“
Live Processes および Live Process Monitoring は Enterprise プランに含まれています。他のプランをご利用の場合、この機能をリクエストするにはアカウント担当者または
success@datadoghq.com へご連絡ください。
"
はじめに
Datadog のライブプロセスにより、インフラストラクチャー上で実行中のプロセスをリアルタイムで可視化できます。ライブプロセスを使用すると、以下のことができます。
- 実行中のプロセスを1か所で表示する
- ホストやコンテナのリソース消費をプロセスレベルで分類します
- 特定のホストや特定のゾーンで実行中のプロセスや、特定のワークロードを実行するプロセスのクエリ
- システムメトリクスを使用して、実行する内部およびサードパーティーソフトウェアのパフォーマンスを 2 秒の粒度でモニターします
- ダッシュボードとノートブックにコンテキストを追加します
インストール
Agent 5 の場合は、こちらのバージョン固有のインストール手順に従ってください。Agent 6 または 7 をご利用の場合は、以下の手順を参照してください。
Datadog Agent をインストールしたら、Agent のメイン構成ファイルを編集し、次のパラメーターを true に設定して、ライブプロセスの収集を有効にします。
process_config:
process_collection:
enabled: true
さらに、いくつかの構成オプションを環境変数として設定できます。
注: 環境変数として設定されたオプションは、構成ファイルで定義されている設定を上書きします。
設定が完了したら、Agent を再起動します。
Docker Agent の手順に従って、必要に応じて他のカスタム設定に加えて、以下の属性を渡します。
-v /etc/passwd:/etc/passwd:ro
-e DD_PROCESS_CONFIG_PROCESS_COLLECTION_ENABLED=true
注:
- 標準インストールでコンテナ情報を収集するには、
dd-agent ユーザーが docker.sock へのアクセス許可を持つ必要があります。 - 引き続き、Agent をコンテナとして実行してホストプロセスを収集することもできます。
次のプロセスコレクション構成で datadog-values.yaml ファイルを更新します。
datadog:
# (...)
processAgent:
enabled: true
processCollection: true
次に、Helm チャートをアップグレードします。
helm upgrade -f datadog-values.yaml <RELEASE_NAME> datadog/datadog
注: 引き続き、Agent をコンテナとして実行してホストプロセスを収集することもできます。
datadog-agent.yaml で features.liveProcessCollection.enabled を true に設定します。
apiVersion: datadoghq.com/v2alpha1
kind: DatadogAgent
metadata:
name: datadog
spec:
global:
credentials:
apiKey: <DATADOG_API_KEY>
features:
liveProcessCollection:
enabled: true
After making your changes, apply the new configuration by using the following command:
kubectl apply -n $DD_NAMESPACE -f datadog-agent.yaml
注: 引き続き、Agent をコンテナとして実行してホストプロセスを収集することもできます。
DaemonSet の作成に使用された datadog-agent.yaml マニフェスト内に、以下の環境変数、ボリュームマウント、およびボリュームを追加します。
env:
- name: DD_PROCESS_CONFIG_PROCESS_COLLECTION_ENABLED
value: "true"
volumeMounts:
- name: passwd
mountPath: /etc/passwd
readOnly: true
volumes:
- hostPath:
path: /etc/passwd
name: passwd
詳細については、標準の DaemonSet インストールのページおよび Docker Agent の情報ページを参照してください。
注: 引き続き、Agent をコンテナとして実行してホストプロセスを収集することもできます。
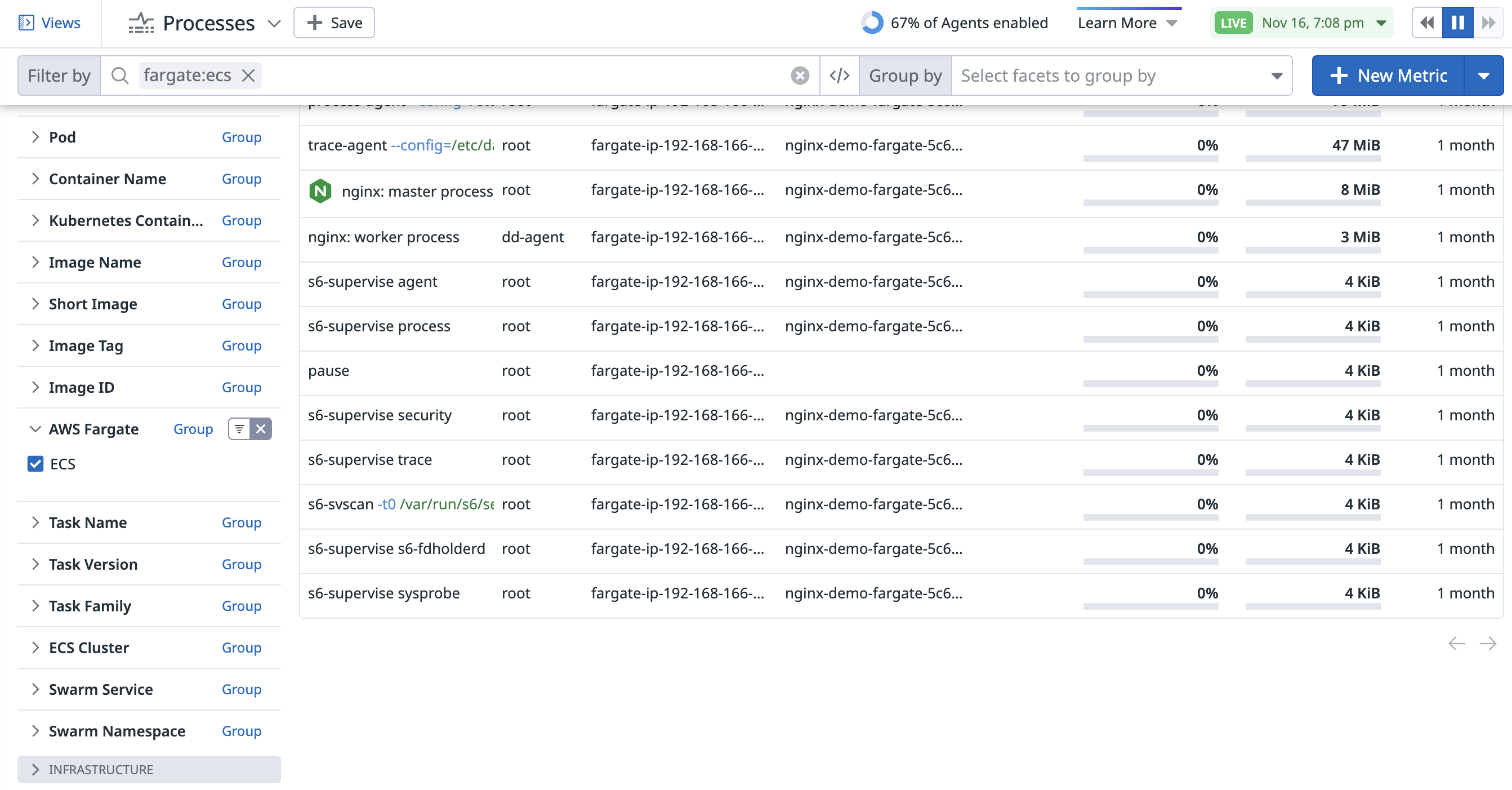
Datadog で ECS Fargate プロセスを表示できます。ECS Fargate コンテナとの関係を確認するには、Datadog Agent v7.50.0 以降を使用します。
プロセスを収集するには、Datadog Agent がタスク内でコンテナとして実行されている必要があります。
ECS Fargate でプロセスモニタリングを有効にするには、タスク定義内の Datadog Agent コンテナ定義で DD_PROCESS_AGENT_PROCESS_COLLECTION_ENABLED 環境変数を true に設定します。
例:
{
"taskDefinitionArn": "...",
"containerDefinitions": [
{
"name": "datadog-agent",
"image": "public.ecr.aws/datadog/agent:latest",
...
"environment": [
{
"name": "DD_PROCESS_AGENT_PROCESS_COLLECTION_ENABLED",
"value": "true"
}
...
]
...
}
]
...
}
ECS Fargate でプロセス情報の収集を開始するには、タスク定義に PidMode パラメータを追加し、以下のように task に設定します。
一度有効化すると、Live Processes ページで AWS Fargate Containers ファセットを使用して ECS ごとにプロセスをフィルタリングするか、検索クエリに fargate:ecs を入力して結果を絞り込めます。
AWS ECS Fargate で Datadog Agent をインストールする方法の詳細については、ECS Fargate インテグレーションのドキュメントを参照してください。
I/O 統計
I/O とオープンファイルの統計情報は、昇格した権限で実行される Datadog system-probe によって収集することができます。system-probe の process モジュールを有効にするには、次の構成を使用します。
下記のシステムプローブの構成の例をコピーします。
sudo -u dd-agent install -m 0640 /etc/datadog-agent/system-probe.yaml.example /etc/datadog-agent/system-probe.yaml
/etc/datadog-agent/system-probe.yaml を編集し、process モジュールを有効にします。
system_probe_config:
process_config:
enabled: true
Agent を再起動します。
sudo systemctl restart datadog-agent
注: システムで systemctl コマンドを利用できない場合は、代わりに次のコマンドを実行します: sudo service datadog-agent restart。
プロセス収集のフットプリント最適化
デフォルトでは、Datadog Agent はコンテナとプロセスの収集用に別の Process Agent を使用します。Linux 環境で実行している場合は、コンテナとプロセスの収集をコア Agent に統合できます。
datadog-values.yaml ファイルに runInCoreAgent 構成を追加します。
datadog:
processAgent:
runInCoreAgent: true
datadog-agent.yaml ファイルに DD_PROCESS_CONFIG_RUN_IN_CORE_AGENT_ENABLED 構成を追加します。
apiVersion: datadoghq.com/v2alpha1
kind: DatadogAgent
metadata:
name: datadog
spec:
override:
nodeAgent:
env:
- name: DD_PROCESS_CONFIG_RUN_IN_CORE_AGENT_ENABLED
value: "true"
コンテナ外で Agent を Linux 上で実行している場合は、datadog.yaml ファイルで run_in_core_agent フラグを追加します。
process_config:
run_in_core_agent:
enabled: true
プロセス引数のスクラビング
ライブプロセスページに機密データが表示されないように、Agent はプロセスコマンドラインからの機密性の高い引数をスクラビングします。この機能はデフォルトで有効になっており、以下の語のいずれかと一致するプロセス引数は、値が表示されません。
"password", "passwd", "mysql_pwd", "access_token", "auth_token", "api_key", "apikey", "secret", "credentials", "stripetoken"
注: この一致では、大文字と小文字は区別されません。
datadog.yaml ファイルの process_config セクションの下にある custom_sensitive_words フィールドを使用すると、独自のリストを定義して、デフォルトのリストと統合することができます。ワイルドカード (*) を使用して、一致の範囲を独自に定義できます。ただし、ワイルドカード ('*') 単独の使用は、機密語としてサポートされていません。
process_config:
scrub_args: true
custom_sensitive_words: ['personal_key', '*token', 'sql*', '*pass*d*']
注: custom_sensitive_words 内の語には、英数字、アンダースコア、およびワイルドカード ('*') のみを使用できます。ワイルドカードのみの機密語はサポートされていません。
次の図に、ライブプロセスページに表示されたプロセスの一例を示します。上の構成を使用して、プロセス引数が非表示にされています。
scrub_args を false に設定すると、プロセス引数のスクラビングを完全に無効化できます。
datadog.yaml 構成ファイルで strip_proc_arguments フラグを有効にすることで、プロセスのすべての引数をスクラビングすることもできます。
process_config:
strip_proc_arguments: true
Helm チャートを使い、デフォルトのリストにマージされる独自のリストを定義できます。環境変数 DD_SCRUB_ARGS と DD_CUSTOM_SENSITIVE_WORDS を datadog-values.yaml ファイルに追加し、Datadog Helm チャートをアップグレードします。
datadog:
# (...)
processAgent:
enabled: true
processCollection: true
agents:
containers:
processAgent:
env:
- name: DD_SCRUB_ARGS
value: "true"
- name: DD_CUSTOM_SENSITIVE_WORDS
value: "personal_key,*token,*token,sql*,*pass*d*"
ワイルドカード (*) を使用して、一致のスコープを独自に定義できます。ただし、ワイルドカード ('*') 単独の使用は、機密語としてサポートされていません。
DD_SCRUB_ARGS を false に設定すると、プロセス引数のスクラビングを完全に無効化できます。
また、datadog-values.yaml ファイルで DD_STRIP_PROCESS_ARGS 変数を有効にすることで、プロセスのすべての引数をスクラビングすることもできます。
datadog:
# (...)
processAgent:
enabled: true
processCollection: true
agents:
containers:
processAgent:
env:
- name: DD_STRIP_PROCESS_ARGS
value: "true"
クエリ
プロセスのスコーピング
プロセスは、本質的に極めてカーディナリティの高いオブジェクトです。関連するプロセスを表示するようにスコープを絞り込むには、テキストフィルターやタグフィルターを使用します。
テキストフィルター
検索バーにテキスト文字列を入力すると、コマンドラインやパスにそのテキスト文字列を含むプロセスの照会に、あいまい検索が使用されます。2 文字以上の文字列を入力すると結果が表示されます。下の例では、Datadog のデモ環境を文字列 postgres /9. でフィルタリングしています。
注: /9. はコマンドパスの一部と一致し、postgres はコマンド自体と一致しています。
複合クエリで複数の文字列検索を組み合わせるには、以下のブール演算子を使用します。
AND- 積: 両方の条件を含むイベントが選択されます(何も追加しなければ、AND がデフォルトです)。
例: java AND elasticsearch OR- 和: いずれかの条件を含むイベントが選択されます。
例: java OR python NOT / !- 排他: 後続の条件はイベントに含まれません。単語
NOT または文字 ! のどちらを使用しても、同じ演算を行うことができます。
例: java NOT elasticsearch または java !elasticsearch
演算子をグループ化するには括弧を使用します。例: (NOT (elasticsearch OR kafka) java) OR python。
タグフィルター
プロセスのフィルタリングには、host、pod、user、service などの Datadog タグを使用することもできます。検索バーに直接タグフィルターを入力するか、ページ左側のファセットパネルで選択します。
Datadog は自動的に command タグを生成するので、以下をフィルタリングできます。
- サードパーティソフトウェア、例:
command:mongod、command:nginx - コンテナ管理ソフトウェア、例:
command:docker、command:kubelet - 一般的なワークロード、例、
command:ssh、command:CRON
プロセスの集約
タグ付けはナビゲーションを強化します。すべての既存のホストレベルのタグに加えて、プロセスは user でもタグ付けされます。
さらに、ECS コンテナ内のプロセスは、以下でもタグ付けされます。
task_nametask_versionecs_cluster
Kubernetes コンテナ内のプロセスは、以下でタグ付けされます。
pod_namekube_pod_ipkube_servicekube_namespacekube_replica_setkube_daemon_setkube_jobkube_deploymentKube_cluster
統合サービスタグ付けのコンフィギュレーションがある場合、env、service、version も自動的に取得されます。
上記のタグが利用できることで、APM、ログ、メトリクス、プロセスデータを結びつけることができます。
注: このセットアップはコンテナ化環境にのみ適用されます。
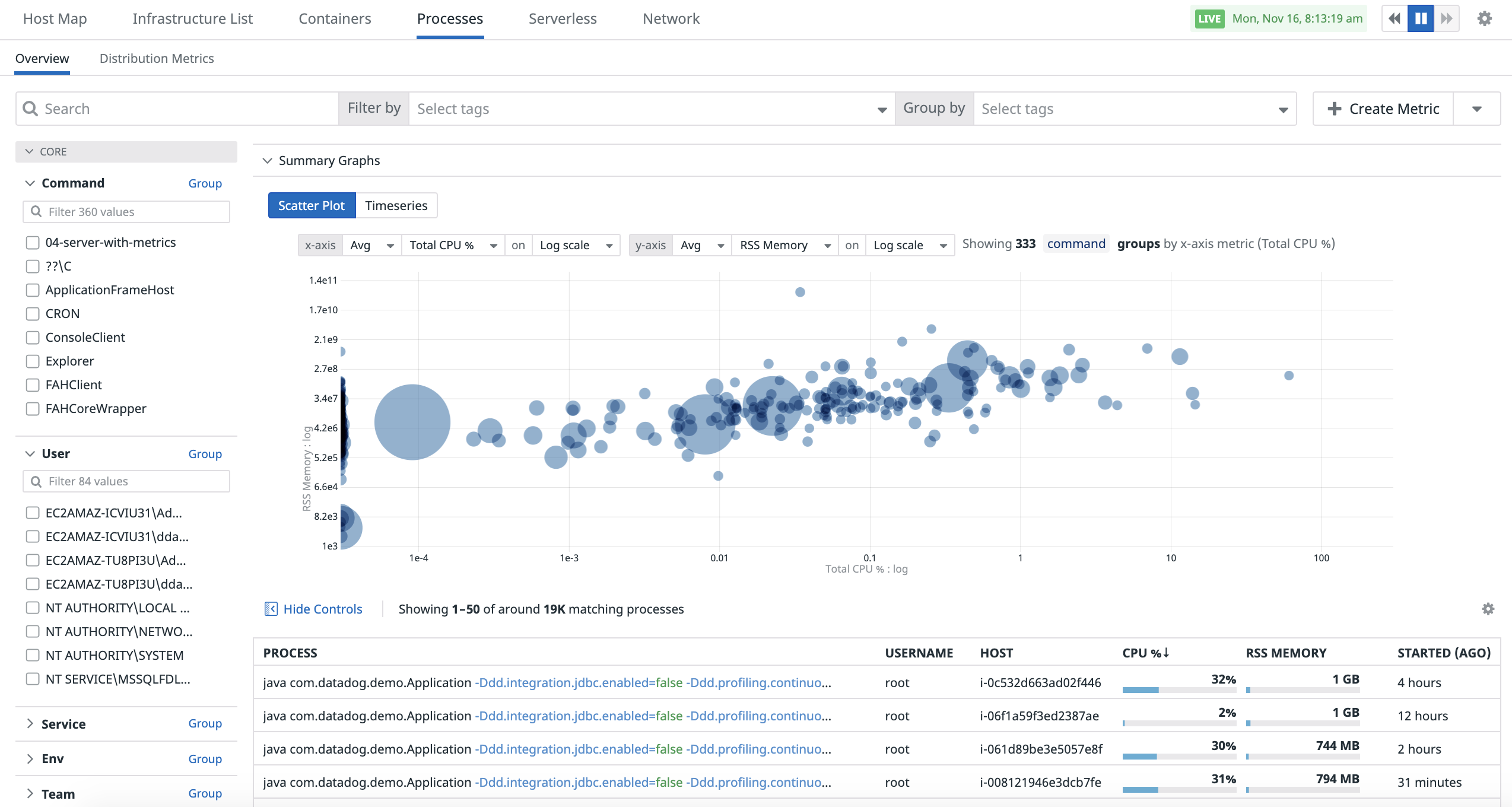
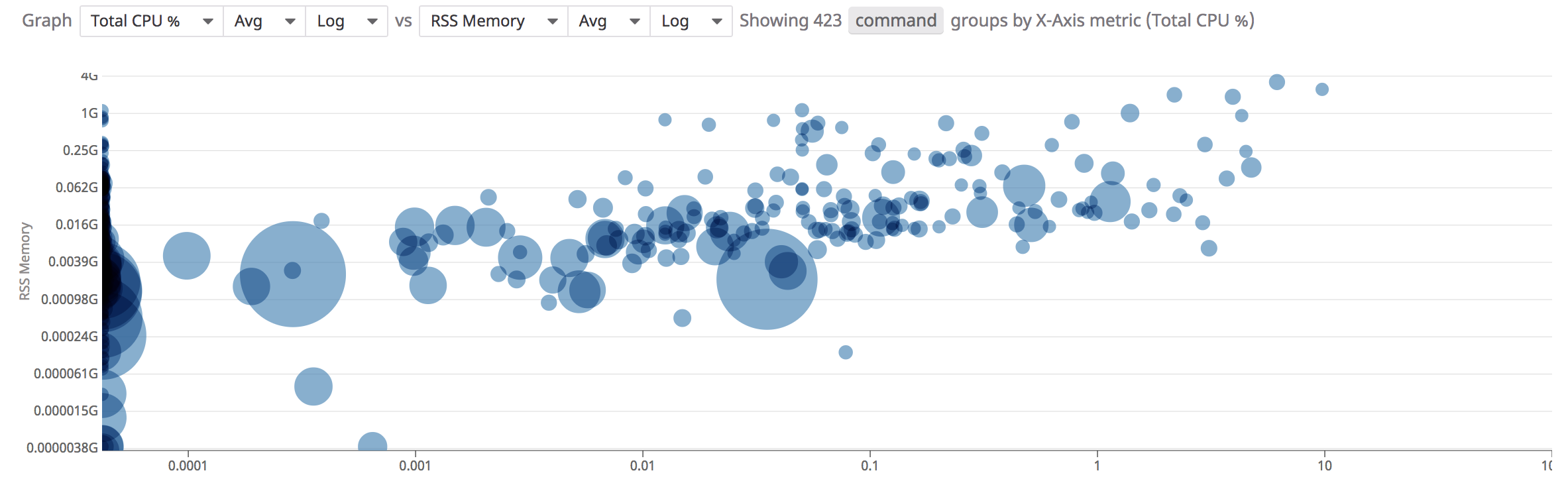
散布図
散布図分析を使用すると、2 つのメトリクスを比較してコンテナのパフォーマンスをより的確に把握できます。
Processes ページで散布図分析にアクセスするには、Show Summary graph ボタンをクリックし、“Scatter Plot” タブを選択します。
デフォルトでは、グラフは command タグキーでグループ化されます。ドットのサイズは、各グループ内のプロセスの数を表します。ドットをクリックすると、グループに参加しているすべてのポッドとコンテナが表示されます。
散布図分析の上部にあるクエリを使用して、散布図分析を制御できます。
- 表示するメトリクスの選択。
- 2 つのメトリクスの集計方法の選択。
- X 軸と Y 軸の目盛の選択 (Linear/Log)。
プロセスモニター
複数のホストまたはタグにまたがるプロセスグループのカウントに基づいてアラートを生成するには、ライブプロセスモニターを使用します。プロセスアラートは、モニターページで構成できます。詳細は、ライブプロセスモニターのドキュメントを参照してください。
ダッシュボードおよびノートブックでのプロセス
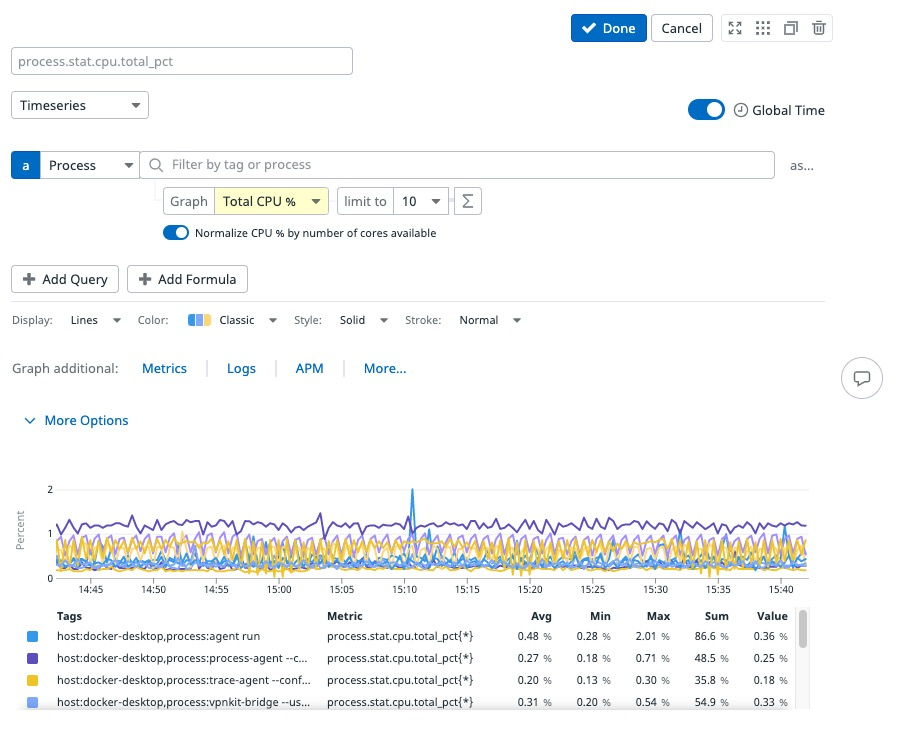
ダッシュボードやノートブックでプロセスメトリクスをグラフ化するには、時系列ウィジェットを使用します。構成するには、
- プロセスをデータソースとして選択
- 検索バーのテキスト文字列を使用してフィルタリング
- グラフ化するプロセスメトリクスを選択
From フィールドのタグを使用してフィルタリング
サードパーティソフトウェアをモニタリング
自動検出インテグレーション
Datadog ではプロセス収集を使用して、ホストで実行されているテクノロジーを自動検出します。これにより、こうしたテクノロジーの監視に役立つ Datadog インテグレーションが識別されます。この自動検出されたインテグレーションは、インテグレーション検索に表示されます。
各インテグレーションには、次の 2 つのステータスタイプのいずれかがあります。
- + Detected: このインテグレーションは、それを実行しているホストでは有効になっていません。
- ✓ Partial Visibility: このインテグレーションは、一部で有効になっていますが、すべての関連ホストで実行されているわけではありません。
インテグレーションを実行しているが、インテグレーションが有効になっていないホストは、インテグレーションタイルの Hosts タブにあります。
インテグレーションビュー
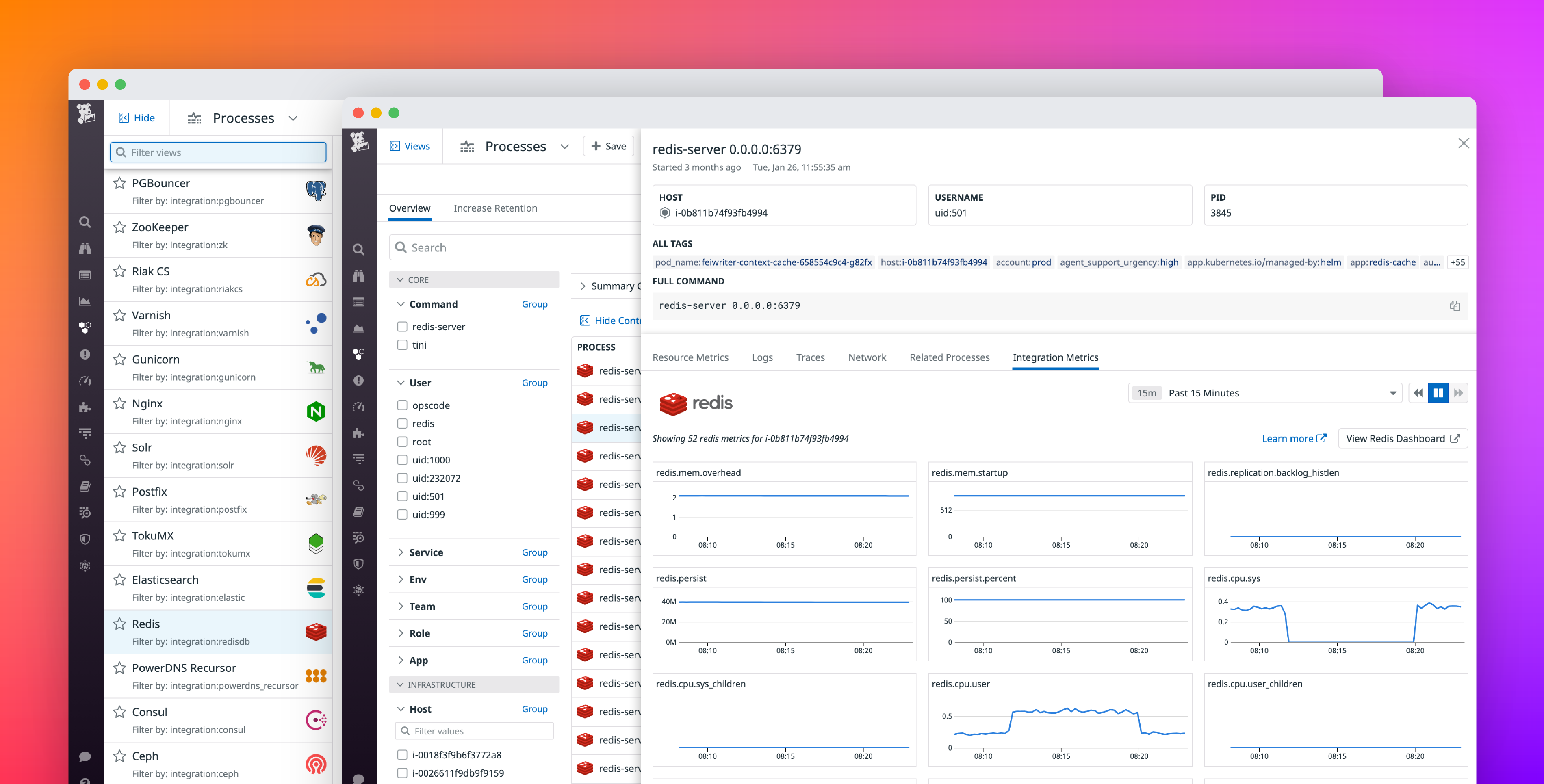
サードパーティ製ソフトウェアが検出された後、ライブプロセスはそのソフトウェアのパフォーマンスを分析するのに役立ちます。
- まず、ページ右上の Views をクリックし、Nginx、Redis、Kafka などの予め設定されたオプションの一覧を開きます。
- そのソフトウェアを実行中の処理のみにページのスコープを設定するビューを選択します。
- 重いプロセスを検査する際は、Integration Metrics タブに切り替え、基底のホストにあるソフトウェアの健全性を分析します。関連する Datadog インテグレーションを有効にしてある場合は、インテグレーションから収集されたすべてのパフォーマンスメトリクスを表示できるため、問題がホストレベルなのかソフトウェアレベルなのかを判断できます。たとえば、プロセス CPU と MySQL クエリのレイテンシーが相関して急上昇する場合、全表スキャンなどの集中的な操作が、同じ基底のリソースに依存する別の MySQL クエリの実行を遅らせていることが考えられます。
インテグレーションビュー(ホストごとに Nginx 処理のクエリを集約する場合)や他のカスタムクエリをカスタマイズするには、ページ上部の +Save ボタンをクリックします。この操作により、クエリ、テーブルの列の選択、可視化設定が保存されます。保存ビューを作成し、追加のコンフィギュレーション無しに必要な処理へ迅速にアクセスへしたり、チームメイトとプロセスデータを共有したりできます。
プラットフォームにおけるプロセス
ライブコンテナ
ライブプロセスは、それぞれのコンテナで実行中のプロセスを監視することで、コンテナデプロイの可視化をさらに強化しています。ライブコンテナページでコンテナをクリックすると、実行中のコマンドやリソース消費量を含むプロセスツリーが表示されます。コンテナメトリクスと共にこのデータを使用し、コンテナやデプロイの不具合の根本的な原因を探ります。
APM
APM トレースでサービスのスパンをクリックすると、基礎インフラストラクチャーで実行中のプロセスを確認できます。サービスのスパンプロセスは、リクエスト時にサービスが実行されているホストまたはポッドと相関関係にあります。CPU および RSS メモリなどのプロセスメトリクスをコードレベルのエラーとともに分析することで、アプリケーション特有の問題かインフラストラクチャーの問題かを見分けることができます。プロセスをクリックすると、ライブプロセス ページが開きます。関連するプロセスはサーバーレスおよびブラウザのトレースでサポートされていません。
Cloud Network Monitoring
Network Analytics ページで依存関係を調べる際、相互に通信するエンドポイント (サービスなど) の基底のインフラストラクチャーで実行される処理を確認できます。プロセスメタデータを使用して、ネットワークの接続の悪さ (TCP の再送信数が多いことから) やネットワークの呼び出し遅延の高さ (TCP ラウンドトリップタイムが長いことから) の原因が、エンドポイントのリソースを消費する重いワークロードであり、結果、通信の健全性や効率性に影響を与えているかを判断できます。
リアルタイムの監視
通常、プロセスは 10 秒間隔で収集されます。Live Processes ページをアクティブに操作している間は、CPU などの変動が大きいメトリクスをリアルタイムで確認できるよう、2 秒間隔で収集され、リアルタイムで表示されます。ただし、履歴としての文脈では、デフォルトの 10 秒間隔でメトリクスが取り込まれます。
追加情報
- リアルタイム (2 秒) データ収集は 30 分後にオフになります。リアルタイム収集を再開するには、ページをリフレッシュします。
- コンテナのデプロイで、各プロセスのユーザー名を収集するには、
docker-dd-agent にマウントされた /etc/passwd ファイルが必要です。これは公開ファイルですが、プロセス Agent はユーザー名以外のフィールドを使用しません。user メタデータフィールド以外のすべての機能は、このファイルにアクセスせずに機能します。注: ライブプロセスは、ホストの passwd ファイルのみを使用し、コンテナ内に作成されたユーザーのユーザー名解決は実行しません。
その他の参考資料