概要
異常検知は、傾向や、季節的な曜日や時間帯のパターンを考慮しながらメトリクスの挙動が過去のものとは異なる期間を認識するアルゴリズム機能です。これは、しきい値ベースのアラート設定では監視することが困難な強い傾向や反復パターンを持つメトリクスに適しています。
たとえば、 ある平日のウェブトラフィック量が夜間帯は通常であるにもかかわらず、午後は異常に低い時間帯を見つけることができます。また、確実にアクセス数が伸びているサイトへのログイン数を測定するメトリクスを考慮できます。 なぜなら、ログイン数が日々増加すると、しきい値が古くなってしまいますが、ログインシステムの潜在的な問題を示唆する予想外の激減が見られた場合、異常検知が警告してくれるからです。
モニターの作成
Datadog で異常検知モニターを作成するには、メインナビゲーション画面でMonitors –> New Monitor –> Anomaly の順に移動します。
メトリクスを定義する
Datadog にレポートが送信されるメトリクスはすべて、モニターに使用できます。詳細については、メトリクスモニターページをご確認ください。
注: anomalies 関数は過去のデータを使用して今後の予想を立てるため、新しいメトリクスで使用するとあまり正確な結果が得られないことがあります。
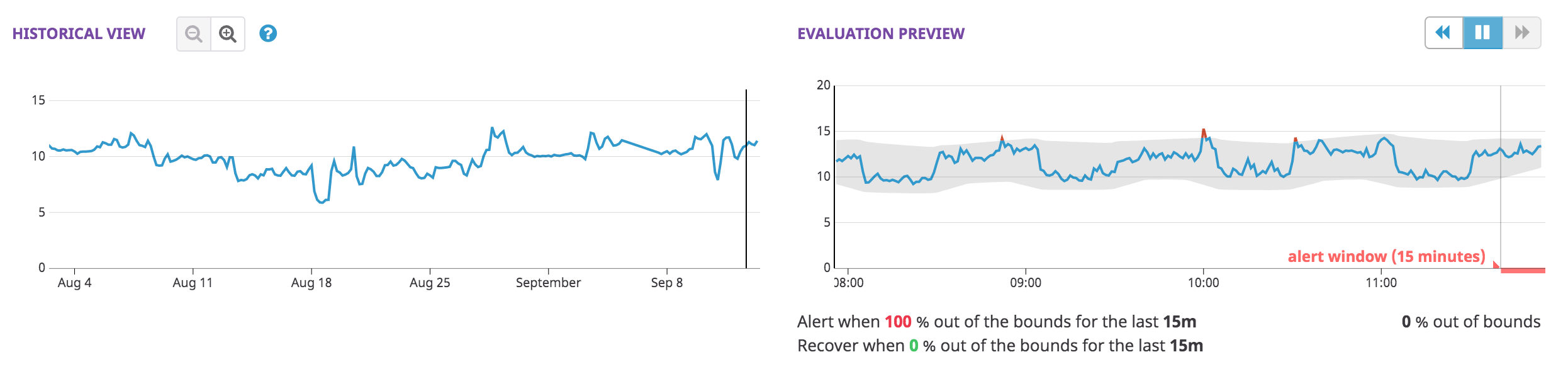
メトリクスを定義すると、異常検知モニターにより作成された 2 種のグラフがエディターに表示されます。
- Historical View では、監視クエリをさまざまな時間単位で観察することができるため、 データが異常または正常とみなされる理由をより深く理解できます。
- Evaluation Preview は、アラート設定よりもウィンドウが長く、範囲を計算する際に異常検知アルゴリズムが考慮すべき事項に関して洞察を提供します。
アラートの条件を設定する
直近15 minutes、1 hour などの値が範囲を above or below、above、below 場合、または custom に設定した 15 分〜24 時間の値で、アラートをトリガーします。
値が少なくとも 15 minutes、1 hour などの範囲内にある場合は回復するか、custom に 15 分〜24 時間の値を設定します。
- 異常検知
- デフォルト (
above or below) では、メトリクスが灰色の異常検知帯の外にある場合、異常とみなされます。帯の above または below にある場合のみを異常とみなすよう任意で指定することもできます。 - トリガーウィンドウ
- メトリクスの異常が検知されアラートを発するまでに必要な時間。注意: アラート設定ウィンドウがあまりに短いと、疑似ノイズにより不正アラームが発せられることがあります。
- リカバリーウィンドウ
- メトリクスが異常とみなされなくなり、アラートが回復するまでに必要な時間。Recovery Window は、Trigger Window と同じ値に設定することをお勧めします。
注: Recovery Window の許容値の範囲は、モニターが回復とアラート条件を同時に満たすことができないように、Trigger Window と Alert Threshold に依存します。
例:
Threshold: 50%Trigger window: 4h
リカバリーウィンドウの許容値の範囲は、121 分 (4h*(1-0.5) +1 min = 121 minutes) から 4 時間の間です。リカバリーウィンドウを 121 分未満に設定すると、4 時間の時間枠で 50% の異常ポイントが発生し、最後の 120 分では異常ポイントが発生しない可能性があります。
他の例:
Threshold: 80%Trigger window: 4h
リカバリーウィンドウの許容値の範囲は 49 分 (4h*(1-0.8) +1 min = 49 minutes) から 4 時間の間です。
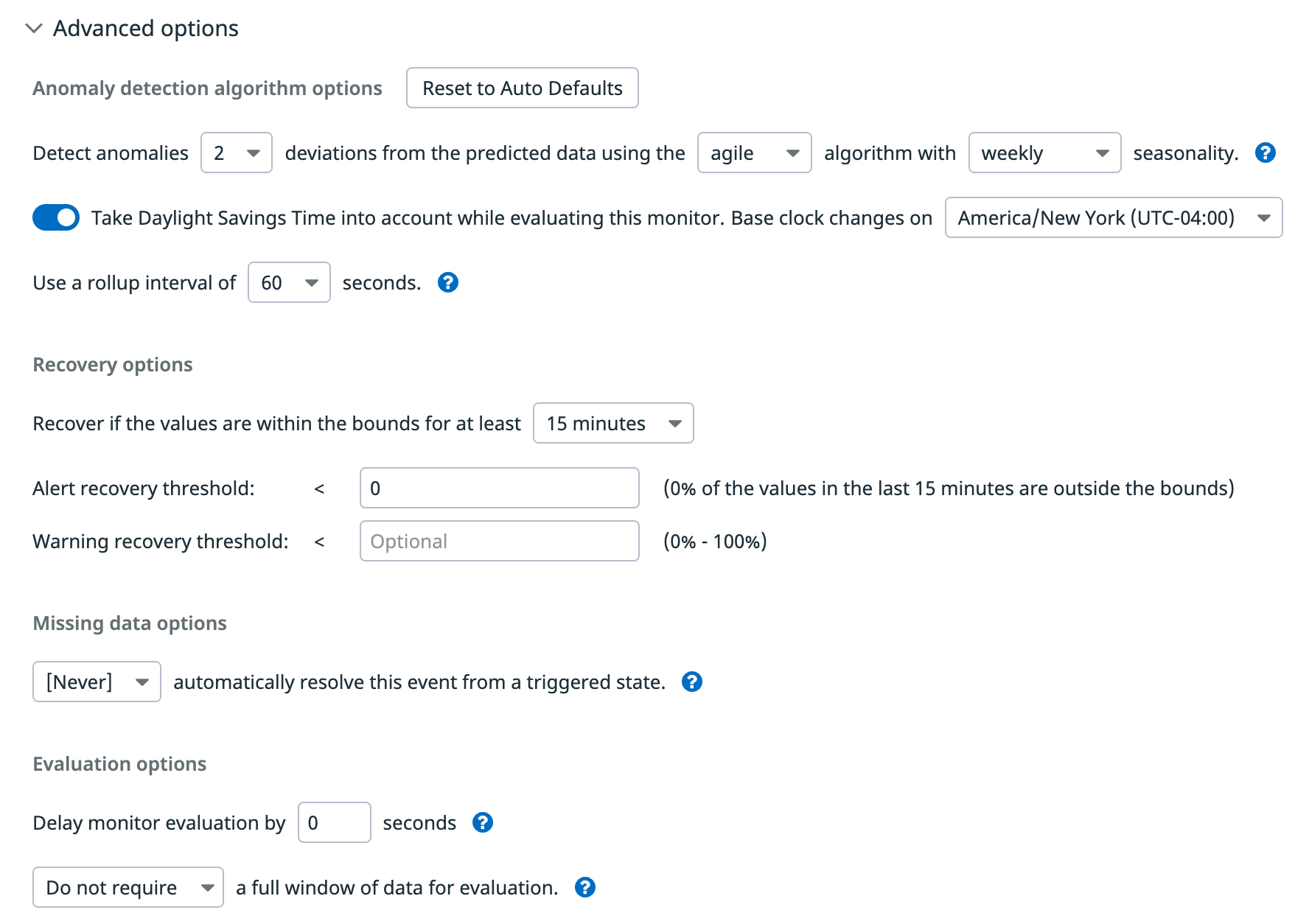
高度なオプション
Datadog は、選択したメトリクスを自動的に分析して、複数のパラメーターを設定しますが、Advanced Options に、編集可能なオプションがあります。
- 偏差
- 灰色の帯の幅。異常検知関数で使用される範囲のパラメータに相当。
- アルゴリズム
- 異常検知アルゴリズム (
basic、agile、robust)。 - 季節性
- メトリクスを分析する
agile または robust アルゴリズムの季節性 (hourly、daily、weekly) サイクル。 - 夏時間
agile または robust の異常検知で季節性に weekly または daily を使用する場合に利用可能。詳細については、異常検知とタイムゾーンを参照。- rollup
- rollup の間隔。
- しきい値
- アラート、警告、リカバリを設定するために異常として判断する基準となるパーセンテージ。
季節性
- Hourly
- このアルゴリズムは、毎時の特定の分が過去の同じ分と同様に挙動すると想定します。たとえば、5:15 の挙動が 4:15 や 3:15 と同じだと想定します。
- Daily
- このアルゴリズムは、今日の特定の時間が過去の同じ時間と同様に挙動すると想定します。たとえば、今日の午後 5 時の挙動が前日の午後 5 時と同じだと想定します。
- Weekly
- このアルゴリズムは、特定の曜日が過去の同じ曜日と同様に挙動すると想定します。たとえば、今週の火曜の挙動が過去の火曜と同じだと想定します。
異常検出アルゴリズムに必要なデータ履歴: 機械学習アルゴリズムは、ベースラインを計算するために、選択された季節性時間の少なくとも 3 倍の履歴データ時間を必要とします。
例:
- _週ごと_の季節性には少なくとも 3 週間のデータが必要
- _日ごと_の季節性には少なくとも 3 日間のデータが必要
- _時間ごと_の季節性には少なくとも 3 時間のデータが必要
季節性アルゴリズムはすべて、メトリクスの挙動の正常範囲を予測する際に、最大で 6 週間分の履歴データを使用します。過去データを大量に使用することで、通常とは異なる挙動が最近発生していた場合、アルゴリズムはこれを重視しません。
異常検知アルゴリズム
- Basic
- メトリクスに反復する季節性パターンがない場合に使用します。Basic は遅延の繰り返しの分位数を計算して予測値の範囲を決定します。データをほとんど使用せず、状況の変化にすばやく対応しますが、季節的な挙動や長期的な傾向は認識できません。
- Agile
- メトリクスが季節的なものでシフトが見込まれる場合に使用します。アルゴリズムはメトリクスのレベルシフトにすばやく対応します。SARIMA アルゴリズムの安定版。直近のデータを予測に組み込むことで、レベルシフトに合わせてすばやく更新できますが、最近の長期的な異常検知に対する安定性は低下します。
- Robust
- 安定性が期待できる季節性メトリクスの緩やかなレベルシフトを異常値と見なした場合に使用されます。季節的傾向分解アルゴリズムの 1 つ。安定性が高く、異常が長期的に続いても予測は一定していますが、意図的なレベルシフトへの対応にはやや時間がかかります (コード変更によってメトリクスのレベルがシフトした場合など)。
例
下記のグラフでは、これら 3 つのアルゴリズムがいつどのように異なる挙動を示すか表しています。
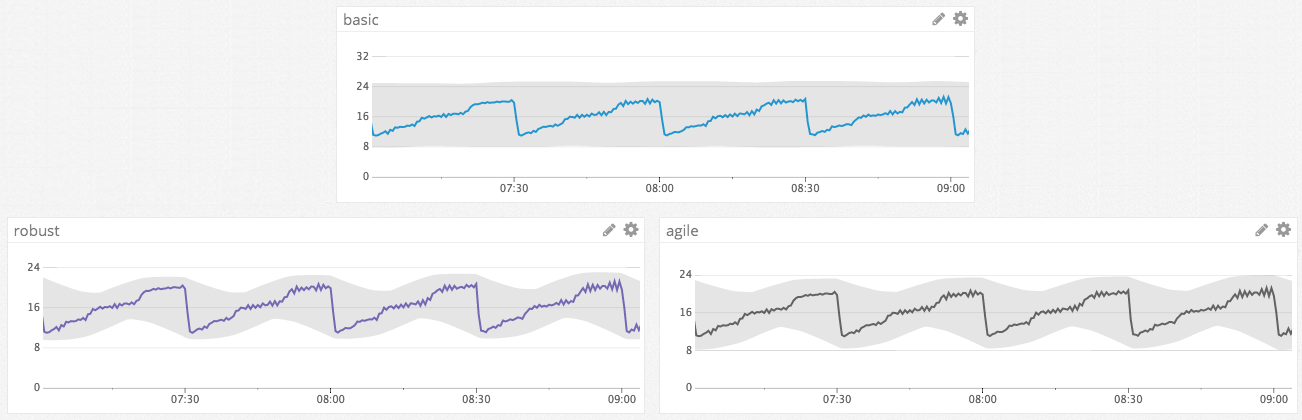
1 時間ごとの季節性を考慮した異常検出の比較
この例では、basic は正常値範囲を超えてスパイクする異常値を正しく特定していますが、反復的な季節的パターンが予測値範囲に含まれていません。対照的に、robust と agile は、どちらも季節的パターンを認識し、メトリクスが最小値付近で平坦な線になった場合など、より繊細な異常値を検知しています。トレンドも 1 時間ごとのパターンを示しているので、この場合は 1 時間ごとの季節性が最も効果的です。
1 週間ごとの季節性を考慮した異常検出の比較
この例では、メトリクスが突然のレベルシフトを示しています。Agile は robust よりも早くレベルシフトに対応しています。さらに、レベルシフト以降、robust の範囲はより大きな不確実性を反映して広がっていますが、Agile の範囲に変化は見られません。また、メトリクスが週単位の強い季節性パターンを示すシナリオでは、Basic が適していないことは明らかです。
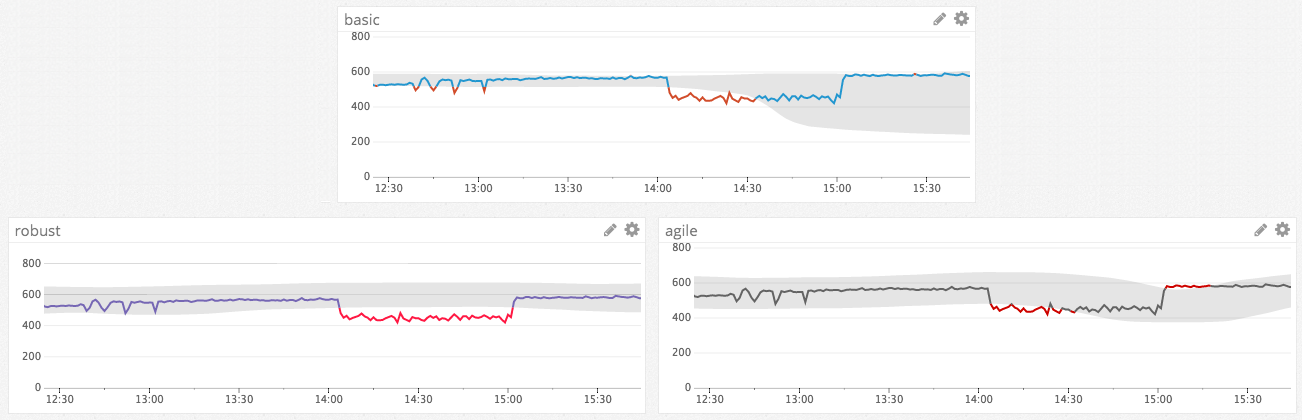
変化に対するアルゴリズム反応の比較
この例では、1 時間にわたる異常値に対してアルゴリズムがどのように反応するかを示しています。 Robust は、急激な変化に対する反応が遅いため、このシナリオでは異常値の境界を調整しません。他のアルゴリズムは、この異常値があたかも新しい正常値であるかのように振る舞い始めます。Agile は、メトリクスが元のレベルに戻ったことも異常値として認識しています。
スケールに対するアルゴリズム反応の比較
これらのアルゴリズムはスケールの扱いも異なります。Basic と robust はスケールの影響を受けませんが、agile は影響を受けます。下の左側のグラフでは、agile と robust がレベルシフトを異常としてマークしています。右側のグラフで、同じメトリクスに 1000 を加算したところ、agile ではレベルシフトを異常とみなすコールアウトは見られなくなりますが、robust では引き続き見られます。
新しいメトリクスによる異常検出の比較
この例では、各アルゴリズムが新しいメトリクスをどのように処理するか示しています。 Robust と agile では、最初の数日は範囲がまったく表示されていません (週単位)。Basic では、メトリクスが最初に表示された直後から範囲が表示されています。
高度なアラート条件
高度なアラートオプション (自動解決、評価遅延など) の詳細な手順については、モニターコンフィギュレーションページを参照してください。メトリクス固有のオプションのフルデータウィンドウについては、メトリクスモニターページを参照してください。
通知
For detailed instructions on the Configure notifications and automations section, see the Notifications page.
API
Customers on an enterprise plan can create anomaly detection monitors using the create-monitor API endpoint. Datadog strongly recommends exporting a monitor’s JSON to build the query for the API. By using the monitor creation page in Datadog, customers benefit from the preview graph and automatic parameter tuning to help avoid a poorly configured monitor.
Note: Anomaly detection monitors are only available to customers on an enterprise plan. Customers on a pro plan interested in anomaly detection monitors should reach out to their customer success representative or email the Datadog billing team.
異常モニターは、他のモニターと同じ API を使用して管理されます。これらのフィールドは、異常モニターに固有です。
query
リクエストの本文の query プロパティには、次の形式のクエリ文字列を含める必要があります。
avg(<query_window>):anomalies(<metric_query>, '<algorithm>', <deviations>, direction='<direction>', alert_window='<alert_window>', interval=<interval>, count_default_zero='<count_default_zero>' [, seasonality='<seasonality>']) >= <threshold>
query_window- A timeframe like
last_4h や last_7d などのタイムフレーム。通知のグラフに表示される時間ウィンドウ。少なくとも alert_window と同じ大きさでなければならず、alert_window の約 5 倍にすることをお勧めします。 metric_query- 標準の Datadog メトリクスクエリ (例:
sum:trace.flask.request.hits{service:web-app}.as_count())。 algorithmbasic、agile、またはrobust。deviations- 正の数。異常検知の感度を制御します。
direction- アラートをトリガーする異常の方向性。
above、below、またはboth。 alert_window- 異常をチェックするタイムフレーム (例:
last_5m、last_1h)。 interval- ロールアップ間隔の秒数を表す正の整数。これは
alert_window 期間の 5 分の 1 以下でなければなりません。 count_default_zero- ほとんどのモニターでは
true を使用します。値の欠如をゼロとして解釈してはならないカウントメトリクスを送信する場合にのみ、false に設定します。 seasonalityhourly、daily、またはweekly。 basic アルゴリズムを使用するときはこのパラメーターを除外します。threshold- 1 以下の正の数。クリティカルアラートをトリガーするために異常である必要がある
alert_window 内のポイントの割合。
下記の例は、異常検知モニターのクエリを示したものです。Cassandra ノードの平均 CPU が直近 5 分間で通常値を上回る 3 つの標準偏差である場合にアラートを発します。
avg(last_1h):anomalies(avg:system.cpu.system{name:cassandra}, 'basic', 3, direction='above', alert_window='last_5m', interval=20, count_default_zero='true') >= 1
options
thresholds と threshold_windows を除いて、リクエスト本文の options にあるほとんどのプロパティは、他のクエリアラートと同じです。
thresholds- 異常検知モニターは、
critical、critical_recovery、warning、warning_recovery のしきい値をサポートします。しきい値は 0 から 1 までの数値で表され、異常である関連ウィンドウの割合として解釈されます。たとえば、critical のしきい値が 0.9 の場合、trigger_window (以下で説明)のポイントの少なくとも 90% に異常があると、クリティカルアラートがトリガーされます。または、warning_recovery の値が 0 の場合、recovery_window のポイントの 0% が異常である場合にのみ、モニターが警告状態から回復します。 critical threshold は、query で使用される threshold と一致する必要があります。threshold_windows- 異常検知モニターでは、
options に threshold_windows プロパティがあります。threshold_windows には、trigger_window と recovery_window の 2 つのプロパティの両方を含める必要があります。これらのウィンドウは、last_10m や last_1h などのタイムフレーム文字列として表現されます。trigger_window は、query の alert_window と一致する必要があります。trigger_window は、モニターをトリガーする必要があるかを評価する際に異常について分析する時間範囲です。recovery_window は、トリガーされたモニターを回復する必要があるかを評価する際に異常について分析する時間範囲です。
しきい値としきい値ウィンドウの標準コンフィギュレーションは次のようになります。
"options": {
...
"thresholds": {
"critical": 1,
"critical_recovery": 0
},
"threshold_windows": {
"trigger_window": "last_30m",
"recovery_window": "last_30m"
}
}
トラブルシューティング
その他の参考資料