Les processeurs décrits dans cette documentation sont spécifiques aux environnements de journalisation basés sur le cloud. Pour analyser, structurer et enrichir les journaux sur site, consultez Pipelines d'observabilité.
Un processeur s’exécute au sein d’un Pipeline pour réaliser une action de structuration des données et générer des attributs pour enrichir vos journaux.
Les journaux structurés doivent être expédiés dans un format valide. Si la structure contient des caractères invalides pour l’analyse, ceux-ci doivent être supprimés au niveau de l’Agent à l’aide de la fonctionnalité mask_sequences.
En tant que meilleure pratique, il est recommandé d’utiliser au maximum 20 processeurs par pipeline.
Parseur Grok
Créez des règles grok personnalisées pour analyser le message complet ou un attribut spécifique de votre événement brut. En tant que meilleure pratique, limitez votre parseur grok à 10 règles d’analyse. Pour plus d’informations sur la syntaxe Grok et les règles de parsing, voir Parsing.
Définissez le processeur Grok sur la page Pipelines. Pour configurer les règles de parsing Grok :
Cliquez sur Analyser mes journaux pour générer automatiquement un ensemble de trois règles de parsing basées sur les journaux circulant dans le pipeline.
Remarque : Cette fonctionnalité nécessite que les journaux correspondants soient indexés et en cours de circulation. Vous pouvez temporairement désactiver ou réduire les filtres d’exclusion pour permettre à la fonctionnalité de détecter les journaux.
Exemples de journaux : Ajoutez jusqu’à cinq journaux d’exemple (jusqu’à 5000 caractères chacun) pour tester vos règles de parsing.
Définir les règles de parsing : Écrivez vos règles de parsing dans l’éditeur de règles. Au fur et à mesure que vous définissez des règles, le parseur Grok fournit une assistance syntaxique :
Suggestions de correspondance : Tapez un nom de règle suivi de %{. Un menu déroulant apparaît avec les matchers disponibles (comme word, integer, ip, date). Sélectionnez un matcher dans la liste pour l’insérer dans votre règle.
MyParsingRule %{
Suggestions de filtres : Lors de l’ajout d’un filtre avec :, un menu déroulant affiche les filtres compatibles pour le matcher sélectionné.
Testez vos règles : Sélectionnez un exemple en cliquant dessus pour déclencher son évaluation par rapport à la règle de parsing et afficher le résultat en bas de l’écran. Tous les exemples affichent un statut (match ou no match), ce qui met en évidence si l’une des règles d’analyse du parseur Grok correspond à l’exemple.
Si le processeur est activé ou non. Par défaut : false.
source
Chaîne
Oui
Nom de l’attribut de journal à analyser. Par défaut : message.
samples
Tableau de chaînes
Non
Liste de (jusqu’à 5) journaux d’exemple pour ce parseur grok.
grok.support_rules
Chaîne
Oui
Liste des règles de support pour votre parseur grok.
grok.match_rules
Chaîne
Oui
Liste des règles de correspondance pour votre parseur grok.
Remappeur de date de journal
Lorsque Datadog reçoit des journaux, il les horodate en utilisant la ou les valeurs de ces attributs par défaut :
timestamp
date
_timestamp
Timestamp
eventTime
published_date
Si vos journaux contiennent des dates dans un attribut qui ne figure pas dans cette liste, utilisez le processeur de remappage de date des journaux pour définir leur attribut de date comme l’horodatage officiel des journaux :
Si vos journaux n’ont pas d’horodatage conforme aux formats énumérés ci-dessus, utilisez le processeur grok pour extraire le temps epoch de l’horodatage vers un nouvel attribut. Le remappeur de date utilise le nouvel attribut défini.
Pour voir comment un format de date et d’heure personnalisé peut être analysé dans Datadog, consultez Analyse des dates.
Notes :
Les événements de journaux peuvent être soumis jusqu’à 18 heures dans le passé et deux heures dans le futur.
Depuis ISO 8601-1:2019, le format de base est T[hh][mm][ss] et le format étendu est T[hh]:[mm]:[ss]. Les versions antérieures omettaient le T (représentant le temps) dans les deux formats.
Si vos journaux ne contiennent aucun des attributs par défaut et que vous n’avez pas défini votre propre attribut de date, Datadog horodate les journaux avec la date à laquelle il les a reçus.
Si plusieurs processeurs de remappage de date des journaux sont appliqués à un journal donné dans le pipeline, le dernier (selon l’ordre du pipeline) est pris en compte.
Définissez le processeur de remappage de date des journaux sur la page Pipelines :
{"type":"date-remapper","name":"Define <SOURCE_ATTRIBUTE> as the official Date of the log","is_enabled":false,"sources":["<SOURCE_ATTRIBUTE_1>"]}
Paramètre
Type
Requis
Description
type
Chaîne
Oui
Type de processeur.
name
Chaîne
Non
Nom du processeur.
is_enabled
Booléen
Non
Si le processeur est activé ou non. Par défaut : false.
sources
Tableau de chaînes
Oui
Tableau des attributs source.
Processeur de remappage d’état des journaux
Utilisez le processeur de remappage d’état pour attribuer des attributs comme état officiel à vos journaux. Par exemple, ajoutez un niveau de gravité à vos journaux avec le processeur de remappage d’état.
Chaque valeur d’état entrante est mappée comme suit :
Les chaînes commençant par emerg ou f (insensible à la casse) sont mappées à emerg (0)
Les chaînes commençant par a (insensible à la casse) sont mappées à alert (1)
Les chaînes commençant par c (insensible à la casse) sont mappées à critical (2)
Les chaînes commençant par err (insensible à la casse) sont mappées à error (3)
Les chaînes commençant par w (insensible à la casse) sont mappées à warning (4)
Les chaînes commençant par n (insensible à la casse) sont mappées à notice (5)
Les chaînes commençant par i (insensible à la casse) sont mappées à info (6)
Les chaînes commençant par d, t, v, trace, ou verbose (insensible à la casse) sont mappées à debug (7)
Les chaînes commençant par o ou s, ou correspondant à OK ou Success (insensible à la casse) sont mappées à OK
Tous les autres sont mappés à info (6)
Remarque : Si plusieurs processeurs de remappage d’état des journaux sont appliqués à un journal dans un pipeline, seul le premier dans l’ordre du pipeline est pris en compte. De plus, pour tous les pipelines qui correspondent au journal, seul le premier remappeur de statut rencontré (parmi tous les pipelines applicables) est appliqué.
Définissez le processeur de remappage de statut du journal sur la page Pipelines :
Utilisez le point de terminaison de l’API de pipeline de journaux Datadog avec la charge utile JSON suivante pour le remappeur de statut du journal :
{"type":"status-remapper","name":"Define <SOURCE_ATTRIBUTE> as the official status of the log","is_enabled":true,"sources":["<SOURCE_ATTRIBUTE>"]}
Paramètre
Type
Requis
Description
type
Chaîne
Oui
Type de processeur.
name
Chaîne
Non
Nom du processeur.
is_enabled
Booléen
Non
Si le processeur est activé ou non. Par défaut : false.
sources
Tableau de chaînes
Oui
Tableau des attributs source.
Remappeur de service
Le processeur de remappeur de service attribue un ou plusieurs attributs à vos journaux en tant que service officiel.
Remarque : Si plusieurs processeurs de remappeur de service sont appliqués à un journal donné dans le pipeline, seul le premier (selon l’ordre du pipeline) est pris en compte.
Définissez le processeur de remappeur de service du journal sur la page Pipelines :
Utilisez le point de terminaison de l’API de pipeline de journaux Datadog avec la charge utile JSON suivante pour le remappeur de service du journal :
{"type":"service-remapper","name":"Define <SOURCE_ATTRIBUTE> as the official log service","is_enabled":true,"sources":["<SOURCE_ATTRIBUTE>"]}
Paramètre
Type
Requis
Description
type
Chaîne
Oui
Type de processeur.
name
Chaîne
Non
Nom du processeur.
is_enabled
Booléen
Non
Si le processeur est activé ou non. Par défaut : false.
sources
Tableau de chaînes
Oui
Tableau des attributs source.
Remappeur de message de journal
message est un attribut clé dans Datadog. Sa valeur est affichée dans la colonne Contenu de l’Explorateur de journaux pour fournir un contexte sur le journal. Vous pouvez utiliser la barre de recherche pour trouver un journal par le message du journal.
Utilisez le processeur de remappeur de message de journal pour définir un ou plusieurs attributs comme le message officiel du journal. Définissez plus d’un attribut pour les cas où les attributs pourraient ne pas exister et qu’une alternative est disponible. Par exemple, si les attributs de message définis sont attribute1, attribute2 et attribute3, et que attribute1 n’existe pas, alors attribute2 est utilisé. De même, si attribute2 n’existe pas, alors attribute3 est utilisé.
Pour définir des attributs de message, utilisez d’abord le processeur constructeur de chaînes pour créer un nouvel attribut de chaîne pour chacun des attributs que vous souhaitez utiliser. Ensuite, utilisez le remappeur de messages de journal pour remapper les attributs de chaîne en tant que message.
Remarque : Si plusieurs processeurs de remappeur de messages de journal sont appliqués à un journal donné dans le pipeline, seul le premier (selon l’ordre du pipeline) est pris en compte.
Définissez le processeur de remappeur de messages de journal sur la page Pipelines :
{"type":"message-remapper","name":"Define <SOURCE_ATTRIBUTE> as the official message of the log","is_enabled":true,"sources":["msg"]}
Paramètre
Type
Requis
Description
type
Chaîne
Oui
Type de processeur.
name
Chaîne
Non
Nom du processeur.
is_enabled
Booléen
Non
Si le processeur est activé ou non. Par défaut : false.
sources
Tableau de chaînes
Oui
Tableau d’attributs source. Par défaut : msg.
Remappeur
Le processeur de remappage remappe un ou plusieurs attribut(s) ou balises source à un attribut ou balise cible différent. Par exemple, vous pouvez remapper l’attribut user vers firstname pour normaliser les données de journal dans l’Explorateur de journaux.
Si la cible du remappeur est un attribut, le processeur peut également essayer de convertir la valeur en un nouveau type (String, Integer ou Double). Si la conversion échoue, la valeur et le type d’origine sont préservés.
Remarque : Le séparateur décimal pour les valeurs Double doit être ..
Contraintes de nommage
Les caractères : et , ne sont pas autorisés dans les noms d’attributs ou de balises cibles. De plus, les noms de balises et d’attributs doivent suivre les conventions décrites dans Attributs et aliasing.
Attributs réservés
Le processeur de remappeur ne peut pas être utilisé pour remapper les attributs réservés de Datadog.
L’attribut host ne peut pas être remappé.
Les attributs suivants nécessitent des processeurs de remappage dédiés et ne peuvent pas être remappés avec le remappeur générique. Pour remapper l’un des attributs, utilisez le remappeur ou le processeur spécialisé correspondant à la place.
message : Remappeur de message de journal
service : Remappeur de service
status : Remappeur d’état de journal
date : Remappeur de date de journal
trace_id : Remappeur de trace
span_id : Remappeur de span
Définissez le processeur de remappage sur la page Pipelines . Par exemple, remappez user en user.firstname.
{"type":"attribute-remapper","name":"Remap <SOURCE_ATTRIBUTE> to <TARGET_ATTRIBUTE>","is_enabled":true,"source_type":"attribute","sources":["<SOURCE_ATTRIBUTE>"],"target":"<TARGET_ATTRIBUTE>","target_type":"tag","target_format":"integer","preserve_source":false,"override_on_conflict":false}
Paramètre
Type
Requis
Description
type
Chaîne
Oui
Type de processeur.
name
Chaîne
Non
Nom du processeur.
is_enabled
Booléen
Non
Si le processeur est activé ou non. Par défaut : false.
source_type
Chaîne
Non
Définit si les sources proviennent de journal attribute ou tag. Par défaut : attribute.
sources
Tableau de chaînes
Oui
Tableau d’attributs ou d’étiquettes sources
target
Chaîne
Oui
Nom de l’attribut ou du tag final pour remapper les sources.
target_type
Chaîne
Non
Définit si la cible est un journal attribute ou un tag. Par défaut : attribute.
target_format
Chaîne
Non
Définit si la valeur de l’attribut doit être convertie en un autre type. Valeurs possibles : auto, string, ou integer. Par défaut : auto. Lorsqu’il est défini sur auto, aucune conversion n’est appliquée.
preserve_source
Booléen
Non
Supprimer ou préserver l’élément source remappé. Par défaut : false.
override_on_conflict
Booléen
Non
Écraser ou non l’élément cible s’il est déjà défini. Par défaut : false.
Analyseur d’URL
Le processeur d’analyse d’URL extrait les paramètres de requête et d’autres paramètres importants d’une URL. Lorsqu’il est configuré, les attributs suivants sont produits :
Définissez le processeur d’analyse d’URL sur la page Pipelines :
{"type":"url-parser","name":"Parse the URL from http.url attribute.","is_enabled":true,"sources":["http.url"],"target":"http.url_details"}
Paramètre
Type
Requis
Description
type
Chaîne
Oui
Type de processeur.
name
Chaîne
Non
Nom du processeur.
is_enabled
Booléen
Non
Si le processeur est activé ou non. Par défaut : false.
sources
Tableau de chaînes
Non
Tableau des attributs source. Par défaut : http.url.
target
Chaîne
Oui
Nom de l’attribut parent qui contient tous les détails extraits du sources. Par défaut : http.url_details.
Analyseur d’agent utilisateur
Le processeur d’agent utilisateur prend un attribut useragent et extrait le système d’exploitation, le navigateur, l’appareil et d’autres données utilisateur. Une fois configurés, les attributs suivants sont produits :
Remarque : Si vos journaux contiennent des agents utilisateurs encodés (par exemple, des journaux IIS), configurez ce processeur pour décoder l’URL avant de l’analyser.
Définissez le processeur d’agent utilisateur sur la page Pipelines :
Utilisez le point de terminaison de l’API de pipeline de journaux Datadog1 avec la charge utile JSON suivante pour le processeur d’agent utilisateur :
{"type":"user-agent-parser","name":"Parses <SOURCE_ATTRIBUTE> to extract all its User-Agent information","is_enabled":true,"sources":["http.useragent"],"target":"http.useragent_details","is_encoded":false}
Paramètre
Type
Requis
Description
type
Chaîne
Oui
Type du processeur.
name
Chaîne
Non
Nom du processeur.
is_enabled
Booléen
Non
Si le processeur est activé ou non. Par défaut : false.
sources
Tableau de chaînes
Non
Tableau des attributs source. Par défaut : http.useragent.
target
Chaîne
Oui
Nom de l’attribut parent qui contient tous les détails extraits du sources. Par défaut : http.useragent_details.
is_encoded
Booléen
Non
Définissez si l’attribut source est encodé en URL ou non. Par défaut : false.
Processeur de catégorie
Utilisez le processeur de catégorie pour ajouter un nouvel attribut (sans espaces ni caractères spéciaux dans le nom du nouvel attribut) à un journal correspondant à une requête de recherche fournie. Ensuite, utilisez des catégories pour créer des groupes pour une vue analytique (par exemple, groupes d’URL, groupes de machines, environnements et plages de temps de réponse).
Notes:
La syntaxe de la requête est celle de la barre de recherche Log Explorer. Cette requête peut être effectuée sur n’importe quel attribut ou tag de journal, qu’il soit une facette ou non. Des caractères génériques peuvent également être utilisés dans votre requête.
Une fois que le journal a correspondu à l’une des requêtes du processeur, il s’arrête. Assurez-vous qu’ils sont correctement ordonnés au cas où un journal pourrait correspondre à plusieurs requêtes.
Les noms des catégories doivent être uniques.
Une fois définies dans le processeur de catégorie, vous pouvez mapper les catégories à l’état du journal en utilisant le remappeur d’état du journal.
Définissez le processeur de catégorie sur la page Pipelines. Par exemple, pour catégoriser vos journaux d’accès web en fonction de la valeur de plage de code d’état ("OK" for a response code between 200 and 299, "Notice" for a response code between 300 and 399, ...), ajoutez ce processeur :
{"type":"category-processor","name":"Assign a custom value to the <TARGET_ATTRIBUTE> attribute","is_enabled":true,"categories":[{"filter":{"query":"<QUERY_1>"},"name":"<VALUE_TO_ASSIGN_1>"},{"filter":{"query":"<QUERY_2>"},"name":"<VALUE_TO_ASSIGN_2>"}],"target":"<TARGET_ATTRIBUTE>"}
Paramètre
Type
Requis
Description
type
Chaîne
Oui
Type du processeur.
name
Chaîne
Non
Nom du processeur.
is_enabled
Booléen
Non
Si le processeur est activé ou non. Par défaut : false
categories
Tableau d’objets
Oui
Tableau de filtres pour correspondre ou non à un journal et leur name correspondant pour attribuer une valeur personnalisée au journal.
target
Chaîne
Oui
Nom de l’attribut cible dont la valeur est définie par la catégorie correspondante.
Processeur arithmétique
Utilisez le processeur arithmétique pour ajouter un nouvel attribut (sans espaces ni caractères spéciaux dans le nom du nouvel attribut) à un journal avec le résultat de la formule fournie. Cela remappe différents attributs temporels avec différentes unités en un seul attribut, ou effectue des opérations sur des attributs au sein du même journal.
Une formule de processeur arithmétique peut utiliser des parenthèses et des opérateurs arithmétiques de base : -, +, *, /.
Par défaut, un calcul est ignoré si un attribut est manquant. Sélectionnez Remplacer l’attribut manquant par 0 pour peupler automatiquement les valeurs d’attribut manquantes avec 0 afin de garantir que le calcul est effectué.
Notes :
Un attribut peut être listé comme manquant s’il n’est pas trouvé dans les attributs du journal, ou s’il ne peut pas être converti en nombre.
Lors de l’utilisation de l’opérateur -, ajoutez des espaces autour de celui-ci car les noms d’attributs comme start-time peuvent contenir des tirets. Par exemple, la formule suivante doit inclure des espaces autour de l’opérateur - : (end-time - start-time) / 1000.
Si l’attribut cible existe déjà, il est écrasé par le résultat de la formule.
Les résultats sont arrondis à la 9ème décimale. Par exemple, si le résultat de la formule est 0.1234567891, la valeur réelle stockée pour l’attribut est 0.123456789.
Si vous devez mettre à l’échelle une unité de mesure, utilisez le filtre d’échelle.
Définissez le processeur arithmétique sur la page Pipelines :
Si le processeur est activé ou non. Par défaut : false.
expression
Chaîne
Oui
Opération arithmétique entre un ou plusieurs attributs de journal.
target
Chaîne
Oui
Nom de l’attribut qui contient le résultat de l’opération arithmétique.
Si true, cela remplace tous les attributs manquants de expression par 0, false ignore l’opération si un attribut est manquant. Par défaut : false.
Processeur de construction de chaînes
Utilisez le processeur de construction de chaînes pour ajouter un nouvel attribut (sans espaces ni caractères spéciaux) à un journal avec le résultat du modèle fourni. Cela permet d’agréger différents attributs ou chaînes brutes en un seul attribut.
Le modèle est défini à la fois par du texte brut et par des blocs avec la syntaxe %{attribute_path}.
Notes :
Ce processeur n’accepte que des attributs avec des valeurs ou un tableau de valeurs dans le bloc (voir les exemples dans la section UI ci-dessous).
Si un attribut ne peut pas être utilisé (objet ou tableau d’objets), il est remplacé par une chaîne vide ou l’ensemble de l’opération est ignoré en fonction de votre sélection.
Si un attribut cible existe déjà, il est écrasé par le résultat du modèle.
Les résultats d’un modèle ne peuvent pas dépasser 256 caractères.
Définissez le processeur de construction de chaînes sur la page Pipelines :
Avec le journal suivant, utilisez le modèle Request %{http.method} %{http.url} was answered with response %{http.status_code} pour renvoyer un résultat. Par exemple :
Request GET https://app.datadoghq.com/users was answered with response 200
Note : http est un objet et ne peut pas être utilisé dans un bloc (%{http} échoue), tandis que %{http.method}, %{http.status_code} ou %{http.url} renvoie la valeur correspondante. Les blocs peuvent être utilisés sur des tableaux de valeurs ou sur un attribut spécifique dans un tableau.
Par exemple, ajouter le bloc %{array_ids} renvoie :
123,456,789
%{array_users} ne renvoie rien car c’est une liste d’objets. Cependant, %{array_users.first_name} renvoie une liste de first_names contenue dans le tableau :
Si le processeur est activé ou non, par défaut false.
template
Chaîne
Oui
Une formule avec un ou plusieurs attributs et du texte brut.
target
Chaîne
Oui
Le nom de l’attribut qui contient le résultat du modèle.
is_replace_missing
Booléen
Non
Si true, il remplace tous les attributs manquants de template par une chaîne vide. Si false, ignore l’opération pour les attributs manquants. Par défaut: false.
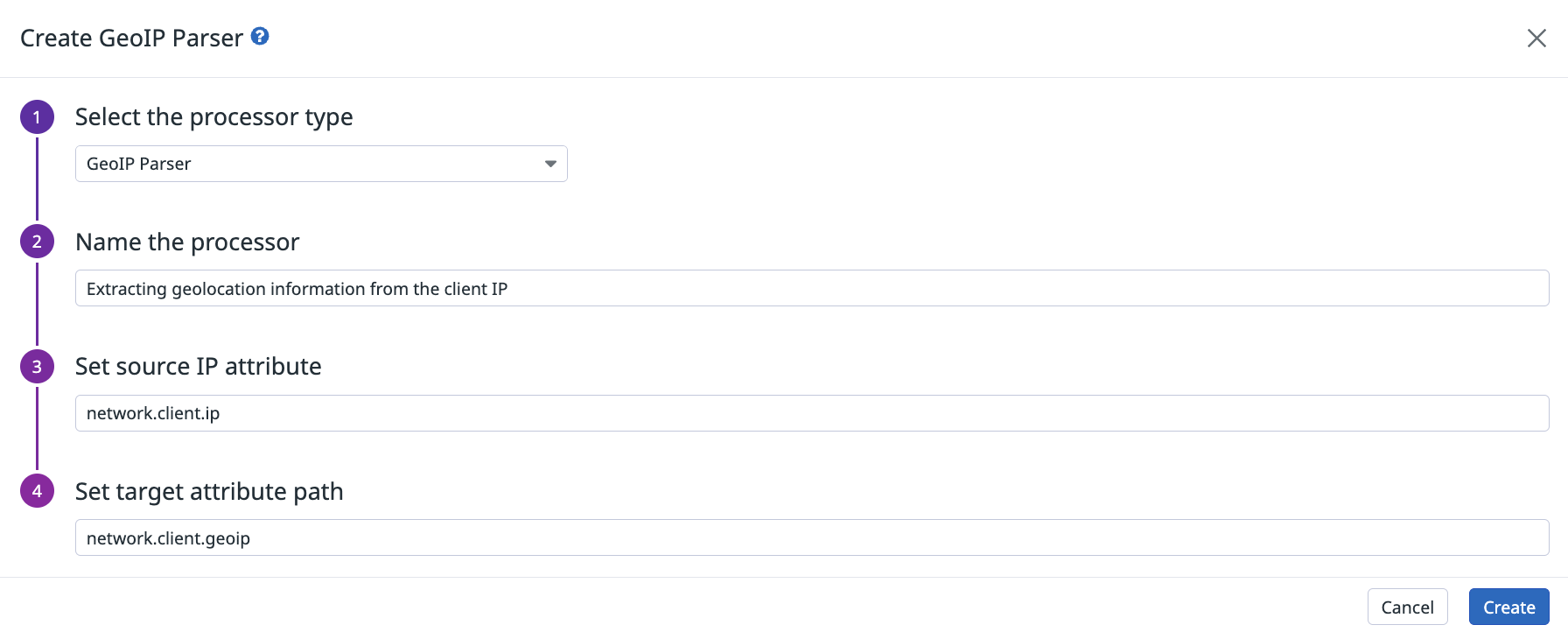
Analyseur GeoIP
L’analyseur geoIP prend un attribut d’adresse IP et extrait des informations sur le continent, le pays, la subdivision ou la ville (si disponible) dans le chemin d’attribut cible.
La plupart des éléments contiennent un attribut name et iso_code (ou code pour le continent). subdivision est le premier niveau de subdivision que le pays utilise, comme “États” pour les États-Unis ou “Départements” pour la France.
Par exemple, l’analyseur GeoIP extrait la localisation de l’attribut network.client.ip et la stocke dans l’attribut network.client.geoip :
Utilisez le point de terminaison de l’API Datadog Log Pipeline avec la charge utile JSON de l’analyseur GeoIP suivante :
{"type":"geo-ip-parser","name":"Parse the geolocation elements from network.client.ip attribute.","is_enabled":true,"sources":["network.client.ip"],"target":"network.client.geoip"}
Paramètre
Type
Requis
Description
type
Chaîne
Oui
Type de processeur.
name
Chaîne
Non
Nom du processeur.
is_enabled
Booléen
Non
Si le processeur est activé ou non. Par défaut: false.
sources
Tableau de chaînes
Non
Tableau des attributs source. Par défaut: network.client.ip.
target
Chaîne
Oui
Nom de l’attribut parent qui contient tous les détails extraits du sources. Par défaut: network.client.geoip.
##Processeur de recherche
Utilisez le processeur de recherche pour définir une correspondance entre un attribut de journal et une valeur lisible par un humain enregistrée dans une Table de Référence ou la table de correspondance des processeurs.
Par exemple, vous pouvez utiliser le processeur de recherche pour associer un ID de service interne à un nom de service lisible par un humain. Alternativement, vous pouvez l’utiliser pour vérifier si l’adresse MAC qui vient d’essayer de se connecter à l’environnement de production appartient à votre liste de machines volées.
Le processeur de recherche effectue les actions suivantes :
Vérifie si le journal actuel contient l’attribut source.
Vérifie si la valeur de l’attribut source existe dans la table de correspondance.
Si c’est le cas, crée l’attribut cible avec la valeur correspondante dans la table.
En option, s’il ne trouve pas la valeur dans la table de correspondance, il crée un attribut cible avec la valeur de secours par défaut définie dans le champ fallbackValue. Vous pouvez entrer manuellement une liste de source_key,target_value paires ou télécharger un fichier CSV dans l’onglet Manual Mapping.
The size limit for the mapping table is 100Kb. This limit applies across all Lookup Processors on the platform. However, Reference Tables support larger file sizes.
En option, s’il ne trouve pas la valeur dans la table de correspondance, il crée un attribut cible avec la valeur de la table de référence. Vous pouvez sélectionner une valeur pour une Table de Référence dans l’onglet Table de Référence.
Si le processeur est activé ou non. Par défaut : false.
source
Chaîne
Oui
Attribut source utilisé pour effectuer la recherche.
target
Chaîne
Oui
Nom de l’attribut qui contient la valeur correspondante dans la liste de correspondance ou le default_lookup si non trouvé dans la liste de correspondance.
lookup_table
Tableau de chaînes
Oui
Table de correspondance des valeurs pour l’attribut source et leurs valeurs d’attribut cible associées, formatées comme [ “source_key1,valeur_cible1”, “source_key2,valeur_cible2” ].
default_lookup
Chaîne
Non
Valeur à définir pour l’attribut cible si la valeur source n’est pas trouvée dans la liste.
Remappeur de trace
Il existe deux façons de définir la corrélation entre les traces d’application et les journaux :
Utilisez le processeur de remappage de trace pour définir un attribut de journal comme son ID de trace associé.
Définissez le processeur de remappage de trace sur la page Pipelines. Entrez le chemin de l’attribut ID de trace dans la tuile du processeur comme suit :
{"type":"trace-id-remapper","name":"Define dd.trace_id as the official trace id associate to this log","is_enabled":true,"sources":["dd.trace_id"]}
Paramètre
Type
Requis
Description
type
Chaîne
Oui
Type du processeur.
name
Chaîne
Non
Nom du processeur.
is_enabled
Booléen
Non
Si le processeur est activé ou non. Par défaut : false.
sources
Tableau de chaînes
Non
Tableau des attributs source. Par défaut : dd.trace_id.
Remarque : Les identifiants de trace et les identifiants de span ne sont pas affichés dans vos journaux ou attributs de journal dans l’interface utilisateur.
Span remapper
Il existe deux façons de définir la corrélation entre les spans d’application et les journaux :
Utilisez le processeur de remappage de span pour définir un attribut de journal comme son identifiant de span associé.
Définissez le processeur de remappage de span sur la page Pipelines. Entrez le chemin de l’attribut d’identifiant de span dans le bloc du processeur comme suit :
{"type":"span-id-remapper","name":"Define dd.span_id as the official span id associate to this log","is_enabled":true,"sources":["dd.span_id"]}
Paramètre
Type
Requis
Description
type
Chaîne
Oui
Type du processeur.
name
Chaîne
Non
Nom du processeur.
is_enabled
Booléen
Non
Indique si le processeur est activé. Par défaut : false.
sources
Tableau de chaînes
Non
Tableau des attributs source. Par défaut : dd.trace_id.
Remarque : Les identifiants de trace et les identifiants de span ne sont pas affichés dans vos journaux ou attributs de journal dans l’interface utilisateur.
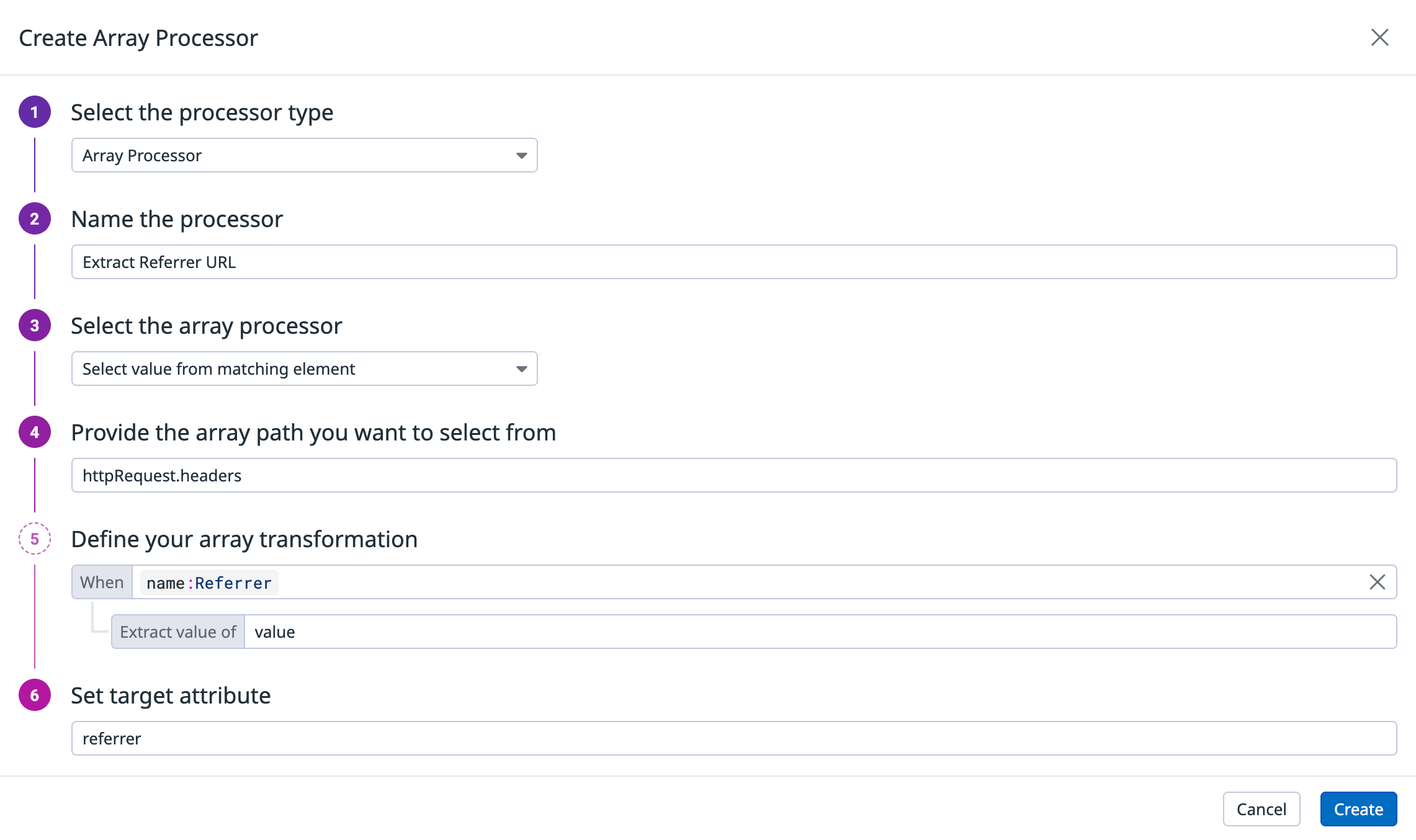
Processeur de tableau
Utilisez le processeur de tableau pour extraire, agréger ou transformer des valeurs à partir des tableaux JSON dans vos journaux.
Les opérations prises en charge incluent :
Sélectionner la valeur d’un élément correspondant
Calculer la longueur d’un tableau
Ajouter une valeur à un tableau
Chaque opération est configurée via un processeur dédié.
Définissez le processeur de tableau sur la page Pipelines.
Sélectionner la valeur d’un élément correspondant
Extraire une valeur spécifique d’un objet à l’intérieur d’un tableau lorsqu’il correspond à une condition.
{"type":"array-processor","name":"Append client IP to sourceIps","is_enabled":true,"operation":{"type":"append","source":"network.client.ip","target":"sourceIps"}}
Paramètre
Type
Requis
Description
type
Chaîne
Oui
Type du processeur.
name
Chaîne
Non
Nom du processeur.
is_enabled
Booléen
Non
Indique si le processeur est activé. Par défaut : false.
operation.type
Chaîne
Oui
Type d’opération du processeur de tableau.
operation.source
Chaîne
Oui
Attribut à ajouter.
operation.target
Chaîne
Oui
Attribut de tableau auquel ajouter.
operation.preserve_source
Booléen
Non
Indique s’il faut préserver la source originale après le remappage. Par défaut : false.
Processeur décodeur
Le processeur décodeur traduit les champs de chaînes encodées en binaire-à-texte (comme Base64 ou Hex/Base16) dans leur représentation originale. Cela permet d’interpréter les données dans leur contexte natif, que ce soit en tant que chaîne UTF-8, commande ASCII ou valeur numérique (par exemple, un entier dérivé d’une chaîne hexadécimale). Le processeur décodeur est particulièrement utile pour analyser des commandes encodées, des journaux de systèmes spécifiques ou des techniques d’évasion utilisées par des acteurs malveillants.
Notes :
Chaînes tronquées : Le processeur gère les chaînes Base64/Base16 partiellement tronquées avec soin en les coupant ou en les complétant si nécessaire.
Format hexadécimal : L’entrée hexadécimale peut être décodée en une chaîne (UTF-8) ou un entier.
Gestion des erreurs : Si le décodage échoue (en raison d’une entrée invalide), le processeur ignore la transformation, et le journal reste inchangé.
Définir l’attribut source : Fournir le chemin de l’attribut contenant la chaîne encodée, comme encoded.base64.
Sélectionner l’encodage source : Choisir l’encodage binaire-à-texte de la source : base64 ou base16/hex.
Pour Base16/Hex : Choisissez le format de sortie : string (UTF-8) ou integer.
Définissez l’attribut cible : Entrez le chemin de l’attribut pour stocker le résultat décodé.
Processeur d’intelligence sur les menaces
Ajoutez le Processeur d’Intelligence sur les Menaces pour évaluer les journaux par rapport à la table en utilisant une clé d’Indicateur de Compromis (IoC) spécifique, comme une adresse IP. Si une correspondance est trouvée, le journal est enrichi avec des attributs d’Intelligence sur les Menaces (TI) pertinents provenant de la table, ce qui améliore la détection, l’investigation et la réponse.
Utilisez le processeur OCSF pour normaliser vos journaux de sécurité selon l’Open Cybersecurity Schema Framework (OCSF). Le processeur OCSF vous permet de créer des mappages personnalisés qui remappent vos attributs de journal aux classes de schéma OCSF et à leurs attributs correspondants, y compris les attributs énumérés (ENUM).
Le processeur vous permet de :
Mapper les attributs de journal source aux attributs cibles OCSF
Configurer les attributs ENUM avec des valeurs numériques spécifiques
Créer des sous-pipelines pour différentes classes d’événements cibles OCSF
Prétraiter les journaux avant le remappage OCSF
Pour obtenir des instructions détaillées pour la configuration, des exemples de configuration et des conseils de dépannage, voir OCSF Processor.
Lectures complémentaires
Documentation, liens et articles supplémentaires utiles: