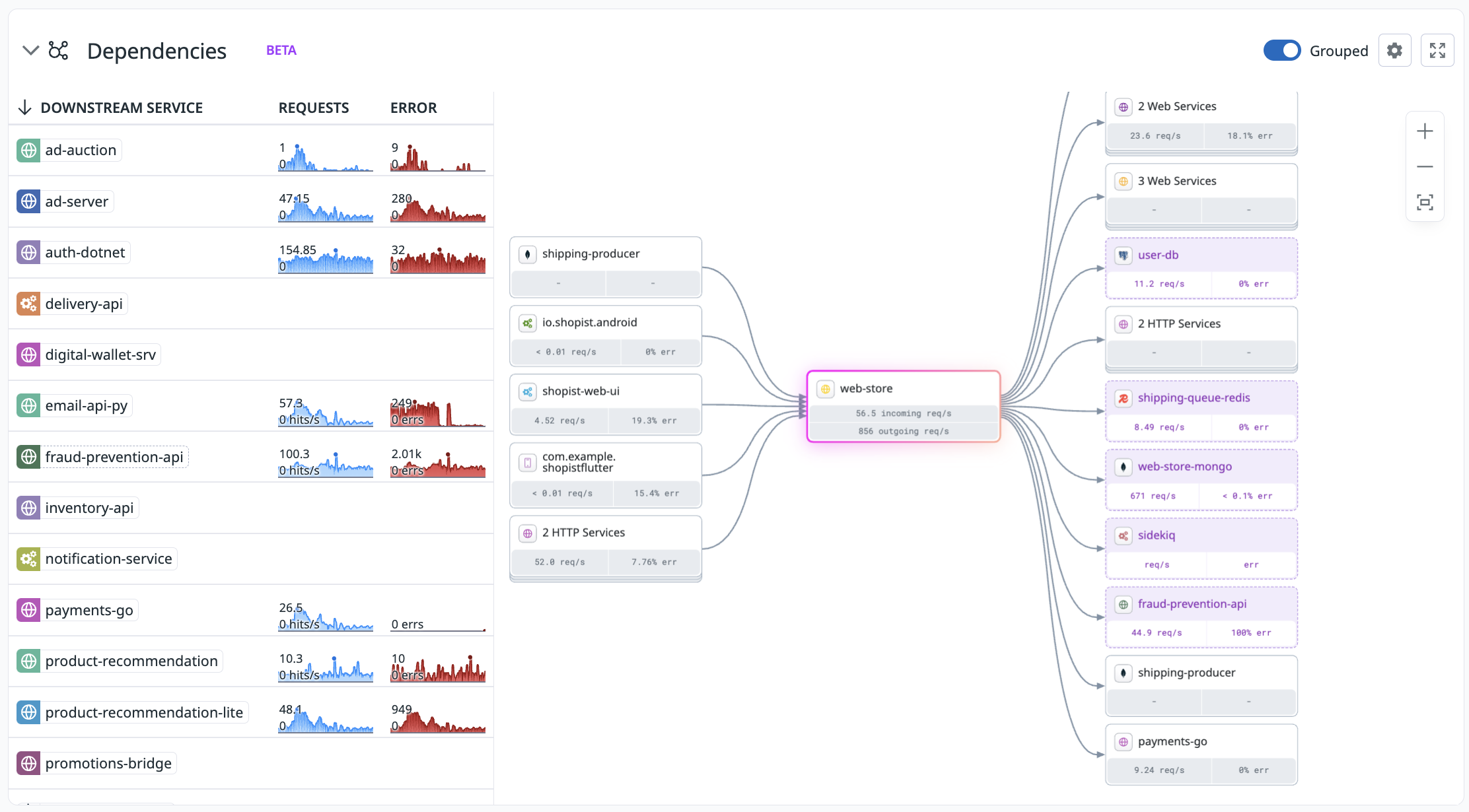
Datadog découvre automatiquement les dépendances d’un service instrumenté, telles que les bases de données, files d’attente ou API tierces, même si ces dépendances ne sont pas directement instrumentées. En analysant les requêtes sortantes des services instrumentés, Datadog déduit la présence de ces dépendances et collecte les métriques de performance associées.
Explorez les services déduits dans le Software Catalog en filtrant les entrées par type d’entité, comme une base de données, une file d’attente ou une API tierce. Chaque page des services est adaptée au type de service que vous analysez. Par exemple, les pages de services de base de données affichent des informations spécifiques à la base et incluent des données de surveillance si vous utilisez Database Monitoring.
Configurer les services déduits
À partir de la version 7.60.0 de l’Agent Datadog, aucune configuration manuelle n’est nécessaire pour visualiser les services déduits. Les options requises (apm_config.compute_stats_by_span_kind et apm_config.peer_tags_aggregation) sont activées par défaut.
Pour les versions de l’Agent Datadog allant de 7.55.1 à 7.59.1, ajoutez ce qui suit dans votre fichier de configuration datadog.yaml :
Si vous utilisez Helm, incluez ces variables d’environnement dans votre fichiervalues.yaml.
Pour OpenTelemetry Collector, la version minimale recommandée est opentelemetry-collector-contribv0.95.0 ou ultérieure. Dans ce cas, mettez à jour cette configuration :
Pour déterminer les noms et les types des dépendances de service déduites, Datadog utilise les attributs standard de span et les associe aux attributs peer.*. Par exemple, les API externes déduites utilisent le schéma de dénomination par défaut net.peer.name, comme api.stripe.com, api.twilio.com et us6.api.mailchimp.com. Les bases de données déduites utilisent le schéma de dénomination par défaut db.instance.
Remarque : les valeurs d’attribut peer qui correspondent à des adresses IP (par exemple, 127.0.0.1) sont modifiées et remplacées par blocked-ip-address afin d’éviter les données inutiles et de ne pas étiqueter les métriques avec des dimensions à forte cardinalité. En conséquence, certains services blocked-ip-address peuvent apparaître comme des dépendances en aval de vos services instrumentés.
Priorité des étiquettes peer
Pour attribuer un nom aux entités inférées, Datadog utilise un ordre de priorité spécifique entre les étiquettes peer, notamment lorsque les entités sont définies par une combinaison de plusieurs attributs.
Si l’attribut ayant la priorité la plus élevée, comme peer.db.name, n’est pas capturé par l’instrumentation, Datadog utilise l’attribut de priorité suivante (ex. peer.hostname), et ainsi de suite.
Remarque : Datadog ne définit jamais peer.service pour les bases de données et les files d’attente inférées. peer.service est l’attribut peer ayant la plus haute priorité. S’il est défini, il prévaut sur tous les autres attributs.
Migrer vers la dénomination globale par défaut des services
Avec les services inférés, les dépendances sont automatiquement détectées à partir des attributs de span existants. Il n’est donc pas nécessaire de modifier les noms de service (via le tag service) pour identifier ces dépendances.
Activez la variable DD_TRACE_REMOVE_INTEGRATION_SERVICE_NAMES_ENABLED pour vous assurer qu’aucune intégration Datadog ne définisse de noms de service différents du nom global par défaut. Cela améliore également la représentation des connexions service-à-service et des services déduits dans les visualisations Datadog, pour tous les langages et intégrations de bibliothèques de traçage pris en charge.
L'activation de cette option peut affecter les métriques APM existantes, les métriques personnalisées de span, l'analytique de trace, les filtres de rétention, les analyses de données sensibles, les monitors, les tableaux de bord ou les notebooks qui référencent les anciens noms de service. Mettez à jour ces éléments pour utiliser le tag global par défaut service:<DD_SERVICE>.