This product is not supported for your selected
Datadog site. (
).
This guide is for large-scale production-level deployments.
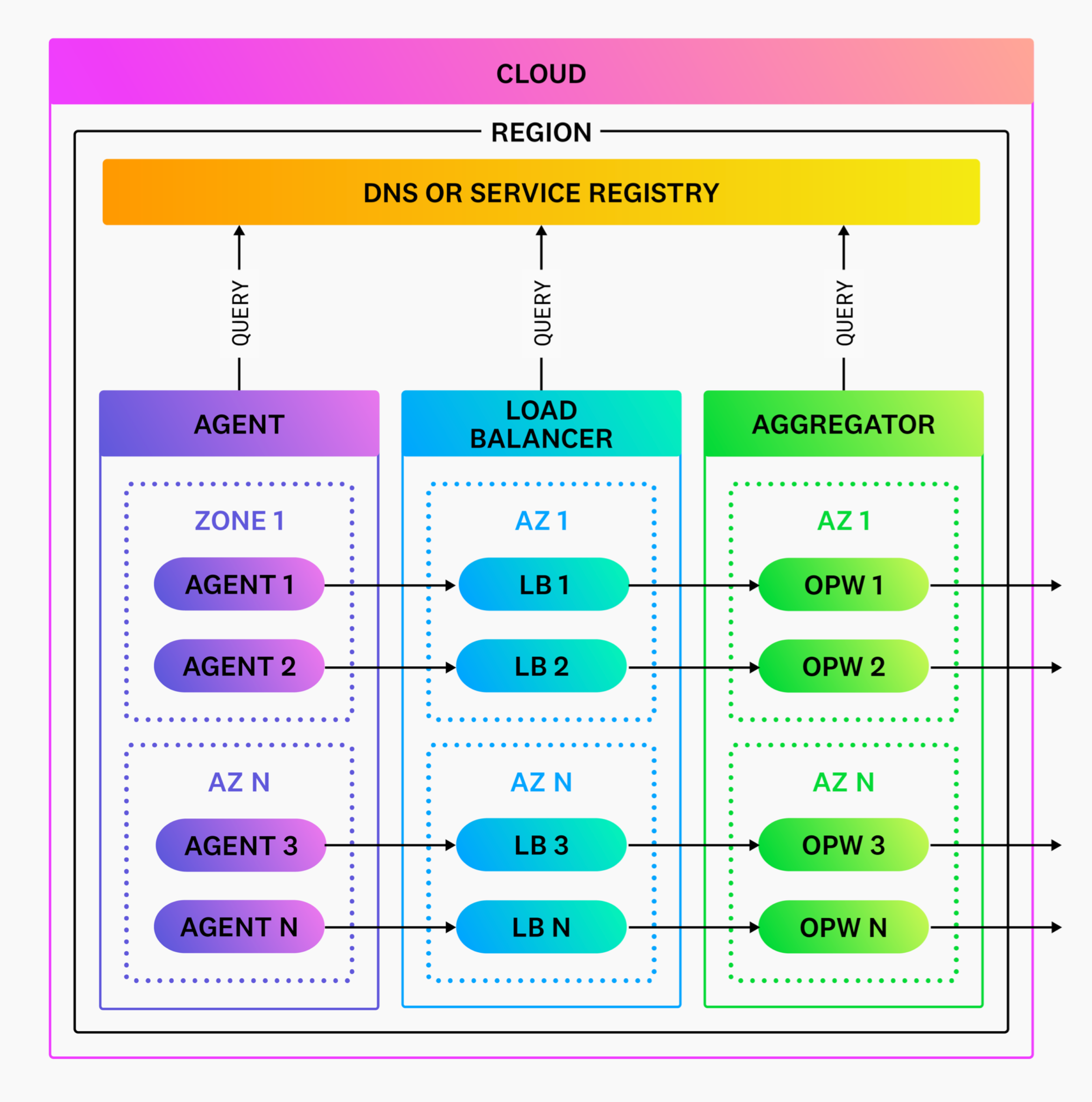
Network topology
Network boundaries
Most users have complex production environments with many network boundaries, including multiple clouds, regions, VPCs, and clusters. It can get complicated when determining where Observability Pipelines Worker fits within those boundaries. Therefore, Datadog recommends starting with one Observability Pipelines Worker aggregator per region, even if you have multiple accounts, VPCs, and clusters. This boundary is the broadest networking granularity that avoids sending data over the public internet. If you have multiple clusters, deploy Observability Pipelines Worker into your utility or tools cluster, or pick a cluster that is most appropriate for shared services.
As your Observability Pipelines Worker usage increases, it can then become clear where multiple Observability Pipelines Worker deployments fit in.
See Advanced configurations for more information on multiple deployments.
DNS and service discovery
Your organization may have adopted some form of service discovery, even if it’s facilitated through basic DNS. Discovery of your Observability Pipelines Worker aggregators and services should resolve through your service discovery mechanism.
Service discovery allows you to configure your agents with named hostnames (not static IP addresses), facilitating routing and load balancing of your traffic. This is how your agents discover your load balancers and how your load balancers discover your Observability Pipelines Worker aggregators.
Observability Pipelines Worker itself does not resolve DNS queries and delegates this to a system-level resolver (for example, Linux resolving).
Network traffic
Proxies
Observability Pipelines Worker offers a global proxy option to route all outgoing HTTP traffic through a proxy. Whether you use a proxy depends on your organization’s security and networking preferences.
Ports
The Observability Pipelines Worker requires all ports to be explicitly configured for easy discovery by network administrators. Therefore, by viewing Observability Pipelines Worker’s configuration file you get a complete inventory of every port exposed. The Observability Pipelines Worker aggregator ships with a default configuration that exposes the following ports:
| Port | Source | Protocol | Direction | Description |
|---|
| 8282 | Datadog Agent | HTTP | Incoming | Accepts data from the fluent source. |
| 123 | Files | Syslog | Incoming | Accepts data from the Syslog source. |
Be sure to review your Observability Pipelines Worker configuration for the exact ports exposed, as your administrator may have changed them.
Protocols
The Observability Pipelines Worker is designed to receive and send data over a variety of protocols. Datadog recommends using the protocol best supported for your integration. Choose HTTP-based protocols for their application-level delivery acknowledgments and ubiquitous support across platforms when possible. Otherwise, choose TCP-based protocols. UDP is not recommended, as there is risk of losing data.
Worker-to-worker communication
Use the Observability Pipelines Worker source and sink to send data between Observability Pipelines Worker instances (for example, with the unified architecture). These sources use the GRPC protocol for efficient lossless communication.
Agent communication
The Observability Pipelines Worker provides specific sources for many agents. For example, the datadog_agent source handles receiving all data types from the Datadog Agent in a lossless structured format.
Compression
Compression can impose a 50% decrease in throughput based on Datadog benchmarks. Use compression with caution and monitor performance after enabling.
Compression of network traffic should only be used for cost-sensitive egress scenarios due to its impact on performance (for example, sending data over the public internet). Therefore, compression is not recommended for internal network traffic.