概要
新しい Snowflake インテグレーションは Datadog Agent ベースの Snowflake インテグレーションに取って代わり、追加の機能を提供します。新しい Snowflake インテグレーションを設定した後、Snowflake への API コール量を削減するために、Agent ベースの Snowflake インテグレーションをアンインストールすることをお勧めします。
Snowflake のインフラやデータ取得を、効果的に監視して最適化するのは簡単ではありません。さまざまな問題が発生し、リソースの非効率な利用やコスト増、さらには顧客体験の低下につながることがあります。
Datadog の Snowflake インテグレーションを使うと、パフォーマンス改善とコスト削減に役立つ長時間実行クエリを見つけ出したり、リアル タイムのセキュリティ脅威を特定したり、Snowpark ワークロードを監視したりできます。
Snowflake データをパースした後、Datadog はすぐに使える概要ダッシュボードに収集された全リソースに関する洞察を入力します。また、Snowpark の実行失敗や異常な量のログイン試行に対するアラートを設定するための推奨モニターも提供します。
注: メトリクスは Snowflake へのクエリで収集されます。Datadog インテグレーションによって作成されたクエリは、Snowflake によって請求されます。
セットアップ
インストール
インストール手順は不要です。
構成
注: PrivateLink 経由で接続された Snowflake アカウントは、現在 Snowflake インテグレーションではサポートされていません。
PrivateLink 構成では、従来の Snowflake agent インテグレーションの利用を推奨します。
Snowflake アカウントに接続
- Snowflake アカウント URL を確認します。
Snowflake インテグレーション タイル で、Account URL フィールドに Snowflake アカウント URL を入力します。
Resource Collection タブで、収集したいリソースを有効化します:
Account および Organization Usage メトリクス
以下の表では、収集されるメトリクスの種類と関連するメトリクスのプレフィックスについて説明します。
| 型 | 説明 | 収集されるメトリクスのプレフィックス |
|---|
| アカウント使用量 | アカウントレベルでのストレージ使用量、クレジット消費量、およびクエリメトリクス。
毎時収集。 | snowflake.auto_recluster
snowflake.billing
snowflake.data_transfer
snowflake.logins
snowflake.pipe
snowflake.query
snowflake.replication
snowflake.storage
snowflake.storage.database
snowflake.storage.table |
| 組織使用量 | 組織レベルでのクレジット消費量、データ転送履歴、予算メトリクス
毎日収集。 | snowflake.organization |
これらのメトリクスは、次の 2 つの期間のいずれかで収集できます:
- Past 24 Hours: 過去 24 時間で集計されたメトリクスを収集します。例: 1-01-25 04:00:00 〜 1-02-25 04:00:00。
- Current Day: 当日分で集計されたメトリクスを収集します。例: 1-02-25 00:00:00 〜 1-02-25 04:00:00。
ログ
以下の表は、収集されるログの種類と含まれる Snowflake テーブルを示しています。
これらのログはユース ケースに応じて複数の期間で収集できます。期間の設定は Snowflake インテグレーション タイル で構成できます。
Cloud Cost Management
Cloud Cost Management を有効化すると、SNOWFLAKE.ORGANIZATION_USAGE.USAGE_IN_CURRENCY_DAILY テーブルから集計された Snowflake のコスト メトリクスを受け取れます。これらのメトリクスを Cloud Cost Management と組み合わせることで、コストと利用状況をより深く把握できます。
- Snowflake を監視するために、Datadog 固有のロールとユーザーを作成します。Snowflake 環境で以下の一連のコマンドを実行し、Datadog にアクセス可能なユーザーを作成します。
推奨ウェアハウス設定
- auto-suspend を 30s に設定した XS ウェアハウスを作成します。
- 必要に応じて、日中に通常稼働している既存の XS ウェアハウスを使うのが、最もコスト効率の高い選択肢になる場合があります。注: このインテグレーションから実行されるクエリは、既存ウェアハウスのパフォーマンスに影響する可能性があります。クエリ性能が重要なウェアハウスでインテグレーションを実行することは推奨しません。
-- Snowflake の利用状況を監視するための新しいロールを作成します。ロール名は任意に変更できます。
create role DATADOG;
-- SNOWFLAKE データベースに対する権限を新しいロールへ付与します。
grant imported privileges on database SNOWFLAKE to role DATADOG;
-- 既定のウェアハウスを使用できるよう、ロール DATADOG に usage を付与します。
grant usage on warehouse <WAREHOUSE> to role DATADOG;
-- 次の ACCOUNT_USAGE ビューを新しいロールに付与します。Snowflake のアカウント使用状況ログおよびメトリクスを収集したい場合に実施してください。
grant database role SNOWFLAKE.OBJECT_VIEWER to role DATADOG;
grant database role SNOWFLAKE.USAGE_VIEWER to role DATADOG;
grant database role SNOWFLAKE.GOVERNANCE_VIEWER to role DATADOG;
grant database role SNOWFLAKE.SECURITY_VIEWER to role DATADOG;
-- ORGANIZATION_USAGE_VIEWER を新しいロールに付与します。Snowflake の組織使用状況メトリクスを収集したい場合に実施してください。
grant database role SNOWFLAKE.ORGANIZATION_USAGE_VIEWER to role DATADOG;
-- ORGANIZATION_BILLING_VIEWER を新しいロールに付与します。Snowflake のコスト データを収集したい場合に実施してください。
grant database role SNOWFLAKE.ORGANIZATION_BILLING_VIEWER to role DATADOG;
-- event table のデータベース、スキーマ、テーブルに対する usage と select を付与します。
grant usage on database <EVENT_TABLE_DATABASE> to role DATADOG;
grant usage on schema <EVENT_TABLE_DATABASE>.<EVENT_TABLE_SCHEMA> to role DATADOG;
grant select on table <EVENT_TABLE_DATABASE>.<EVENT_TABLE_SCHEMA>.<EVENT_TABLE_NAME> to role DATADOG;
grant application role SNOWFLAKE.EVENTS_VIEWER to role DATADOG;
grant application role SNOWFLAKE.EVENTS_ADMIN to role DATADOG;
-- カスタム クエリのメトリクス収集に利用するテーブルに対して、データベース、スキーマ、テーブルの usage と select を付与します。
grant usage on database <CUSTOM_QUERY_DATABASE> to role DATADOG;
grant usage on schema <CUSTOM_QUERY_DATABASE>.<CUSTOM_QUERY_SCHEMA> to role DATADOG;
grant select on table <CUSTOM_QUERY_DATABASE>.<CUSTOM_QUERY_SCHEMA>.<CUSTOM_QUERY_TABLE> to role DATADOG;
-- ユーザーを作成します。
create user <USERNAME>
LOGIN_NAME = <USERNAME>
password = '<PASSWORD>'
default_warehouse =<WAREHOUSE>
default_role = DATADOG;
-- 監視用ロールをユーザーに付与します。
grant role DATADOG to user <USERNAME>
- キーペア認証を構成します。公開キーは先ほど作成したユーザーに割り当て、秘密キーは Datadog にアップロードし、Datadog が Snowflake アカウントに接続できるようにします。
a. Snowflake の手順 に従って、秘密鍵を作成してアップロードします。Datadog は現在、暗号化されていない秘密鍵のみをサポートしています。
b. Snowflake の手順 に従って、公開鍵を作成します。
c. Snowflake の手順 に従って、先ほど作成したユーザーに公開鍵を割り当てます。
Datadog が Snowflake アカウントからデータを収集するには、特定の IP アドレス プレフィックスを許可リストに追加する必要があります。Datadog に属する IP プレフィックスの一覧は
IP ranges ページ にあり、許可すべき範囲は
webhooks の下に掲載されています。
カスタムメトリクス
Snowflake インテグレーションは、カスタム クエリを使ってカスタム メトリクスを収集することもできます。ユーザーが独自の SQL クエリを書き、必要なデータを抽出して Datadog 上でメトリクスとメトリクス タグとして表示できます。複数行クエリは、1 行に 1 クエリずつ記述してください。
デフォルトでは、インテグレーションは共有の SNOWFLAKE データベースと ACCOUNT_USAGE スキーマに接続します。ACCOUNT_USAGE スキーマ以外のテーブルをクエリする場合は、構成したロールがテーブルにアクセスする適切な権限を持っていることを確認してください。
以下の表では、カスタムメトリクスを定義するために使用するフィールドについて説明します。
| フィールド | 説明 | 必須 |
|---|
| Custom Metric Identifier | これはカスタムメトリクスの識別子であり、各アカウント内の異なるカスタムメトリクスをそれぞれのカスタムクエリにリンクするために使用されます。 | はい |
| クエリ | 実行する SQL です。単純なステートメントや複数行のスクリプトである可能性があります。結果のすべての行が評価されます。 | はい |
| Metadata 列 | これは、左から右に順番に並べられた各列を表すリストです。各列には 2 つの必須フィールドがあります。 | |
- Custom Column Name:
これは
metric_prefix に追加して完全なメトリクス名を形成するサフィックスです。例えば、my_custom_metric.count は完全なメトリクス名 snowflake.my_custom_metric.count になります。タイプが Tag Key と指定されている場合、この列は代わりにこのクエリで収集されたすべてのメトリクスにタグとして適用されます。 - Metadata Type:
これは送信方法です (例: gauge、count、rate)。これも、この列の項目の名前と値 (
<NAME>:<ROW_VALUE>) で行内の各メトリクスにタグを付けるように設定できます。 | はい |
注:
- 定義された列の少なくとも 1 つの項目は、メトリクスタイプ (gauge、count、rate、distribution) でなければなりません。
- 列内のアイテム数は、クエリで返された列数と同じである必要があります。
- 列の項目を定義する順番は、クエリで返される順番と同じでなければなりません。
例:
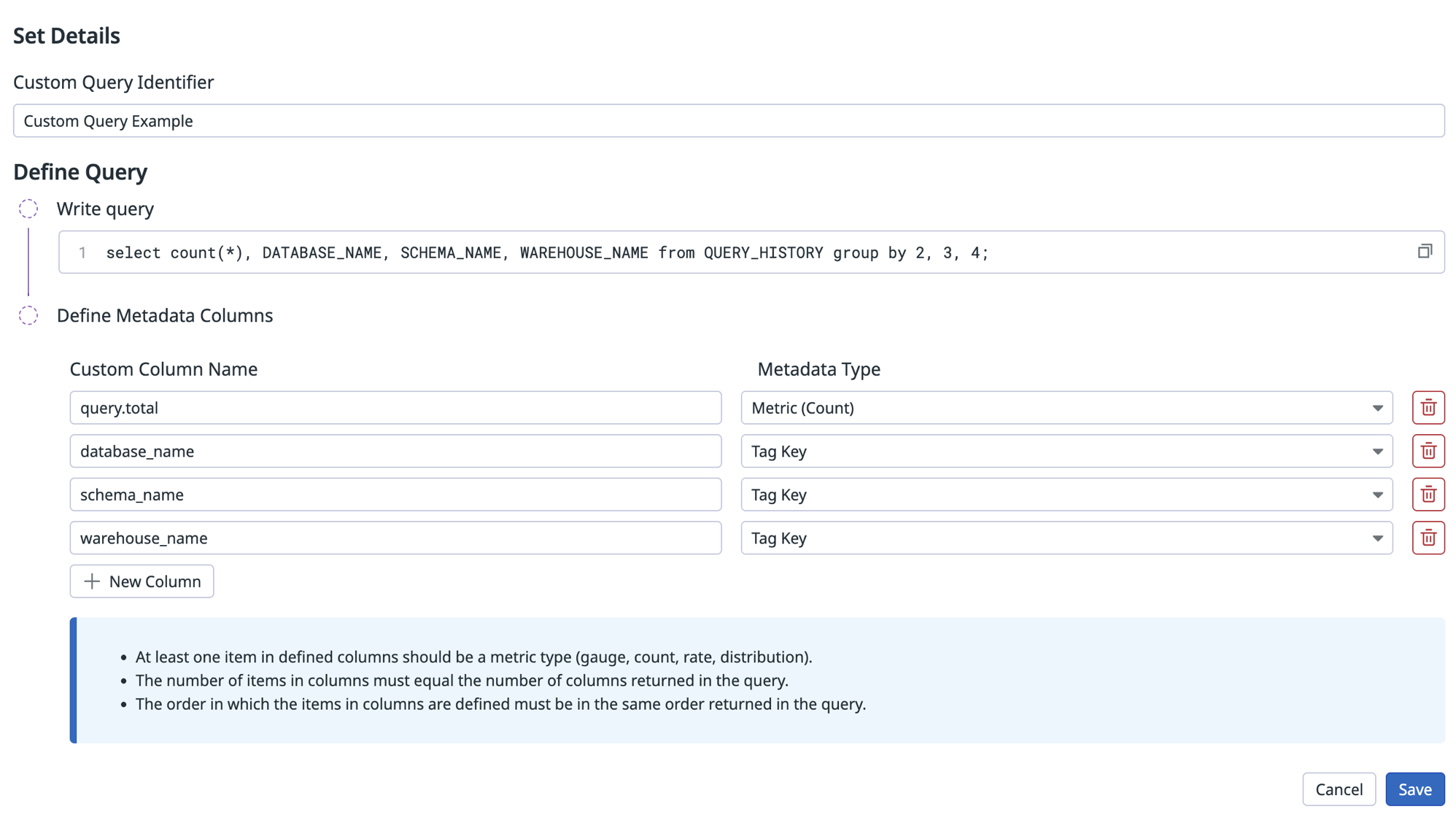
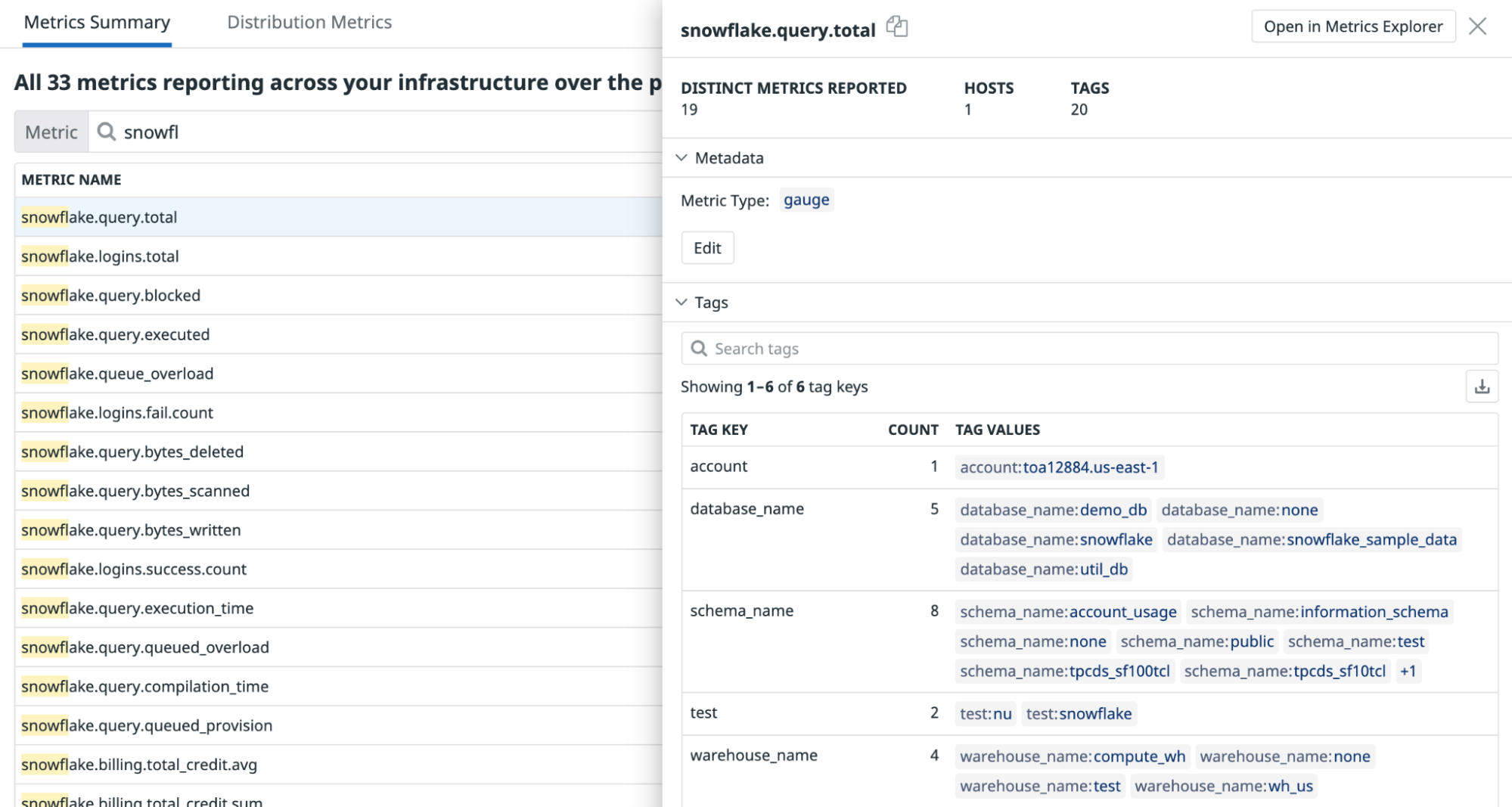
検証
結果を確認するには、Metric Summary を使用してメトリクスを検索します。
参照テーブル
Reference Tables を使うと、Snowflake テーブルの追加フィールドを取り込み、テレメトリを自動的に拡張 (エンリッチ) して結合できます。値フィールドを主キーにマッピングしておくことで、そのキーを含むログやイベントに対して追加フィールドを自動的に付与できます。
Reference Tables の取り込みを有効化する
Snowflake Workspace へ移動します。
Datadog で使用する Snowflake Table の名前を確認します。
ワークスペースで次のコマンドを実行し、そのテーブルに対する Datadog の read permissions を付与します。
GRANT USAGE ON DATABASE <REFERENCE_TABLE_DATABASE> TO ROLE DATADOG;
GRANT USAGE ON SCHEMA <REFERENCE_TABLE_DATABASE>.<REFERENCE_TABLE_SCHEMA> TO ROLE DATADOG;
GRANT SELECT ON TABLE <REFERENCE_TABLE_DATABASE>.<REFERENCE_TABLE_SCHEMA>.<REFERENCE_TABLE_NAME> TO ROLE DATADOG;
- Insufficient Privileges エラーが発生した場合は、組織の Snowflake 管理者に連絡して権限を付与してもらってください。上記の権限が Snowflake テーブルに付与されていないと、Datadog は Snowflake テーブルを Reference Tables に取り込めません。
ステップ 6 の Reference Table 設定で使用するため、Table Name と Primary Key をコピーして控えておきます。
Datadog で Snowflake tile を開き、テーブルを取り込みたいアカウントの Reference Tables タブをクリックします。まだアカウントを設定していない場合は、構成 セクションの手順に従ってください。
Add New Reference Table ボタンをクリックします。フォームが開いたら、次の項目を入力します:
- Datadog Table Name: Datadog の Reference Tables 製品内でテーブルを識別する名前です。英数字とアンダースコアで複数語を区切って構成します (例:
my_reference_table)。組織内で一意になるようにしてください。 - Snowflake Table Name: ステップ 4 でコピーした、取り込み対象の Snowflake テーブル名です。
- Primary Key: ステップ 4 でコピーした、Snowflake テーブルの主キーです。
- Save をクリックします。
- クエリがスケジュール実行された後、数分以内に Datadog 側へデータが反映されるはずです。
取り込みエラーはイベントとして報告されます。
source:snowflake を検索すると、イベント エクスプローラー で確認できます。 - Reference Tables に移動し、Datadog Table Name を使って新しく作成したテーブルを検索します。
- Snowflake Table のステータスは File セクションで確認できます。エラーが表示される場合は、Snowflake 側で解消してください。
Snowflake テーブルを Datadog の Reference Tables に取り込む際の推奨事項
Snowflake のデータを Datadog に取り込む際は、パフォーマンスとコストを最適化できるようにテーブル設計を整えておくことが重要です。ここでは、取り込みに向けて Snowflake テーブルを準備する際の推奨事項を紹介します。
Datadog によるデータ取り込みの仕組み
Datadog は指定した Snowflake テーブルに対して、次のクエリを 1 時間ごと に実行します:
SELECT * FROM your_table;
この処理は全カラム・全行を取得するため、Datadog では監視に必要なフィールドだけに絞った ビューを作成することを強く推奨しています。不要なデータ転送と処理を減らせるため、コスト面でも有利です。
ビューを使って取得対象を絞る
テーブル全体を公開する代わりに、必要なカラムのみを選択する ビュー を作成します:
CREATE VIEW my_datadog_view AS
SELECT my_column_1, my_column_2
FROM my_raw_table;
詳細は Snowflake Views ドキュメント を参照してください。
パフォーマンスとコストの考慮点
次のようなケースでは、通常の ビュー が最適にならないことがあります。たとえば:
効率を上げるには、Materialized View、Dynamic Table、あるいは 事前計算済みテーブル などの選択肢も検討してください。
適切なテーブル構成の選び方
| 選択肢 | 適したケース | トレードオフ |
|---|
| Materialized View | クエリの計算コストが高く、性能が重要な場合。 | クエリは高速化しますが、追加ストレージを消費し、更新 (refresh) の運用が必要です。 |
| Dynamic Table | データの鮮度が重要で、自動更新が必要な場合。 | 更新は Snowflake が管理しますが、コストは更新頻度に左右されます。 |
| Precomputed Table (via DBT, ETL, etc.) | データ更新と性能を完全にコントロールしたい場合。 | 効率は高い一方で、データ管理が複雑になります。 |
Materialized View を使う
Materialized View はクエリ結果を事前計算して保存するため、データ取得を大幅に高速化できます。
CREATE MATERIALIZED VIEW my_fast_view AS
SELECT important_column_1, important_column_2
FROM my_raw_table;
Materialized View は 追加ストレージを消費 し、データを最新に保つための更新が必要です。詳細は Materialized Views ドキュメント を参照してください。
Dynamic Table を使う場合
データの更新頻度が高く、フル リフレッシュでは時間がかかりすぎる場合は、Dynamic Table を使うことで Snowflake に増分更新を管理させることができます。
CREATE DYNAMIC TABLE my_dynamic_table
TARGET_LAG = '10 MINUTES'
WAREHOUSE = my_warehouse
AS SELECT important_column_1, important_column_2 FROM my_raw_table;
Snowflake は TARGET_LAG 設定に基づいて増分更新を自動的に処理します。詳細は Dynamic Table ドキュメント を参照してください。
重要ポイント
- ビューを使うことで、Datadog に送るデータを必要最小限に抑え、クエリ パフォーマンスの最適化につながります。
- クエリが遅い場合は、効率改善のために Materialized View、Dynamic Table、事前計算済みテーブル の利用を検討してください。
- 手法を選ぶ前に、コストとパフォーマンスのトレードオフ を評価することが重要です。
これらの推奨事項に沿って設計すると、Snowflake と Datadog の連携を効率よく、コスト効果の高い形で運用できます。組織にとって最適な選択肢の判断に迷う場合は、Snowflake Support へお問い合わせください。
Snowflake Reference Table のトラブル シューティング
- Reference Table 名は、Datadog 内で一意である必要があります。
- Datadog は Snowflake のテーブル名を検証しません。Reference Tables にテーブルが表示されない場合は、Snowflake Table Name の入力が正しいか確認してください。
- それでも表示されない場合は、Reference Table ドキュメントの Limitations セクションを確認し、該当テーブルが制約事項に当てはまらないか確認してください。
- Datadog 側の取り込みに関する問題は Datadog Support へ、Snowflake テーブル側の問題は Snowflake Support へお問い合わせください。
収集データ
メトリクス
イベント
Snowflake Web インテグレーションにはイベントは含まれていません。
サービス チェック
Snowflake Web インテグレーションには、サービスのチェック機能は含まれていません。
トラブルシューティング
ご不明な点は、Datadog のサポートチームまでお問い合わせください。
Agent チェック: Snowflake
Snowflake Agent チェックはサポートされなくなりました。追加機能および Snowflake への API コール量の削減のため、新しい Snowflake インテグレーションへの切り替えをお勧めします。
Agent: 概要
このチェックは Datadog Agent を通じて Snowflake を監視します。Snowflake は SaaS 型の分析データ ウェアハウスであり、クラウド インフラ上で稼働します。
このインテグレーションでは、クレジット使用量、請求、ストレージ、クエリ メトリクスなどを監視します。
注: メトリクスは Snowflake へのクエリとともに収集されます。Datadog インテグレーションによるクエリは、Snowflake によって課金されます。
Agent: セットアップ
以下の手順に従って、このチェックをインストールし、ホストで実行中の Agent に対して構成します。
Agent: インストール
Snowflake チェックは Datadog Agent パッケージに含まれています。
注: Snowflake チェックは、Python 2 を使用する Datadog Agent v6 では利用できません。Agent v6 で Snowflake を利用するには、Use Python 3 with Datadog Agent v6 を参照するか、Agent v7 へアップグレードしてください。
Agent: 構成
Snowflake は、`SYSADMIN` などの代替ロールにアクセス許可を付与することをお勧めします。詳細については、
ACCOUNTADMIN ロールの制御の詳細をご覧ください。
Snowflake を監視するための Datadog 固有のロールとユーザーを作成します。Snowflake で、以下を実行して、ACCOUNT_USAGE スキーマにアクセスできるカスタムロールを作成します。
注: 既定では、このインテグレーションは SNOWFLAKE データベースと ACCOUNT_USAGE スキーマを監視します。ORGANIZATION_USAGE スキーマを監視する方法は「Collecting Organization Data」を参照してください。
このデータベースは既定で利用可能ですが、閲覧できるのは ACCOUNTADMIN ロールのユーザー、または ACCOUNTADMIN によって権限を付与されたロール のユーザーのみです。
use role ACCOUNTADMIN;
grant imported privileges on database snowflake to role SYSADMIN;
use role SYSADMIN;
代替案として、ACCOUNT_USAGE へアクセスできる DATADOG カスタム ロールを作成することもできます。
-- Create a new role intended to monitor Snowflake usage.
create role DATADOG;
-- Grant privileges on the SNOWFLAKE database to the new role.
grant imported privileges on database SNOWFLAKE to role DATADOG;
-- Grant usage to your default warehouse to the role DATADOG.
grant usage on warehouse <WAREHOUSE> to role DATADOG;
-- Create a user, skip this step if you are using an existing user.
create user DATADOG_USER
LOGIN_NAME = DATADOG_USER
password = '<PASSWORD>'
default_warehouse = <WAREHOUSE>
default_role = DATADOG
default_namespace = SNOWFLAKE.ACCOUNT_USAGE;
-- Grant the monitor role to the user.
grant role DATADOG to user <USER>;
Agent の設定ディレクトリ ルートにある conf.d/ フォルダ内の snowflake.d/conf.yaml を編集し、Snowflake のパフォーマンス データ収集を開始します。利用可能な設定オプションの一覧は sample snowflake.d/conf.yaml を参照してください。
## @param account - string - required
## Name of your account (provided by Snowflake), including the platform and region if applicable.
## For more information on Snowflake account names,
## see https://docs.snowflake.com/en/user-guide/connecting.html#your-snowflake-account-name
#
- account: <ORG_NAME>-<ACCOUNT_NAME>
## @param username - string - required
## Login name for the user.
#
username: <USER>
## @param password - string - required
## Password for the user
#
password: <PASSWORD>
## @param role - string - required
## Name of the role to use.
##
## By default, the SNOWFLAKE database is only accessible by the ACCOUNTADMIN role. Snowflake recommends
## configuring a role specific for monitoring:
## https://docs.snowflake.com/en/sql-reference/account-usage.html#enabling-account-usage-for-other-roles
#
role: <ROLE>
## @param min_collection_interval - number - optional - default: 15
## This changes the collection interval of the check. For more information, see:
## https://docs.datadoghq.com/developers/write_agent_check/#collection-interval
##
## NOTE: Most Snowflake ACCOUNT_USAGE views are populated on an hourly basis,
## so to minimize unnecessary queries, set the `min_collection_interval` to 1 hour.
#
min_collection_interval: 3600
# @param disable_generic_tags - boolean - optional - default: false
# Generic tags such as `cluster` will be replaced by <INTEGRATION_NAME>_cluster to avoid
# getting mixed with other integration tags.
# disable_generic_tags: true
In the default `conf.yaml`, the
min_collection_interval is 1 hour.
Snowflake metrics are aggregated by day, you can increase the interval to reduce the number of queries.
Note: Snowflake ACCOUNT_USAGE views have a
known latency of 45 minutes to 3 hours.
その後、Agent を再起動 します。
組織データの収集
デフォルトでは、このインテグレーションは ACCOUNT_USAGE スキーマを監視しますが、代わりに組織レベルのメトリクスを監視するように設定することができます。
組織メトリクスを収集するには、インテグレーションの構成でスキーマフィールドを ORGANIZATION_USAGE に変更し、min_collection_interval を 43200 に増やします。ほとんどの組織クエリのレイテンシーが最大 24 時間であるため、これにより Snowflake へのクエリ数を減らすことができます。
注: 組織のメトリクスを監視するには、user が ORGADMIN ロールを持っている必要があります。
- schema: ORGANIZATION_USAGE
min_collection_interval: 43200
デフォルトでは、一部の組織メトリクスのみが有効になっています。利用可能なすべての組織メトリクスを収集するには、metric_groups 構成オプションを使用します。
metric_groups:
- snowflake.organization.warehouse
- snowflake.organization.currency
- snowflake.organization.credit
- snowflake.organization.storage
- snowflake.organization.contracts
- snowflake.organization.balance
- snowflake.organization.rate
- snowflake.organization.data_transfer
さらに、アカウントと組織の両方のメトリクスを同時に監視することができます。
instances:
- account: example-inc
username: DATADOG_ORG_ADMIN
password: "<PASSWORD>"
role: SYSADMIN
schema: ORGANIZATION_USAGE
database: SNOWFLAKE
min_collection_interval: 43200
- account: example-inc
username: DATADOG_ACCOUNT_ADMIN
password: "<PASSWORD>"
role: DATADOG_ADMIN
schema: ACCOUNT_USAGE
database: SNOWFLAKE
min_collection_interval: 3600
複数環境のデータ収集
複数の Snowflake 環境のデータを収集したい場合は、snowflake.d/conf.yaml ファイルに各環境をインスタンスとして追加します。例えば、DATADOG_SYSADMIN と DATADOG_USER という 2 つのユーザーのデータを収集する必要がある場合:
instances:
- account: example-inc
username: DATADOG_SYSADMIN
password: "<PASSWORD>"
role: SYSADMIN
database: EXAMPLE-INC
- account: example-inc
username: DATADOG_USER
password: "<PASSWORD>"
role: DATADOG_USER
database: EXAMPLE-INC
プロキシ構成
Snowflake は、proxy 構成のための環境変数 を設定することを推奨しています。
また、snowflake.d/conf.yaml の init_config 配下で、proxy_host、proxy_port、proxy_user、proxy_password を設定することもできます。
注: Snowflake は proxy 設定を自動的に整形し、標準の proxy 環境変数 を設定します。
これらの変数は、Docker、ECS、Kubernetes のようなオーケストレーターを含め、インテグレーションからのすべてのリクエストにも影響します。
Snowflake 構成へのプライベート接続
Snowflake で private connectivity (例: AWS PrivateLink) が有効な場合は、account 設定オプションを次の形式に変更して Snowflake インテグレーションを構成できます。
- account: <ACCOUNT>.<REGION_ID>.privatelink
Snowflake カスタムクエリ
Snowflake インテグレーションはカスタム クエリをサポートしています。既定では、共有の SNOWFLAKE データベースと ACCOUNT_USAGE スキーマに接続します。
別のスキーマやデータベースでカスタム クエリを実行するには、sample snowflake.d/conf.yaml に別のインスタンスを追加し、database と schema を指定してください。
その際、指定したデータベースまたはスキーマに対して、ユーザーとロールがアクセス権を持っていることを確認してください。
コンフィギュレーションオプション
custom_queries には以下のオプションがあります。
| オプション | 必須 | 説明 |
|---|
| クエリ | はい | 実行する SQL です。単純なステートメントでも複数行のスクリプトでもかまいません。結果のすべての行が評価されます。複数行のスクリプトが必要な場合は、パイプ ( |
| 列 | はい | これは、左から右へ並ぶ各カラムを順番に表すリストです。
必須のデータは次の 2 つです:
- name: metric_prefix の末尾に付与されるサフィックスで、完全なメトリクス名を構成します。type が tag の場合、このカラムはクエリで収集されるすべてのメトリクスにタグとして適用されます。
- type: 送信方法 (gauge、count、rate など) を指定します。tag に設定することもでき、その場合はこのカラムの項目名と行の値を <NAME>:<ROW_VALUE> 形式で、行内の各メトリクスにタグ付けします。 |
| usage-metering-get-hourly-usage-for-lambda-traced-invocations | いいえ | 各メトリクスに適用する静的タグのリスト。 |
注:
定義された columns の少なくとも 1 つの項目は、メトリクスタイプである必要があります (例えば、gauge、count、rate)。
列の項目の数は、クエリで返される列の数と同じでなければなりません。
columns の項目を定義する順番は、クエリで返される順番と同じでなければなりません。
custom_queries:
- query: select F3, F2, F1 from Table;
columns:
- name: f3_metric_alias
type: gauge
- name: f2_tagkey
type: tag
- name: f1_metric_alias
type: count
tags:
- test:snowflake
例
次の例は、QUERY_HISTORY ビュー 内の全クエリ数をカウントし、データベース、スキーマ、ウェアハウス名でタグ付けするクエリです。
select count(*), DATABASE_NAME, SCHEMA_NAME, WAREHOUSE_NAME from QUERY_HISTORY group by 2, 3, 4;
カスタムクエリの構成
instances のカスタムクエリのコンフィギュレーションは、以下のようになります。
custom_queries:
- query: select count(*), DATABASE_NAME, SCHEMA_NAME, WAREHOUSE_NAME from QUERY_HISTORY group by 2, 3, 4;
columns:
- name: query.total
type: gauge
- name: database_name
type: tag
- name: schema_name
type: tag
- name: warehouse_name
type: tag
tags:
- test:snowflake
Agent: 検証
Agent が正しく動作しているかを確認するには、Agent の status サブコマンド を実行し、Checks セクションで snowflake を探してください。
Agent: データ収集
注: 既定で有効化されているメトリクス グループは次のものだけです:
snowflake.query.*、
snowflake.billing.*、
snowflake.storage.*、
snowflake.logins.*。
他のメトリクス グループも収集したい場合は、このインテグレーションのサンプル コンフィギュレーション ファイルを参照してください: サンプル コンフィギュレーション ファイル。
Agent: メトリクス
このチェックで提供されるメトリクスのリストについては、メトリクスを参照してください。
Agent: イベント
Snowflake には、イベントは含まれません。
Agent: サービスチェック
snowflake.can_connect
チェックが Snowflake の認証情報で認証できない場合は CRITICAL を返し、それ以外は OK を返します。
ステータス: ok, critical
Agent: トラブルシューティング
ご不明な点は、Datadog のサポートチームまでお問い合わせください。
その他の参考資料
役立つドキュメント、リンク、記事: