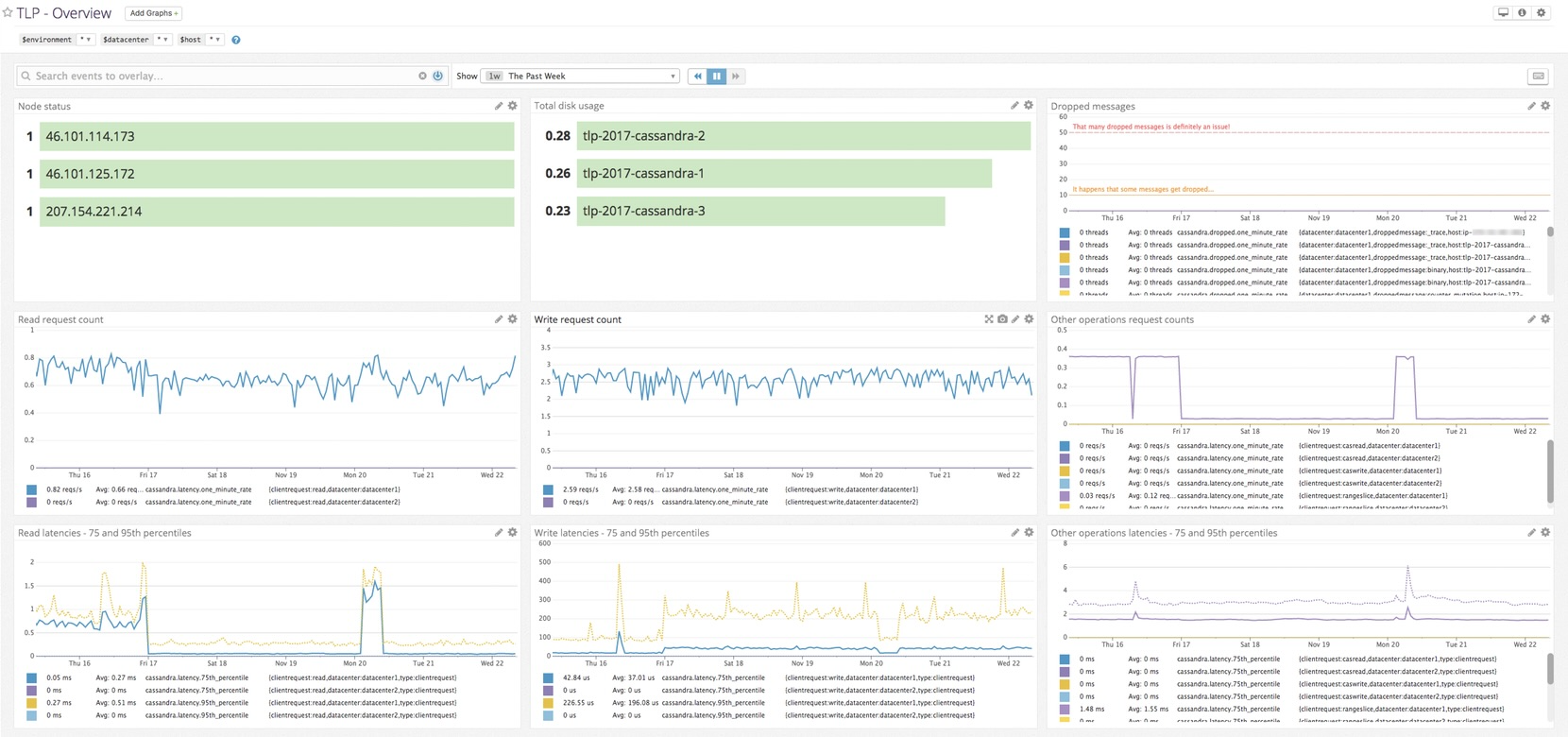
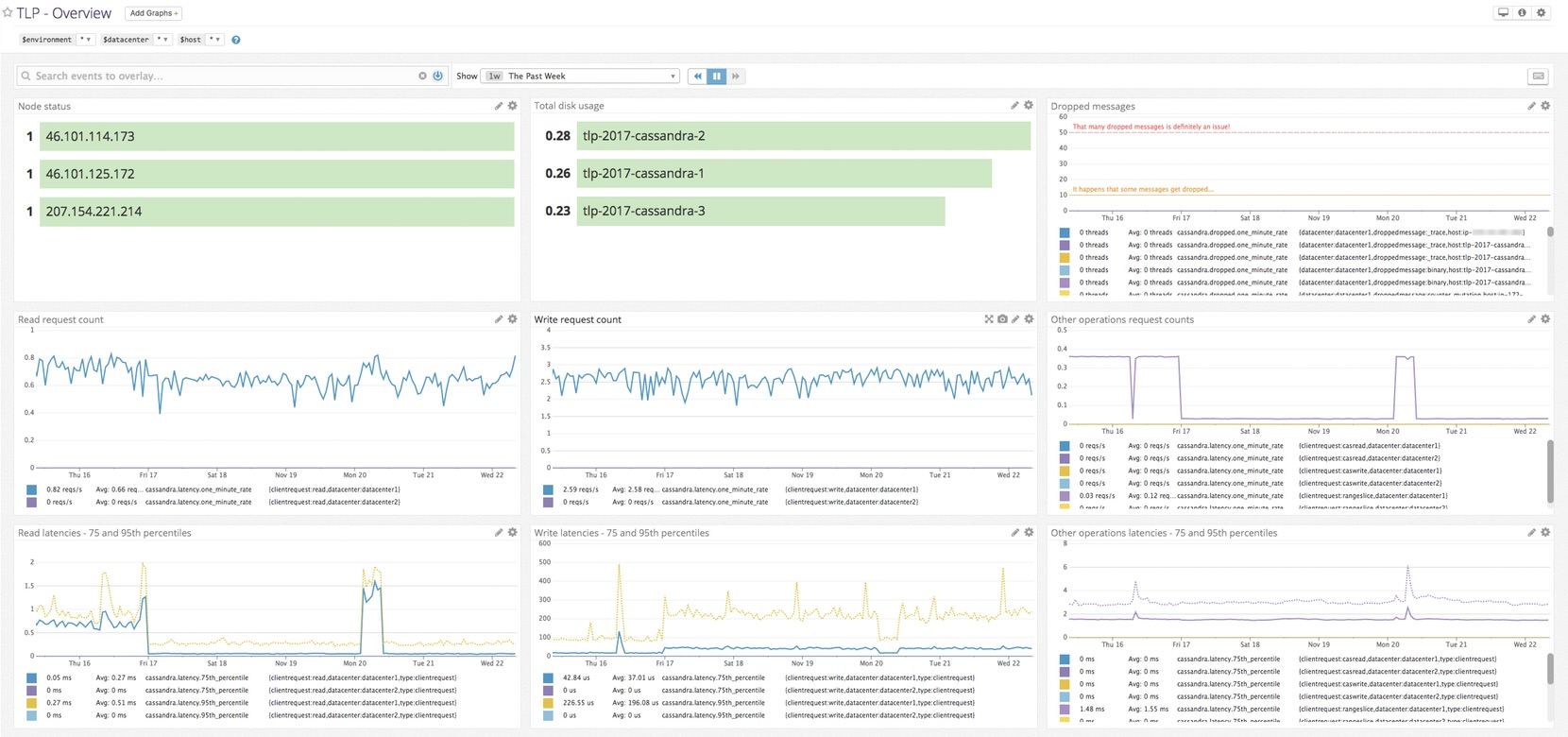
cassandra.active_tasks
(gauge) | The number of tasks that the thread pool is actively executing.
Shown as task |
cassandra.bloom_filter_false_ratio
(gauge) | The ratio of Bloom filter false positives to total checks.
Shown as fraction |
cassandra.bytes_flushed.count
(gauge) | The amount of data that was flushed since (re)start.
Shown as byte |
cassandra.cas_commit_latency.75th_percentile
(gauge) | The latency of paxos commit round - p75.
Shown as microsecond |
cassandra.cas_commit_latency.95th_percentile
(gauge) | The latency of paxos commit round - p95.
Shown as microsecond |
cassandra.cas_commit_latency.one_minute_rate
(gauge) | The number of paxos commit round per second.
Shown as operation |
cassandra.cas_prepare_latency.75th_percentile
(gauge) | The latency of paxos prepare round - p75.
Shown as microsecond |
cassandra.cas_prepare_latency.95th_percentile
(gauge) | The latency of paxos prepare round - p95.
Shown as microsecond |
cassandra.cas_prepare_latency.one_minute_rate
(gauge) | The number of paxos prepare round per second.
Shown as operation |
cassandra.cas_propose_latency.75th_percentile
(gauge) | The latency of paxos propose round - p75.
Shown as microsecond |
cassandra.cas_propose_latency.95th_percentile
(gauge) | The latency of paxos propose round - p95.
Shown as microsecond |
cassandra.cas_propose_latency.one_minute_rate
(gauge) | The number of paxos propose round per second.
Shown as operation |
cassandra.col_update_time_delta_histogram.75th_percentile
(gauge) | The column update time delta - p75.
Shown as microsecond |
cassandra.col_update_time_delta_histogram.95th_percentile
(gauge) | The column update time delta - p95.
Shown as microsecond |
cassandra.col_update_time_delta_histogram.min
(gauge) | The column update time delta - min.
Shown as microsecond |
cassandra.compaction_bytes_written.count
(gauge) | The amount of data that was compacted since (re)start.
Shown as byte |
cassandra.compression_ratio
(gauge) | The compression ratio for all SSTables. /!\ A low value means a high compression contrary to what the name suggests. Formula used is: ‘size of the compressed SSTable / size of original’
Shown as fraction |
cassandra.currently_blocked_tasks
(gauge) | The number of currently blocked tasks for the thread pool.
Shown as task |
cassandra.currently_blocked_tasks.count
(gauge) | The number of currently blocked tasks for the thread pool.
Shown as task |
cassandra.db.droppable_tombstone_ratio
(gauge) | The estimate of the droppable tombstone ratio.
Shown as fraction |
cassandra.dropped.one_minute_rate
(gauge) | The tasks dropped during execution for the thread pool.
Shown as thread |
cassandra.exceptions.count
(gauge) | The number of exceptions thrown from ‘Storage’ metrics.
Shown as error |
cassandra.key_cache_hit_rate
(gauge) | The key cache hit rate.
Shown as fraction |
cassandra.latency.75th_percentile
(gauge) | The client request latency - p75.
Shown as microsecond |
cassandra.latency.95th_percentile
(gauge) | The client request latency - p95.
Shown as microsecond |
cassandra.latency.one_minute_rate
(gauge) | The number of client requests.
Shown as request |
cassandra.live_disk_space_used.count
(gauge) | The disk space used by “live” SSTables (only counts in use files).
Shown as byte |
cassandra.live_ss_table_count
(gauge) | Number of “live” (in use) SSTables.
Shown as file |
cassandra.load.count
(gauge) | The disk space used by live data on a node.
Shown as byte |
cassandra.max_partition_size
(gauge) | The size of the largest compacted partition.
Shown as byte |
cassandra.max_row_size
(gauge) | The size of the largest compacted row.
Shown as byte |
cassandra.mean_partition_size
(gauge) | The average size of compacted partition.
Shown as byte |
cassandra.mean_row_size
(gauge) | The average size of compacted rows.
Shown as byte |
cassandra.net.down_endpoint_count
(gauge) | The number of unhealthy nodes in the cluster. They represent each individual node’s view of the cluster and thus should not be summed across reporting nodes.
Shown as node |
cassandra.net.up_endpoint_count
(gauge) | The number of healthy nodes in the cluster. They represent each individual node’s view of the cluster and thus should not be summed across reporting nodes.
Shown as node |
cassandra.pending_compactions
(gauge) | The number of pending compactions.
Shown as task |
cassandra.pending_flushes.count
(gauge) | The number of pending flushes.
Shown as flush |
cassandra.pending_tasks
(gauge) | The number of pending tasks for the thread pool.
Shown as task |
cassandra.range_latency.75th_percentile
(gauge) | The local range request latency - p75.
Shown as microsecond |
cassandra.range_latency.95th_percentile
(gauge) | The local range request latency - p95.
Shown as microsecond |
cassandra.range_latency.one_minute_rate
(gauge) | The number of local range requests.
Shown as request |
cassandra.read_latency.75th_percentile
(gauge) | The local read latency - p75.
Shown as microsecond |
cassandra.read_latency.95th_percentile
(gauge) | The local read latency - p95.
Shown as microsecond |
cassandra.read_latency.99th_percentile
(gauge) | The local read latency - p99.
Shown as microsecond |
cassandra.read_latency.one_minute_rate
(gauge) | The number of local read requests.
Shown as read |
cassandra.row_cache_hit.count
(gauge) | The number of row cache hits.
Shown as hit |
cassandra.row_cache_hit_out_of_range.count
(gauge) | The number of row cache hits that do not satisfy the query filter and went to disk.
Shown as hit |
cassandra.row_cache_miss.count
(gauge) | The number of table row cache misses.
Shown as miss |
cassandra.snapshots_size
(gauge) | The disk space truly used by snapshots.
Shown as byte |
cassandra.ss_tables_per_read_histogram.75th_percentile
(gauge) | The number of SSTable data files accessed per read - p75.
Shown as file |
cassandra.ss_tables_per_read_histogram.95th_percentile
(gauge) | The number of SSTable data files accessed per read - p95.
Shown as file |
cassandra.timeouts.count
(gauge) | Count of requests not acknowledged within configurable timeout window.
Shown as timeout |
cassandra.timeouts.one_minute_rate
(gauge) | Recent timeout rate, as an exponentially weighted moving average over a one-minute interval.
Shown as timeout |
cassandra.tombstone_scanned_histogram.75th_percentile
(gauge) | Number of tombstones scanned per read - p75.
Shown as record |
cassandra.tombstone_scanned_histogram.95th_percentile
(gauge) | Number of tombstones scanned per read - p95.
Shown as record |
cassandra.total_blocked_tasks
(gauge) | Total blocked tasks
Shown as task |
cassandra.total_blocked_tasks.count
(count) | Total count of blocked tasks
Shown as task |
cassandra.total_commit_log_size
(gauge) | The size used on disk by commit logs.
Shown as byte |
cassandra.total_disk_space_used.count
(gauge) | Total disk space used by SSTables including obsolete ones waiting to be GC’d.
Shown as byte |
cassandra.view_lock_acquire_time.75th_percentile
(gauge) | The time taken acquiring a partition lock for materialized view updates - p75.
Shown as microsecond |
cassandra.view_lock_acquire_time.95th_percentile
(gauge) | The time taken acquiring a partition lock for materialized view updates - p95.
Shown as microsecond |
cassandra.view_lock_acquire_time.one_minute_rate
(gauge) | The number of requests to acquire a partition lock for materialized view updates.
Shown as request |
cassandra.view_read_time.75th_percentile
(gauge) | The time taken during the local read of a materialized view update - p75.
Shown as microsecond |
cassandra.view_read_time.95th_percentile
(gauge) | The time taken during the local read of a materialized view update - p95.
Shown as microsecond |
cassandra.view_read_time.one_minute_rate
(gauge) | The number of local reads for materialized view updates.
Shown as request |
cassandra.waiting_on_free_memtable_space.75th_percentile
(gauge) | The time spent waiting for free memtable space either on- or off-heap - p75.
Shown as microsecond |
cassandra.waiting_on_free_memtable_space.95th_percentile
(gauge) | The time spent waiting for free memtable space either on- or off-heap - p95.
Shown as microsecond |
cassandra.write_latency.75th_percentile
(gauge) | The local write latency - p75.
Shown as microsecond |
cassandra.write_latency.95th_percentile
(gauge) | The local write latency - p95.
Shown as microsecond |
cassandra.write_latency.99th_percentile
(gauge) | The local write latency - p99.
Shown as microsecond |
cassandra.write_latency.one_minute_rate
(gauge) | The number of local write requests.
Shown as write |