Best Practices for Scaling Observability Pipelines
This product is not supported for your selected
Datadog site. (
).
Observability Pipelines は、US1-FED Datadog サイトでは利用できません。
このガイドは、大規模な本番環境レベルのデプロイメント向けです。
概要
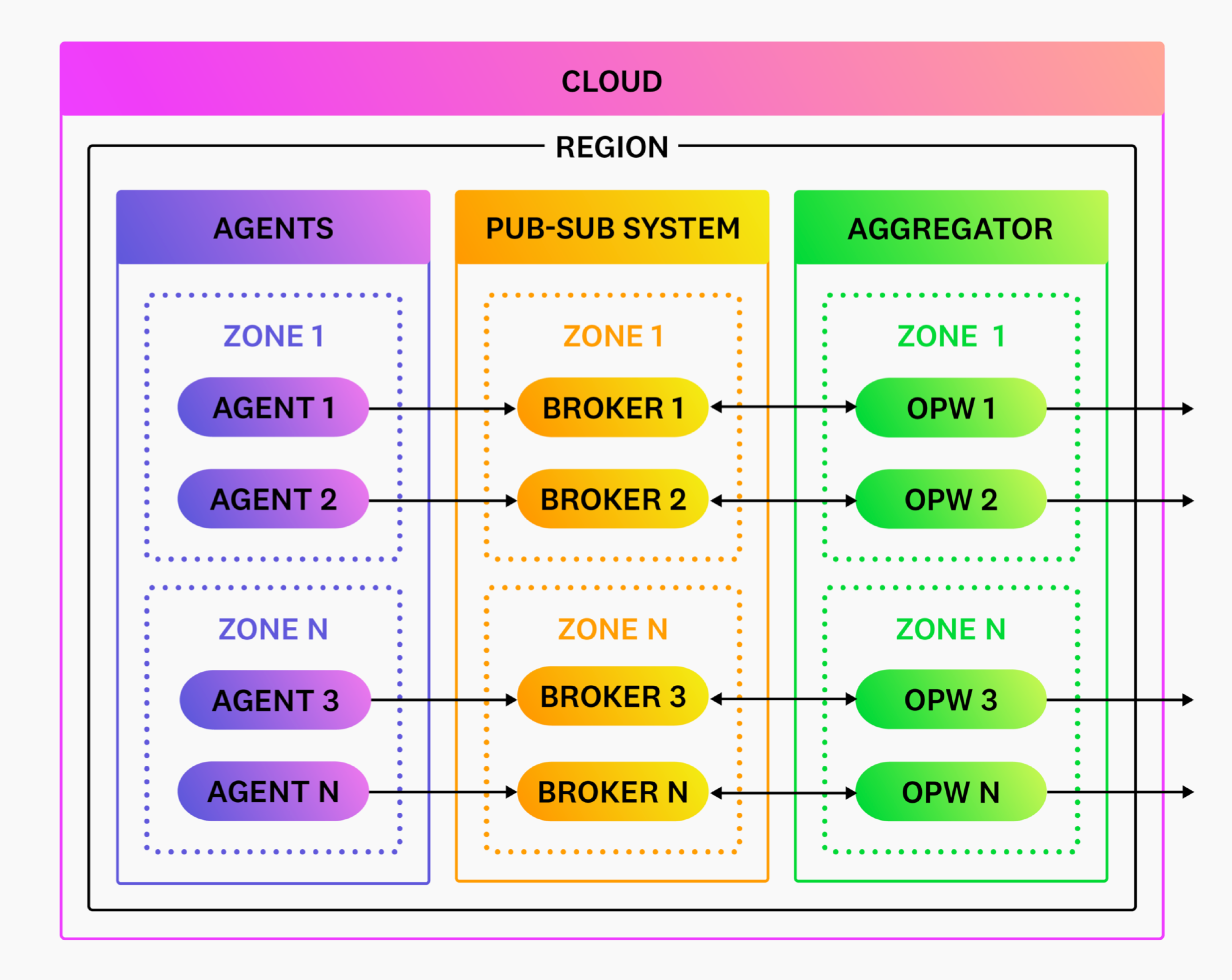
Observability Pipelines Worker を他のサービスのようにインフラストラクチャーにデプロイし、データをインターセプトして操作し、宛先に転送することができます。Observability Pipelines Worker インスタンスはそれぞれ独立して動作するため、シンプルなロードバランサーでアーキテクチャを拡張することができます。
このガイドでは、新規の Observability Pipelines Worker ユーザーのために、推奨されるアグリゲーターアーキテクチャを説明します。具体的には、以下のトピックです。
- インスタンスの最適化により、Observability Pipelines Worker のアグリゲーターを水平方向にスケールさせることができるようになります。
- キャパシティプランニングとスケーリングのために、Observability Pipelines Worker のリソース容量を見積もるための出発点。
インスタンスの最適化
インスタンスサイジング
少なくとも 8 つの vCPU と 16 GiB のメモリを持つコンピュート最適化されたインスタンスを使用します。これらは、Observability Pipelines Worker アグリゲーターを水平方向に拡張するための理想的なユニットです。Observability Pipelines Worker は、より大きなインスタンスを選択すると、垂直方向にスケールし、自動的に追加リソースを利用することができます。可用性を高めるために、データボリュームに対して少なくとも 2 つのObservability Pipelines Worker インスタンスを使用できるサイズを選択します。
| クラウドプロバイダー | 推奨事項 |
|---|
| AWS | c6i.2xlarge (推奨) または c6g.2xlarge |
| Azure | f8 |
| Google Cloud | c2 (8 vCPU、16 GiB メモリ) |
| プライベート | 8 vCPU、16 GiB メモリ |
CPU サイジング
観測可能性パイプラインワーカーワークロードの多くは、CPU に制約があり、最新の CPU の恩恵を受けることができます。
| クラウドプロバイダー | 推奨事項 |
|---|
| AWS | 最新世代の Intel Xeon、8 vCPU (推奨)、最低 4 vCPU |
| Azure | 最新世代の Intel Xeon、8 vCPU (推奨)、最低 4 vCPU |
| Google Cloud | 最新世代の Intel Xeon、8 vCPU (推奨)、最低 4 vCPU |
| プライベート | 最新世代の Intel Xeon、8 vCPU (推奨)、最低 4 vCPU |
CPU アーキテクチャ
観測可能性パイプラインワーカーは、最新の CPU アーキテクチャで動作します。X86_64 アーキテクチャは、観測可能性パイプラインワーカーに最も適したパフォーマンスを提供します。
メモリサイジング
Observability Pipelines Worker のアフィン型システムにより、Observability Pipelines Worker のワークロードでは、メモリが制約されることはほとんどありません。そのため、Datadog は最小で vCPU あたり 2 GiB 以上のメモリを推奨しています。メモリ内バッファリングとバッチ処理により、宛先の数に応じてメモリ使用量が増加します。宛先の数が多い場合は、メモリの増設を検討してください。
ディスクサイジング
Observability Pipelines Worker をインストールするには、500MB のディスク容量が必要です。
キャパシティプランニングとスケーリング
試算の単位
以下の単位は、リソースの容量を見積もるための出発点ですが、ワークロードによって異なる場合があります。
| 単位 | サイズ | 観測可能性パイプラインワーカースループット* |
|---|
| 非構造化ログイベント | ~512 バイト | ~10 MiB/s/vCPU |
| 構造化ログイベント | ~1.5 KB | ~25 MiB/s/vCPU |
*この数値は試算のための保守的なものです。1 vCPU = ARM 物理 CPU × 1、Intel 物理 CPU × 0.5。
スケーリング
水平スケーリング
水平スケーリングとは、複数の観測可能性パイプラインワーカーインスタンスにトラフィックを分散させることです。観測可能性パイプラインワーカーはシェアードナッシングのアーキテクチャを採用しており、リーダーノードやスケーリングを複雑にするような調整を必要としません。
プッシュベースのソースの場合、観測可能性パイプラインワーカーインスタンスをネットワークロードバランサーで前面化し、必要に応じてスケールアップ/ダウンしてください。
プルベースのソースの場合、ロードバランサーは必要ありません。観測可能性パイプラインワーカーをデプロイし、必要に応じてスケールアップ/ダウンしてください。観測可能性パイプラインワーカーがデータの読み取りを要求したときに、パブリッシュサブスクリプションシステムがデータへの排他的なアクセスを調整します。
ロードバランシング
ロードバランサーは、Agent のようなプッシュベースのソースにのみ必要です。Kafka のようなプルベースのソースのみを使用する場合は、ロードバランサーは必要ありません。
クライアント側のロードバランシング
クライアント側のロードバランシングは推奨されません。クライアント側のロードバランシングとは、複数の観測可能性パイプラインワーカーインスタンスにまたがるトラフィックのロードバランシングをクライアントが行うことを指します。このアプローチはよりシンプルに聞こえますが、以下のため信頼性が低く、より複雑になる可能性があります。
- 適切なフェイルオーバーを伴うロードバランシングは複雑です。この分野の問題は、データの損失やサービスを停止させるインシデントにつながる可能性があるため、デリケートな問題です。複数のタイプのクライアントを取り扱っている場合は、さらに悪化します。
- Observability Pipelines Worker アグリゲーターのポイントは、Agent から責任を取り除くことであり、ロードバランシングを担うことはその一助となります。
ロードバランサーの種類
Datadog では、レイヤー 4 (L4) ロードバランサー (ネットワークロードバランサー) を推奨しています。これは、Observability Pipelines Worker のプロトコル (TCP、UDP、HTTP) をサポートしているためです。HTTP トラフィック (レイヤー7) のみを送信している場合でも、Datadog はそのパフォーマンスとシンプルさのために L4 ロードバランサーを推奨しています。
| クラウドプロバイダー | 推奨事項 |
|---|
| AWS | AWS ネットワークロードバランサー (NLB) |
| Azure | 内部 Azure ロードバランサー |
| Google Cloud | 内部 TCP/UDP ネットワークロードバランサー |
| プライベート | HAProxy、NGINX、またはレイヤー 4 をサポートするその他のロードバランサー |
ロードバランサーの構成
クライアントとロードバランサーを構成する場合、Datadog は以下の一般的な設定を推奨しています。
- シンプルなラウンドロビンのロードバランシング戦略を使用します。
- ゾーン間のトラフィックが非常に不均衡である場合を除き、クロスゾーンのロードバランシングを有効にしません。
- 観測可能性パイプラインワーカーのヘルス API エンドポイントを使用して、ターゲットのヘルスを確認するようにロードバランサーを構成します。
- Observability Pipelines Worker インスタンスがスケールする際に、自動的に登録または登録解除されるようにします。
- クライアントとロードバランサーの両方で、1 分以内のアイドルタイムアウトでキープアライブを有効にします。
- サポートされている場合は、Agent で接続の同時実行とプーリングを有効にします。サポートされていない場合は、エッジに観測可能性パイプラインワーカーをデプロイする統合アーキテクチャを検討してください。接続プーリングは、大量のデータを複数の接続に分散させ、トラフィックのバランスを取ることを可能にします。
ロードバランサーのホットスポット
ロードバランシングホットスポットは、1 つまたは複数の観測可能性パイプラインワーカーインスタンスが不均衡なトラフィックを受け取る場合に発生します。ホットスポットは通常、2 つの理由のうちの 1 つによって発生します。
- 1 つの接続でかなりの量のトラフィックが送信されている。
- あるアベイラビリティゾーンのトラフィックが、他のゾーンよりはるかに多い。
このような場合、以下のようなそれぞれの緩和策をとることをお勧めします。
- 大きな接続を複数の接続に分割します。ほとんどのクライアントでは、複数の接続にデータを分散させる接続の同時実行とプーリングが可能です。この戦術により、ロードバランサーは複数の観測可能性パイプラインワーカーインスタンスに接続を分散させることができます。クライアントがこれをサポートしていない場合は、観測可能性パイプラインワーカーをエッジに追加でデプロイできる統一アーキテクチャを検討してください。
- ロードバランサーでクロスゾーンのロードバランシングを有効にします。クロスゾーンバランシングは、すべての観測可能性パイプラインワーカーインスタンスですべてのアベイラビリティゾーンのトラフィックをバランスさせます。
垂直スケーリング
観測可能性パイプライン ワーカーの同時実行モデルは、すべての vCPU を活用するために自動的にスケーリングされます。同時実行の設定や構成の変更は必要ありません。Datadog では、垂直スケーリングを行う場合、インスタンスのサイズを総ボリュームの 50% 以下に抑え、高可用性のために最低 2 つの観測可能性パイプラインワーカーインスタンスをデプロイすることを推奨しています。
オートスケーリング
オートスケーリングは、平均的な CPU 使用率に基づいて行う必要があります。大半のワークロードでは、Observability Pipelines Worker は CPU の制約を受けています。CPU 使用率は、誤検出が発生しないため、オートスケーリングの最も強力なシグナルとなります。Datadog は、以下の設定を使用し、必要に応じて調整することを推奨します。
- 使用率 85% を目標とした平均的な CPU。
- スケールアップとスケールダウンのための 5 分間の安定時間。