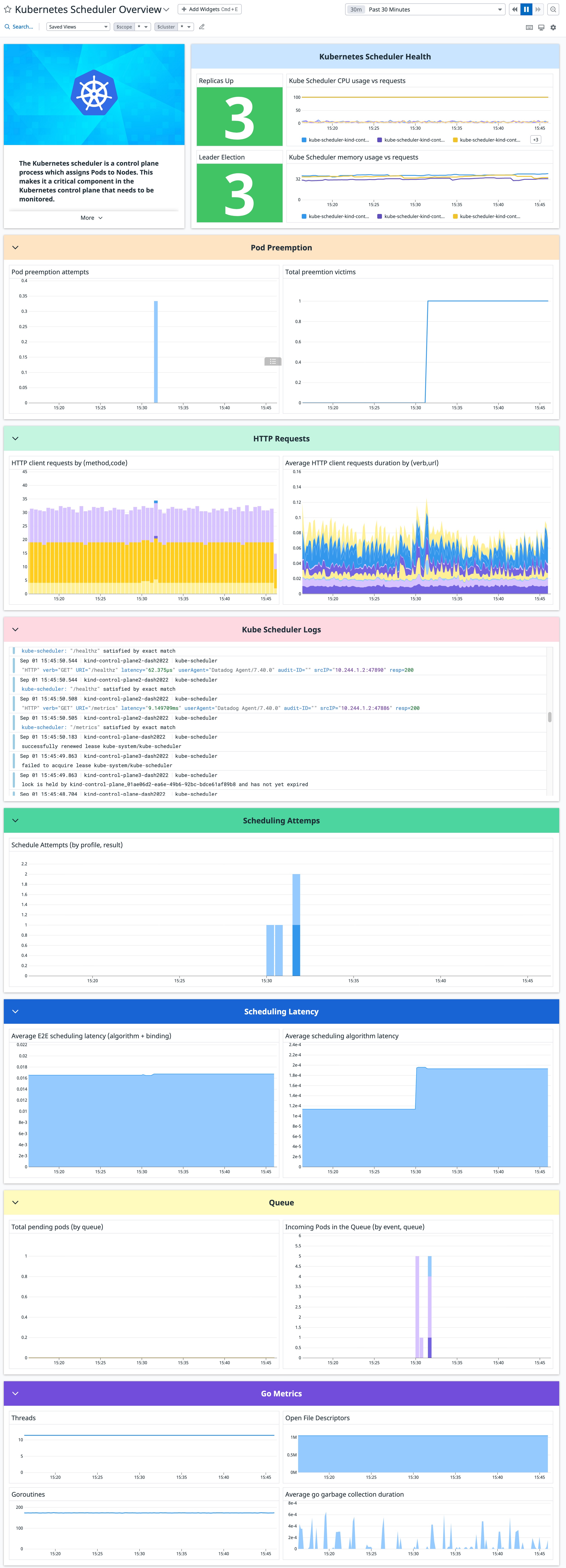
kube_scheduler.binding_duration.count
(gauge) | Number of latency in seconds |
kube_scheduler.binding_duration.sum
(gauge) | Total binding latency in seconds |
kube_scheduler.cache.lookups
(count) | Number of equivalence cache lookups, by whether or not a cache entry was found |
kube_scheduler.client.http.requests
(count) | Number of HTTP requests, partitioned by status code, method, and host |
kube_scheduler.client.http.requests_duration.count
(gauge) | Number of client requests. Broken down by verb and URL |
kube_scheduler.client.http.requests_duration.sum
(gauge) | Total latency. Broken down by verb and URL |
kube_scheduler.gc_duration_seconds.count
(gauge) | Number of the GC invocation |
kube_scheduler.gc_duration_seconds.quantile
(gauge) | GC invocation durations quantiles |
kube_scheduler.gc_duration_seconds.sum
(gauge) | GC invocation durations sum |
kube_scheduler.goroutine_by_scheduling_operation
(gauge) | Number of running goroutines split by the work they do such as binding (alpha; requires k8s v1.26+) |
kube_scheduler.goroutines
(gauge) | Number of goroutines that currently exist |
kube_scheduler.max_fds
(gauge) | Maximum allowed open file descriptors |
kube_scheduler.open_fds
(gauge) | Number of open file descriptors |
kube_scheduler.pending_pods
(gauge) | Number of pending pods, by the queue type (requires k8s v1.15+) |
kube_scheduler.pod_preemption.attempts
(count) | Number of preemption attempts in the cluster till now |
kube_scheduler.pod_preemption.victims.count
(gauge) | Number of selected pods during the latest preemption round |
kube_scheduler.pod_preemption.victims.sum
(gauge) | Total selected pods during the latest preemption round |
kube_scheduler.queue.incoming_pods
(count) | Number of pods added to scheduling queues by event and queue type (requires k8s v1.17+) |
kube_scheduler.schedule_attempts
(gauge) | Number of attempts to schedule pods, by the result. ‘unschedulable’ means a pod could not be scheduled, while ’error’ means an internal scheduler problem. |
kube_scheduler.scheduling.algorithm.predicate_duration.count
(gauge) | Number of scheduling algorithm predicate evaluation |
kube_scheduler.scheduling.algorithm.predicate_duration.sum
(gauge) | Total scheduling algorithm predicate evaluation duration |
kube_scheduler.scheduling.algorithm.preemption_duration.count
(gauge) | Number of scheduling algorithm preemption evaluation |
kube_scheduler.scheduling.algorithm.preemption_duration.sum
(gauge) | Total scheduling algorithm preemption evaluation duration |
kube_scheduler.scheduling.algorithm.priority_duration.count
(gauge) | Number of scheduling algorithm priority evaluation |
kube_scheduler.scheduling.algorithm.priority_duration.sum
(gauge) | Total scheduling algorithm priority evaluation duration |
kube_scheduler.scheduling.algorithm_duration.count
(gauge) | Number of scheduling algorithm latency |
kube_scheduler.scheduling.algorithm_duration.sum
(gauge) | Total scheduling algorithm latency |
kube_scheduler.scheduling.attempt_duration.count
(gauge) | Scheduling attempt latency in seconds (scheduling algorithm + binding) (requires k8s v1.23+) |
kube_scheduler.scheduling.attempt_duration.sum
(gauge) | Total scheduling attempt latency in seconds (scheduling algorithm + binding) (requires k8s v1.23+) |
kube_scheduler.scheduling.e2e_scheduling_duration.count
(gauge) | Number of E2e scheduling latency (scheduling algorithm + binding) |
kube_scheduler.scheduling.e2e_scheduling_duration.sum
(gauge) | Total E2e scheduling latency (scheduling algorithm + binding) |
kube_scheduler.scheduling.pod.scheduling_attempts.count
(gauge) | Number of attempts to successfully schedule a pod (requires k8s v1.23+) |
kube_scheduler.scheduling.pod.scheduling_attempts.sum
(gauge) | Total number of attempts to successfully schedule a pod (requires k8s v1.23+) |
kube_scheduler.scheduling.pod.scheduling_duration.count
(gauge) | E2e latency for a pod being scheduled which may include multiple scheduling attempts (requires k8s v1.23+) |
kube_scheduler.scheduling.pod.scheduling_duration.sum
(gauge) | Total e2e latency for a pod being scheduled which may include multiple scheduling attempts (requires k8s v1.23+) |
kube_scheduler.scheduling.scheduling_duration.count
(gauge) | Number of scheduling split by sub-parts of the scheduling operation |
kube_scheduler.scheduling.scheduling_duration.quantile
(gauge) | Scheduling latency quantiles split by sub-parts of the scheduling operation |
kube_scheduler.scheduling.scheduling_duration.sum
(gauge) | Total scheduling latency split by sub-parts of the scheduling operation |
kube_scheduler.slis.kubernetes_healthcheck
(gauge) | Result of a single scheduler healthcheck (alpha; requires k8s v1.26+) |
kube_scheduler.slis.kubernetes_healthcheck_total
(count) | Cumulative results of all scheduler healthchecks (alpha; requires k8s v1.26+) |
kube_scheduler.threads
(gauge) | Number of OS threads created |
kube_scheduler.volume_scheduling_duration.count
(gauge) | Number of Volume scheduling |
kube_scheduler.volume_scheduling_duration.sum
(gauge) | Total Volume scheduling stage latency |