アプリケーションの可用性をネットワークインサイトで検知する
概要
アプリケーション同士が依存し合っている場合、接続が不安定だったりサービス呼び出しが遅延すると、アプリケーション層でエラーやレイテンシーが発生する可能性があります。Datadog の Cloud Network Monitoring (CNM) は、レイテンシーやパケットロス、スループットなどのネットワークメトリクスをアプリケーションやサービス全体で収集・分析・相関させることで、アプリケーションやネットワークの問題を解決するための具体的なインサイトを提供します。
サービスの発見と接続状況
CNM はエンティティ間のトラフィックを追跡し、どのリソースが通信しているかを特定して、そのヘルスステータスをレポートするように設計されています。
エンティティ間の基本的なトラフィックフローを確認するには、次の手順を行います。
Network Analytics ページで、View clients as と View servers as のドロップダウンを service タグに設定し、サービス間フローを確認します。ここでは、ソース IP がポートを介して宛先 IP と通信するという基本的な通信単位を観察できます。
各行には 5 分間分の接続が集約されています。ネットワークに詳しければ IP を特定のアドレスやホストとして認識できる場合もありますが、ネットワークが大規模で複雑になるほどこれらを把握するのは難しくなります。そこで Datadog 上の service や availability zone、pod といったタグと IP を関連づける形で集約すると、より有益な分析が可能になります。
検索結果をフィルタで絞り込むこともできます。例えば、ホストおよびアベイラビリティゾーン単位で orders-sqlserver* の Pod が行うすべてのネットワークトラフィックを確認するには、client_pod_name:orders-sqlserver* フィルターを使用します。
この最初のステップにより、VM やコンテナ、サービス、クラウドリージョン、データセンターなど、あらゆるエンドポイント間の接続を把握し、複雑なネットワークでもインサイトを得ることが可能になります。
サービス間の依存関係の追跡
CNM はサービス間の依存関係を追跡し、システムのパフォーマンスを確保するために重要な接続を確認してトラフィック量を可視化し、すべての重要な依存関係が正常に稼働しているかを把握します。
例えば、サービスのレイテンシーが高まる原因として、宛先エンドポイントへのトラフィックが過剰に集中し、受信リクエストを処理しきれなくなっている可能性があります。
サービスレイテンシーの原因を分析するには、以下の手順を行います。
Network Analytics ページでトラフィックを service 単位に集約し、アラートやサービス遅延が発生している可能性のあるクラウドリージョンをフィルタします。このビューでは、そのリージョン内におけるすべてのサービス間の依存関係を表示できます。
再送回数 (retransmits) やレイテンシーに基づいて依存関係テーブルを並び替えることで、最も深刻なパフォーマンス低下が起きている接続を特定できます。例えば、TCP の確立済み接続数が異常に多いのと同時に再送やレイテンシーの急増が見られる場合は、送信元が宛先のインフラストラクチャーに対して大量のリクエストを送り込み過ぎている可能性があります。
このページでトラフィックパスの 1 つをクリックするとサイドパネルが開きます。サイドパネルには、ネットワーク依存関係をさらにデバッグするための詳細なテレメトリが表示されます。
サイドパネル上で Flows タブを確認し、通信プロトコルが TCP か UDP かを見極め、RTT (往復時間) やジッター、送受信パケット数などのメトリクスを確認します。再送回数が高い場合は、こうした情報が原因特定の手がかりになります。
ネットワークトラフィックのインサイト
Datadog CNM は、関連する分散トレースやログ、インフラストラクチャーデータを単一のビューに集約し、アプリケーションから発生したリクエストへと遡って問題を特定・追跡できるようにします。
以下の例では、Network Analytics の Traces タブを確認し、送信元と宛先のエンドポイント間の分散トレースを表示します。これにより、アプリケーションレベルでどこにエラーが発生しているかを特定しやすくなります。
問題がアプリケーションによるものか、それともネットワークによるものかを特定するには、以下の手順が利用できます。
Infrastructure > Cloud Network > Analytics に移動します。
Summary グラフで、大きな通信量と高い RTT 時間が見られる通信ラインをクリックします。
Isolate this series をクリックします。すると、この通信ラインに限定したネットワークトラフィックのみを観察できるページが開きます。
このページで、いずれかのネットワーク通信パスをクリックし、次に Flows タブをクリックして RTT 時間を確認します。
このページでは、CNM がネットワークメトリクスである往復時間 (RTT) とアプリケーションのリクエスト遅延を関連づけることで、問題がネットワークかアプリケーションかを特定しやすくします。この例では、RTT 時間がやや高いものの徐々に下がってきており、より詳細な調査が必要な状態です。
同じページで Traces タブをクリックし、Duration 列を確認します。
ネットワークのレイテンシー (RTT) は高いがアプリケーションのリクエスト遅延 (Duration) が正常な場合は、問題はネットワークに起因している可能性が高く、アプリケーションコードを調査する必要はありません。
逆に、ネットワークレイテンシー (RTT) が安定していてアプリケーションの遅延 (Duration) が高い場合 は、問題はアプリに起因している可能性があるため、Traces タブのサービスパスをクリックしてコードレベルのトレースを確認し、根本原因を突き止められます。この操作により、該当サービスに関連する APM のフレームグラフに移動します。
ネットワークマップ
Datadog の Network Map はネットワークトポロジーを可視化し、パーティションや依存関係、ボトルネックを発見するのに役立ちます。ネットワークデータを方向性のあるマップに集約することで、問題を抱えている領域を切り分けやすくします。また、環境内のどんなタグ付きオブジェクト (services や pods、cloud regions など) 間のネットワークトラフィックでも可視化できます。
大規模なコンテナ環境など複雑なネットワークでは、Datadog の Network Map によって、コンテナや Pod、デプロイ間を行き交うリアルタイムのトラフィックフローを矢印 (エッジ) で表し、コンテナの変更があってもトラブルシューティングを容易にします。これにより非効率や誤構成を発見しやすくなります。たとえば、同じ Kubernetes クラスター内の Pod が直接通信ではなく ingress コントローラーを経由している場合、不要なレイテンシーを発生させる誤構成が考えられます。
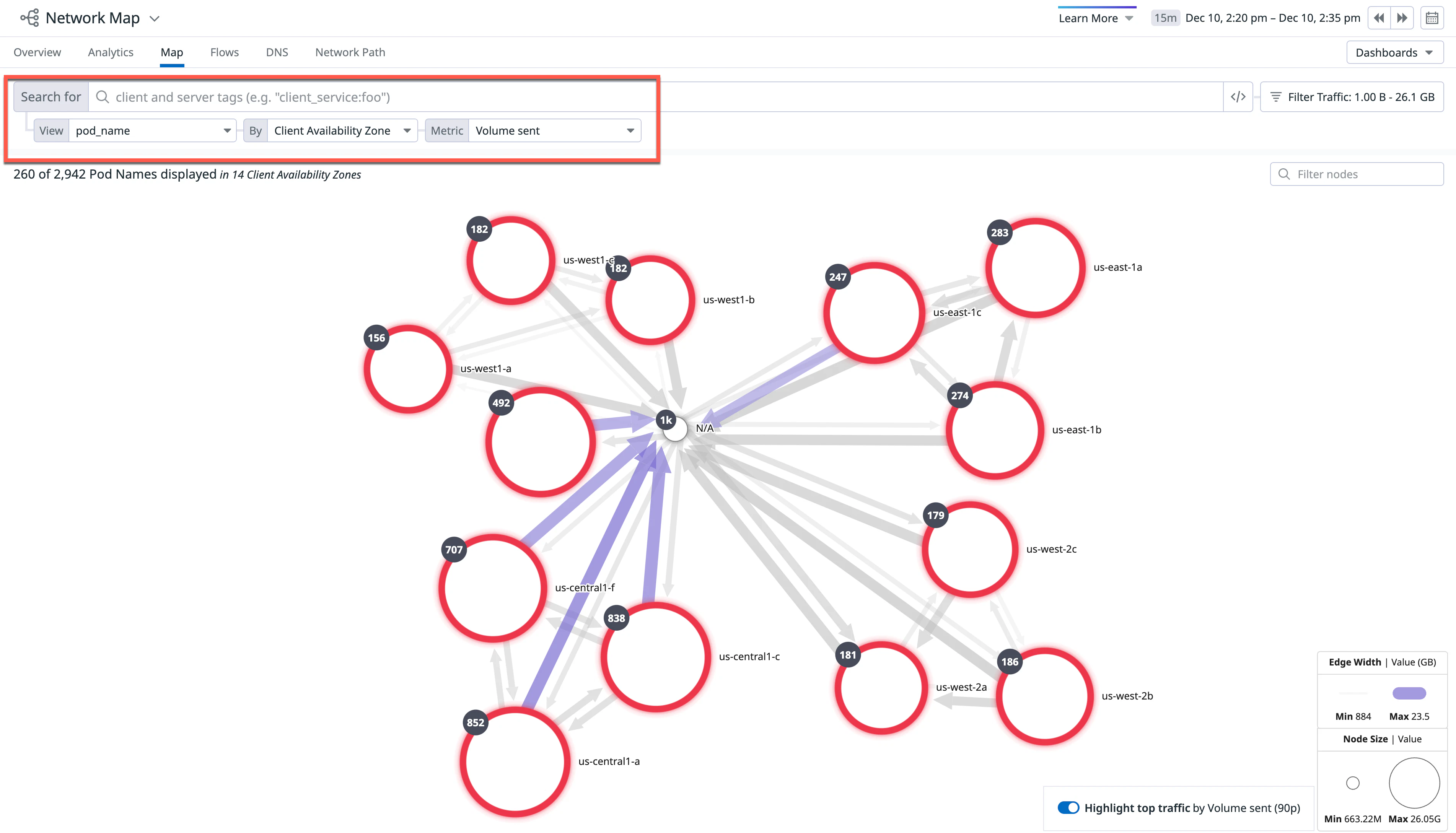
Kubernetes Pod とその基盤サービス間の通信に問題があるかどうかを特定するには、以下の手順を実行します。
Network Map で、View ドロップダウンを pod_name に設定し、By ドロップダウンを「Client Availability Zone」に、Metric ドロップダウンを「Volume Sent」に設定します (これはエッジに表したいメトリクスです)。
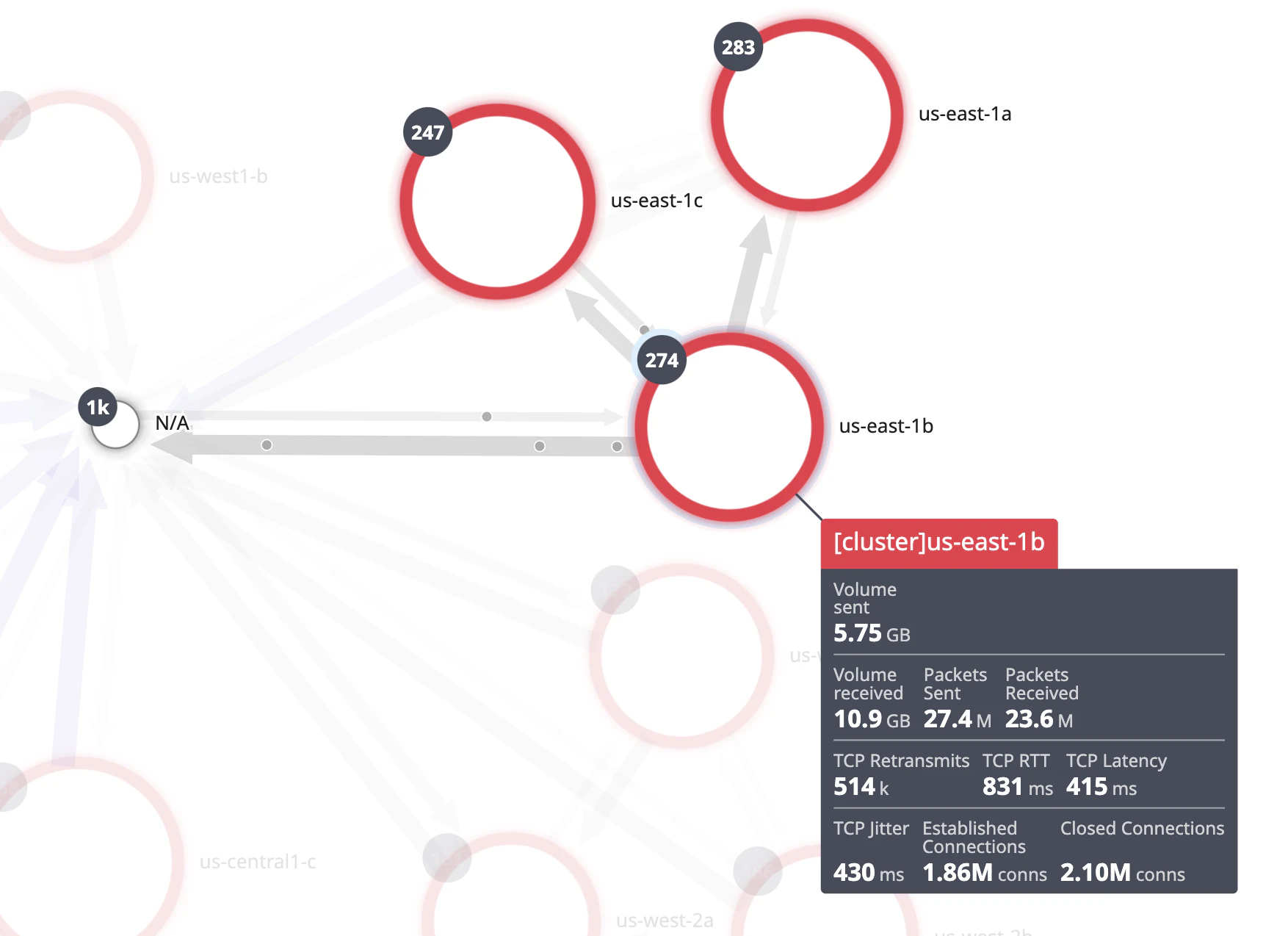
ノードにカーソルを合わせると (あるいはクリックすると)、クラスターやアベイラビリティゾーン間のトラフィックフローを矢印 (エッジ) で可視化できます。この例では、すべての Pod 間にエッジが存在することがわかります。もしエッジが表示されない場合は、誤構成がある可能性があります。
エッジの太さは、ドロップダウンで選択したメトリクスに対応しています。この例では、より太いエッジが volume sent というメトリクスに紐づいています。また、点線のエッジをクリックすることで直接 Network Analytics ページに戻り、ネットワーク接続をさらに調査することもできます。
サービスメッシュ
Istio のようなサービスメッシュはマイクロサービス間の通信を管理するのに役立ちますが、抽象化のレイヤーが増えるため、監視が複雑化します。Datadog CNM は Istio が管理するネットワーク上のトラフィックフローを可視化し、Istio 環境を包括的に監視することで、この複雑さを軽減します。Datadog は帯域幅やリクエストパフォーマンスなどの主要メトリクスを監視し、コントロールプレーンのヘルスをログとして記録し、メッシュ全体でのアプリケーションリクエストをトレースします。
さらに Datadog は Envoy のモニタリングもサポートしており、Istio のデータを Envoy プロキシメッシュと相関させることができます。トラフィックは Envoy サイドカーを経由してルーティングされるため、Datadog はそれらをコンテナとしてタグ付けし、Pod 間のレイテンシー問題がサービスメッシュに起因するものかどうかを特定できるようにします。
参考資料