREAMS_ENABLED environment variable to true on services sending messages to (or consuming messages from) Kafka.
Data Streams Monitoring uses message headers to propagate context through Kafka streams. If log.message.format.version is set in the Kafka broker configuration, it must be set to 0.11.0.0 or higher. Data Streams Monitoring is not supported for versions lower than this.
Monitoring SQS pipelines
Data Streams Monitoring uses one message attribute to track a message’s path through an SQS queue. As Amazon SQS has a maximum limit of 10 message attributes allowed per message, all messages streamed through the data pipelines must have 9 or fewer message attributes set, allowing the remaining attribute for Data Streams Monitoring.
Monitoring RabbitMQ pipelines
The RabbitMQ integration can provide detailed monitoring and metrics of your RabbitMQ deployments. For full compatibility with Data Streams Monitoring, Datadog recommends configuring the integration as follows:
This ensures that all RabbitMQ graphs populate, and that you see detailed metrics for individual exchanges as well as queues.
Monitoring Kinesis pipelines
There are no message attributes in Kinesis to propagate context and track a message’s full path through a Kinesis stream. As a result, Data Streams Monitoring’s end-to-end latency metrics are approximated based on summing latency on segments of a message’s path, from the producing service through a Kinesis Stream, to a consumer service. Throughput metrics are based on segments from the producing service through a Kinesis Stream, to the consumer service. The full topology of data streams can still be visualized through instrumenting services.
Data Streams Monitoring propagates context through message headers. If you are using a message queue technology that is not supported by DSM, a technology without headers (such as Kinesis), use manual instrumentation to set up DSM.
Monitoring connectors
Confluent Cloud connectors
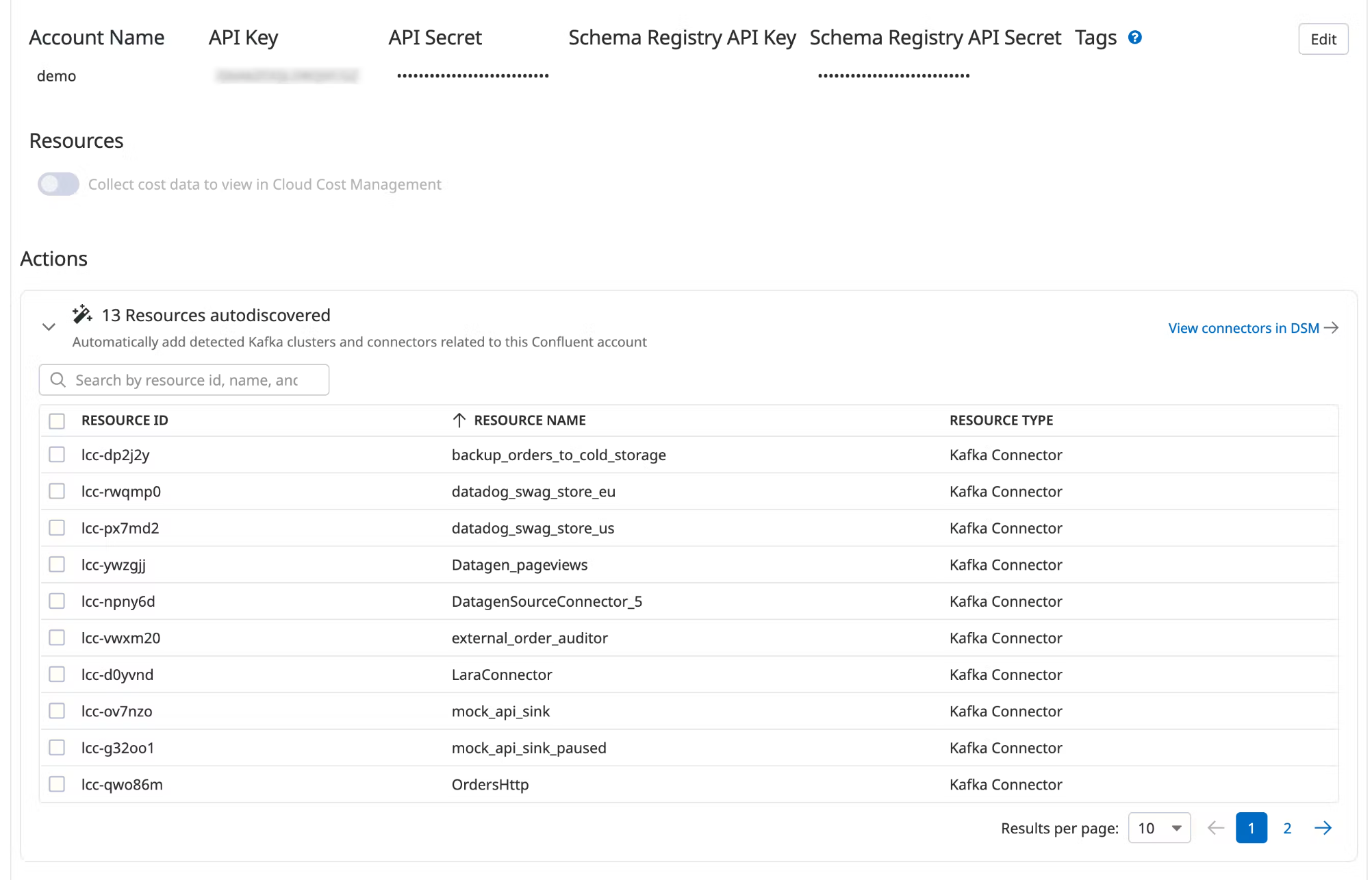
Data Streams Monitoring can automatically discover your Confluent Cloud connectors and visualize them within the context of your end-to-end streaming data pipeline.
Under Actions, a list of resources populates with detected clusters and connectors. Datadog attempts to discover new connectors every time you view this integration tile.
Select the resources you want to add.
Click Add Resources.
Navigate to Data Streams Monitoring to visualize the connectors and track connector status and throughput.
Further reading
Additional helpful documentation, links, and articles: