This product is not supported for your selected
Datadog site. (
).
Data Jobs Monitoring は、データ処理ジョブおよびその基盤となるインフラストラクチャーのパフォーマンス、信頼性、コスト効率に関する可視化を提供します。Data Jobs Monitoring を使用すると、次のことが可能になります。
- アカウントとワークスペース全体のデータ処理ジョブの健全性とパフォーマンスを追跡する。計算リソースを最も消費しているジョブや非効率なジョブを確認する。
- ジョブが失敗した場合、またはジョブの完了に予想以上に時間がかかる場合にアラートを受け取る。
- ジョブ実行の詳細とスタックトレースを分析する。
- インフラストラクチャーメトリクス、Spark UI からの Spark メトリクス、ログ、クラスター構成を相関付ける。
- 複数の実行を比較することで、トラブルシューティングを容易にし、デプロイメント時のプロビジョニングと構成を最適化する。
セットアップ
Data Jobs Monitoring では、Amazon EMR、Databricks (AWS、Azure、Google Cloud)、Google Dataproc、Spark on Kubernetes、Apache Airflow 上で実行されるジョブのモニタリングをサポートしています。
始めるには、プラットフォームを選択し、インストール手順に従ってください。
Data Jobs Monitoring を探る
信頼性の低い非効率なジョブを簡単に特定する
クラウドアカウントとワークスペースにまたがるすべてのジョブを表示します。対応が必要な失敗したジョブを特定したり、多くの計算量を使用しているため最適化する必要がある、アイドル CPU が高いジョブを見つけたりできます。
問題のあるジョブに関するアラートを受信する
Datadog のモニターは、ジョブが失敗した場合や、完了予定時間を超過して実行している場合にアラートを送信します。インストールされているインテグレーションに特化したデータジョブを監視するには、モニターテンプレートを参照してください。
個々のジョブの分析とトラブルシューティング
ジョブをクリックすると、複数の実行の結果や、失敗した実行のエラーメッセージを確認できます。
個々の実行の分析
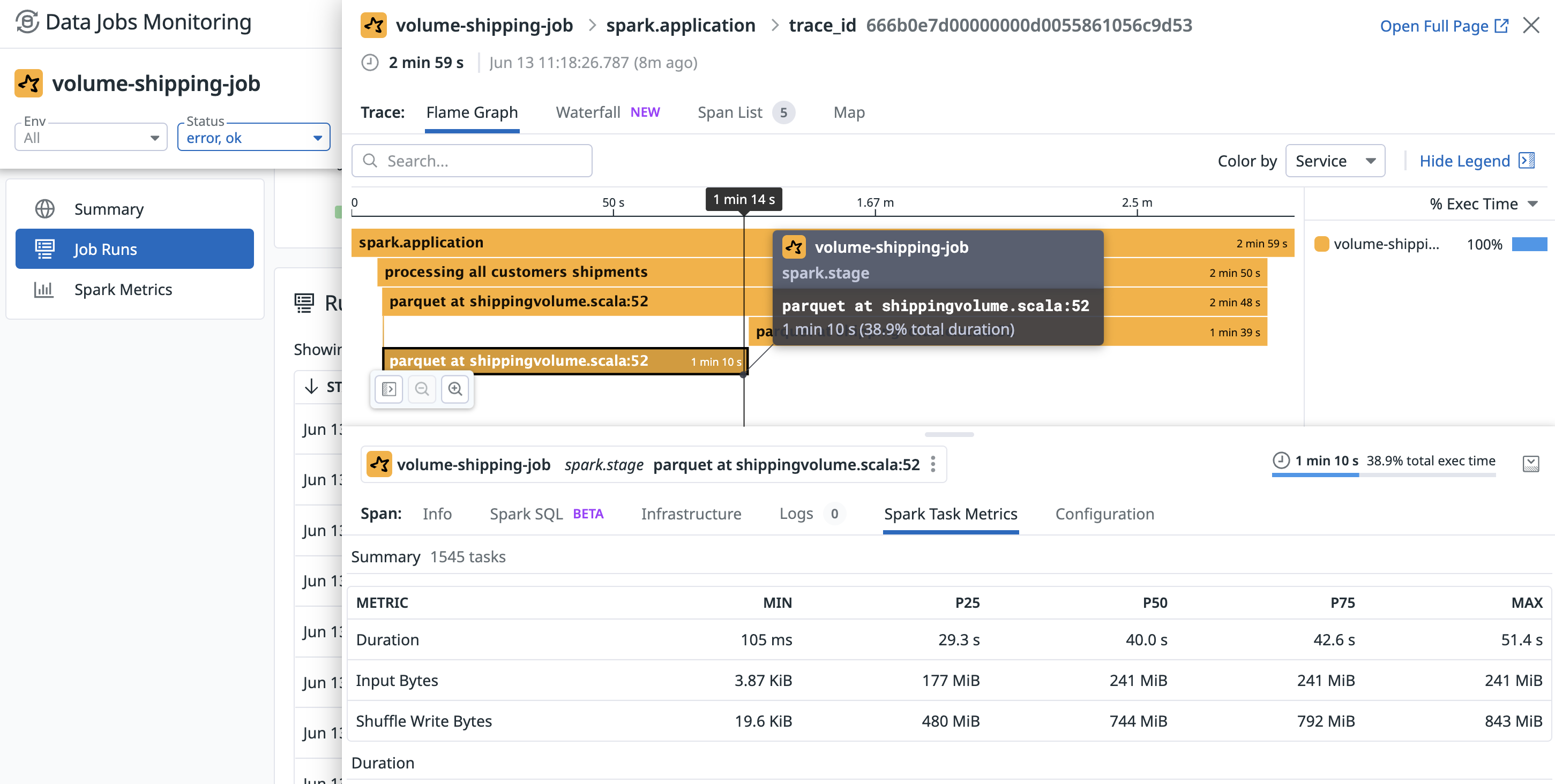
実行をクリックするとサイドパネルが開き、各 Spark ジョブとステージに費やされた時間の詳細と、アイドルエグゼキュータ CPU、入出力データ量、シャッフル、ディスク流出などのリソース消費と Spark メトリクスの内訳が表示されます。このパネルから、実行をエクゼキュータやドライバーノードのリソース使用率、ログ、ジョブやクラスターの構成と相関付けることができます。
Infrastructure タブでは、実行とインフラストラクチャーのメトリクスを相関付けることができます。
失敗した実行については、Errors タブでスタックトレースを確認します。これは、この失敗がどこでどのように発生したかを判断するのに役立ちます。
ステージの完了に長い時間がかかっている原因を特定するには、Spark Task Metrics タブを使用して、特定の Spark ステージのタスクレベルのメトリクスを表示することで、データの偏りを特定できます。異なるタスクによって費やされた時間と消費されたデータの分布を確認できます。
その他の参考資料