Les Live Processes et la surveillance des live processes sont inclus dans la formule Enterprise. Pour les autres formule, contactez votre représentant commercial ou
success@datadoghq.com pour demander l'activation de cette fonctionnalité.
Introduction
Les live processes de Datadog vous offrent une visibilité en temps réel sur les processus en cours d’exécution sur votre infrastructure. Grâce aux live processes, vous pouvez :
- Consulter en un seul endroit tous vos processus en cours d’exécution
- Consulter en détail la consommation des ressources sur vos hosts et vos conteneurs, à l’échelle des processus
- Interroger les processus en cours d’exécution sur un certain host, dans une zone spécifique ou avec une charge de travail précise
- Surveiller les performances des logiciels internes et tiers pendant leur utilisation à l’aide de métriques système dotées d’une granularité de deux secondes
- Ajouter des données de contexte à vos dashboards et notebooks
Installation
Si vous utilisez l’Agent v5, suivez ce processus d’installation. Si vous utilisez les versions 6 ou 7, consultez ces instructions.
Une fois l’installation de l’Agent Datadog effectuée, activez la collecte des live processes en modifiant le fichier de configuration principal de l’Agent. Définissez le paramètre suivant sur true :
process_config:
process_collection:
enabled: true
En outre, certaines options de configuration peuvent être définies en tant que variables d’environnement.
Remarque : les options définies en tant que variables d’environnement remplacent les paramètres définis dans le fichier de configuration.
Une fois la configuration effectuée, redémarrez l’Agent.
Suivez les instructions pour l’Agent Docker, en transmettant, en plus de tout autre paramètre personnalisé, les attributs suivants (selon les cas) :
-v /etc/passwd:/etc/passwd:ro
-e DD_PROCESS_CONFIG_PROCESS_COLLECTION_ENABLED=true
Remarques :
- Pour recueillir des informations relatives aux conteneurs dans l’installation standard, l’utilisateur
dd-agent doit disposer des autorisations d’accès à docker.sock. - Il est possible de recueillir des processus de host même lorsque l’Agent est exécuté en tant que conteneur.
Mettez à jour votre fichier datadog-values.yaml avec la configuration suivante pour la collecte des processus :
datadog:
# (...)
processAgent:
enabled: true
processCollection: true
Mettez ensuite à niveau votre chart Helm :
helm upgrade -f datadog-values.yaml <NOM_VERSION> datadog/datadog
Remarque : il est possible de recueillir des processus de host même lorsque l’Agent est exécuté en tant que conteneur.
Dans votre fichier datadog-agent.yaml, définissez features.liveProcessCollection.enabled sur true.
apiVersion: datadoghq.com/v2alpha1
kind: DatadogAgent
metadata:
name: datadog
spec:
global:
credentials:
apiKey: <CLÉ_API_DATADOG>
features:
liveProcessCollection:
enabled: true
After making your changes, apply the new configuration by using the following command:
kubectl apply -n $DD_NAMESPACE -f datadog-agent.yaml
Remarque : il est possible de recueillir des processus de host même lorsque l’Agent est exécuté en tant que conteneur.
Dans le manifeste datadog-agent.yaml utilisé pour créer le DaemonSet, ajoutez les variables d’environnement, le montage de volume et le volume suivants :
env:
- name: DD_PROCESS_CONFIG_PROCESS_COLLECTION_ENABLED
value: "true"
volumeMounts:
- name: passwd
mountPath: /etc/passwd
readOnly: true
volumes:
- hostPath:
path: /etc/passwd
name: passwd
Consultez la section sur l’installation DaemonSet standard et les pages d’informations sur l’Agent Docker pour en savoir plus.
Remarque : il est possible de recueillir des processus de host même lorsque l’Agent est exécuté en tant que conteneur.
Vous pouvez consulter vos processus ECS Fargate dans Datadog. Pour visualiser leur relation avec les conteneurs ECS Fargate, utilisez l'Agent Datadog v7.50.0 ou une version ultérieure.
Pour collecter les processus, l’Agent Datadog doit s’exécuter en tant que conteneur au sein de la tâche.
Pour activer la surveillance des processus dans ECS Fargate, définissez la variable d’environnement DD_PROCESS_AGENT_PROCESS_COLLECTION_ENABLED sur true dans la définition du conteneur de l’Agent Datadog, au sein de la définition de tâche.
Exemple :
{
"taskDefinitionArn": "...",
"containerDefinitions": [
{
"name": "datadog-agent",
"image": "public.ecr.aws/datadog/agent:latest",
...
"environment": [
{
"name": "DD_PROCESS_AGENT_PROCESS_COLLECTION_ENABLED",
"value": "true"
}
...
]
...
}
]
...
}
Pour commencer à collecter les informations de processus dans ECS Fargate, ajoutez le paramètre pidMode à la définition de tâche et définissez-le sur task comme suit :
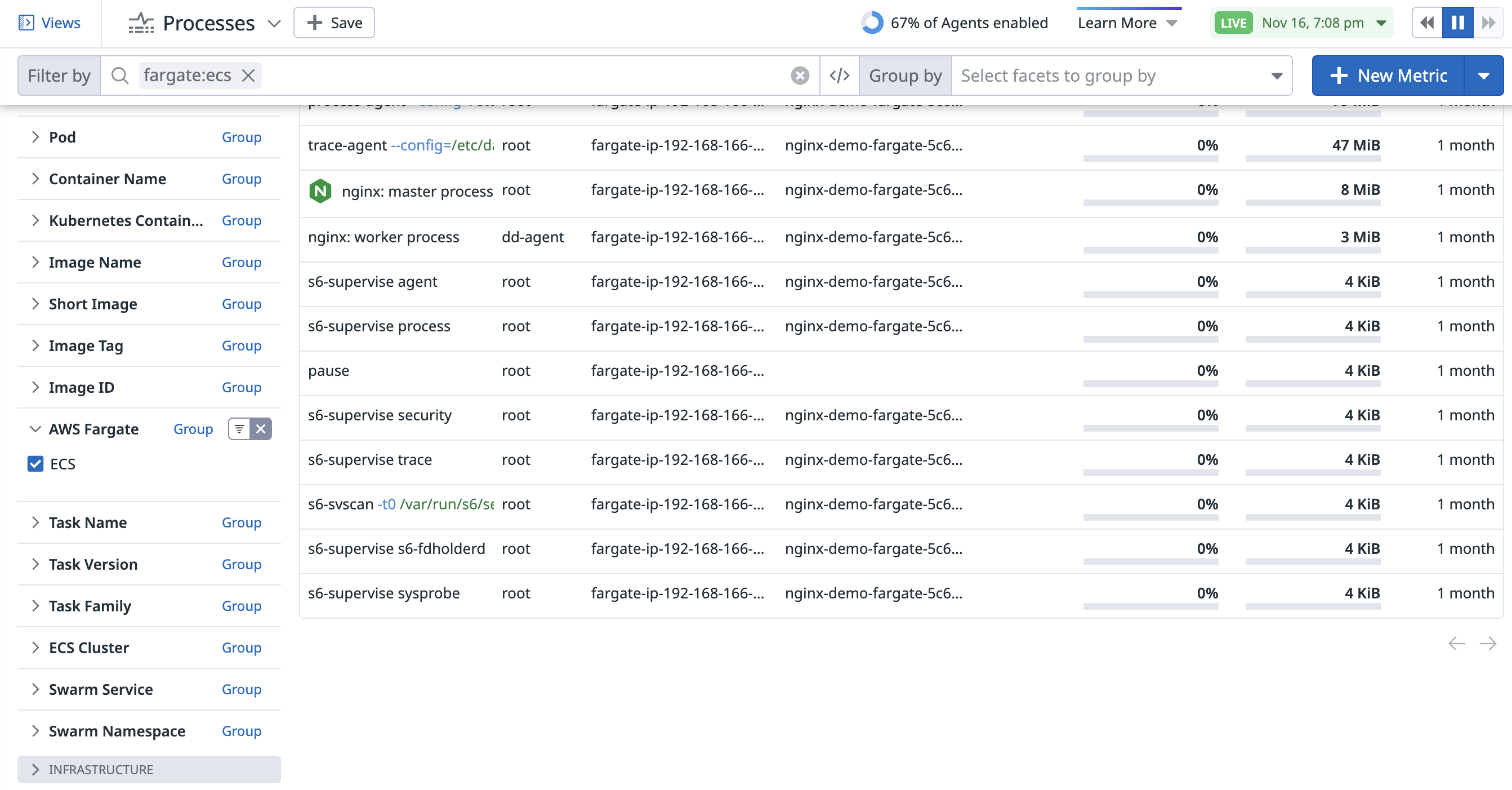
Une fois la fonctionnalité activée, utilisez la facette AWS Fargate Containers sur la page Live Processes pour filtrer les processus en cours d’exécution dans ECS, ou saisissez fargate:ecs dans le champ de recherche.
Pour en savoir plus sur l’installation de l’Agent Datadog avec AWS ECS Fargate, consultez la documentation d’intégration ECS Fargate.
Statistiques d’E/S
Les statistiques d’E/S et de fichiers ouverts peuvent être collectées par le system-probe de Datadog, qui s’exécute avec des privilèges élevés. Pour collecter ces statistiques, activez le module process du system-probe :
Copiez l’exemple de configuration system-probe :
sudo -u dd-agent install -m 0640 /etc/datadog-agent/system-probe.yaml.example /etc/datadog-agent/system-probe.yaml
Modifiez le fichier /etc/datadog-agent/system-probe.yaml pour activer le module process :
system_probe_config:
process_config:
enabled: true
Redémarrez l’Agent :
sudo systemctl restart datadog-agent
Remarque : si vous ne pouvez pas utiliser la commande systemctl sur votre système, exécutez la commande suivante : sudo service datadog-agent restart.
Empreinte optimisée de la collecte des processus
Nécessite l'Agent Datadog v7.53.0 ou ultérieur et Linux.
Activé par défaut à partir de l'Agent Datadog v7.65.0+.
Sous Linux, vous pouvez réduire l’empreinte globale de l’Agent Datadog en exécutant la collecte des conteneurs et des processus dans l’Agent Datadog principal (au lieu de l’Agent de processus distinct).
Activer la collecte optimisée des processus
Avec l’Agent Datadog v7.65.0 ou ultérieur, la collecte optimisée des processus est activée par défaut. Si vous utilisez une version antérieure de l’Agent Datadog (à partir de la v7.53.0, mais inférieure à la v7.65.0), suivez les étapes ci-dessous pour activer la collecte optimisée des processus :
- Modifiez votre configuration.
Si vous utilisez le chart Helm Datadog v3.84.0 ou ultérieur, la collecte optimisée des processus est activée par défaut.
Ajoutez la configuration runInCoreAgent à votre fichier datadog-values.yaml :
datadog:
processAgent:
enabled: true
runInCoreAgent: true
Ajoutez la configuration DD_PROCESS_CONFIG_RUN_IN_CORE_AGENT_ENABLED dans votre fichier datadog-agent.yaml :
apiVersion: datadoghq.com/v2alpha1
kind: DatadogAgent
metadata:
name: datadog
spec:
override:
nodeAgent:
env:
- name: DD_PROCESS_CONFIG_RUN_IN_CORE_AGENT_ENABLED
value: "true"
Si vous exécutez l’Agent en dehors de conteneurs sous Linux, ajoutez l’indicateur run_in_core_agent dans votre fichier datadog.yaml :
process_config:
process_collection:
enabled: true
run_in_core_agent:
enabled: true
Dans system-probe.yaml :
network_config:
enabled: false
- Démarrez l’Agent Datadog.
sudo service datadog-agent start
Vérification
- Consultez les logs de votre Agent de processus (
/var/log/datadog/process-agent.log) et vérifiez que l’Agent de processus (process-agent) ne se lance pas.
Par exemple :2024-02-14 10:45:23 PST | PROCESS | INFO | (comp/process/agent/agentimpl/agent_linux.go:44 in agentEnabled) | The process checks will run in the core agent
2024-02-14 10:45:23 PST | PROCESS | INFO | (command/main_common.go:193 in runApp) | process-agent is not enabled, exiting...
- Consultez les logs de votre Agent Datadog principal (
/var/log/datadog/agent.log) et vérifiez que l’Agent de processus (process-agent) se lance.
Par exemple :2024-02-14 10:33:29 PST | CORE | INFO | (pkg/process/runner/runner.go:276 in Run) | Starting process-agent with enabled checks=[process rtprocess]
...
2024-02-14 10:33:29 PST | CORE | INFO | (pkg/process/runner/runner.go:233 in logCheckDuration) | Finished process check #1 in 9.37683ms
- Consultez le Process Explorer dans Datadog :
- Vérifiez que vos données de processus et de conteneurs sont visibles.
- Vérifiez que le processus
agent est en cours d’exécution. - Vérifiez que le processus
process-agent n’est pas en cours d’exécution.
Désactiver la collecte optimisée des processus
Si vous utilisez l’Agent Datadog v7.65.0 ou ultérieur, ou si vous avez activé la collecte optimisée des processus dans une version antérieure de l’Agent Datadog, suivez les étapes ci-dessous pour désactiver la collecte optimisée des processus :
- Modifiez votre configuration.
Ajoutez la configuration runInCoreAgent à votre fichier datadog-values.yaml :
datadog:
processAgent:
enabled: true
runInCoreAgent: false
Ajoutez la configuration DD_PROCESS_CONFIG_RUN_IN_CORE_AGENT_ENABLED dans votre fichier datadog-agent.yaml :
apiVersion: datadoghq.com/v2alpha1
kind: DatadogAgent
metadata:
name: datadog
spec:
override:
nodeAgent:
env:
- name: DD_PROCESS_CONFIG_RUN_IN_CORE_AGENT_ENABLED
value: "false"
Si vous exécutez l’Agent en dehors de conteneurs sous Linux, ajoutez l’indicateur run_in_core_agent dans votre fichier datadog.yaml :
process_config:
run_in_core_agent:
enabled: false
Dans system-probe.yaml :
network_config:
enabled: false
- Démarrez l’Agent Datadog.
sudo service datadog-agent start
Vérification
- Consultez les logs de votre Agent de processus (
/var/log/datadog/process-agent.log) et vérifiez que l’Agent de processus (process-agent) se lance.
Par exemple :2024-02-14 12:37:42 PST | PROCESS | INFO | (pkg/process/runner/runner.go:276 in Run) | Starting process-agent with enabled checks=[process rtprocess]
2024-02-14 12:37:42 PST | PROCESS | INFO | (pkg/process/runner/runner.go:233 in logCheckDuration) | Finished process check #1 in 9.249009ms
- Consultez les logs de votre Agent Datadog principal (
/var/log/datadog/agent.log) et vérifiez que l’Agent de processus (process-agent) ne se lance pas. - Consultez le Process Explorer dans Datadog :
- Vérifiez que vos données de processus et de conteneurs sont visibles.
- Vérifiez que le processus
process-agent est en cours d’exécution.
Dans les environnements non-Linux, la collecte des conteneurs et des processus s'exécute toujours dans l'Agent de processus distinct.
Nettoyage des arguments de processus
Pour masquer des données sensibles sur une page Live Processes, l’Agent nettoie les arguments sensibles de la ligne de commande de processus. Cette fonctionnalité est activée par défaut, et la valeur de tout argument de processus correspondant aux mots suivants est masquée.
"password", "passwd", "mysql_pwd", "access_token", "auth_token", "api_key", "apikey", "secret", "credentials", "stripetoken"
Remarque : la mise en correspondance est sensible à la casse.
Pour définir votre propre liste à fusionner avec celle par défaut, utilisez le champ custom_sensitive_words à la section process_config du fichier datadog.yaml. Appliquez des wildcards (*) pour définir votre propre contexte de correspondance. Toutefois, un wildcard unique ('*') ne peut pas être utilisé en tant que mot sensible.
process_config:
scrub_args: true
custom_sensitive_words: ['personal_key', '*token', 'sql*', '*pass*d*']
Remarque : les termes inclus dans le champ custom_sensitive_words peuvent uniquement contenir des caractères alphanumériques, des underscores et des wildcards ('*'). Un mot sensible ne peut pas être composé d’un wildcard uniquement.
L’image suivante illustre un processus sur la page Live Processes dont les arguments ont été masqués à l’aide de la configuration ci-dessus.
Définissez scrub_args sur false pour désactiver entièrement le nettoyage des arguments de processus.
Vous pouvez également nettoyer tous les arguments des processus en activant le flag strip_proc_arguments dans votre fichier de configuration datadog.yaml :
process_config:
strip_proc_arguments: true
Vous pouvez utiliser le chart Helm pour définir votre propre liste, qui est fusionnée avec la liste par défaut. Ajoutez les variables d’environnement DD_SCRUB_ARGS et DD_CUSTOM_SENSITIVE_WORDS à votre fichier datadog-values.yaml, et modifiez votre chart Helm Datadog :
datadog:
# (...)
processAgent:
enabled: true
processCollection: true
agents:
containers:
processAgent:
env:
- name: DD_SCRUB_ARGS
value: "true"
- name: DD_CUSTOM_SENSITIVE_WORDS
value: "personal_key,*token,*token,sql*,*pass*d*"
Appliquez des wildcards (*) pour définir votre propre contexte de correspondance. Toutefois, un wildcard unique ('*') ne peut pas être utilisé en tant que mot sensible.
Définissez DD_SCRUB_ARGS sur false pour désactiver entièrement le nettoyage des arguments de processus.
Vous pouvez également nettoyer tous les arguments des processus en activant la variable DD_STRIP_PROCESS_ARGS dans votre fichier datadog-values.yaml :
datadog:
# (...)
processAgent:
enabled: true
processCollection: true
agents:
containers:
processAgent:
env:
- name: DD_STRIP_PROCESS_ARGS
value: "true"
Requêtes
Déterminer le contexte des processus
De par leur nature, les processus sont des objets caractérisés par une très forte cardinalité. Vous pouvez utiliser les filtres de texte et de tag pour préciser votre contexte afin d’afficher uniquement les processus pertinents.
Filtres de texte
Lorsque vous saisissez une chaîne de texte dans la barre de recherche, la fonction de recherche de chaîne approximative est utilisée pour interroger les processus contenant cette chaîne dans leurs lignes de commande ou leurs chemins. Saisissez une chaîne composée de deux caractères ou plus pour afficher des résultats. L’image ci-dessous présente l’environnement de démonstration de Datadog filtré avec la chaîne postgres /9..
Remarque : /9. génère une correspondance dans le chemin de commande, tandis que postgres génère une correspondance dans la commande.
Pour combiner plusieurs recherches textuelles au sein d’une requête complexe, utilisez l’un des opérateurs booléens suivants :
AND- Intersection : les deux termes figurent dans les événements sélectionnés (si aucun opérateur n’est ajouté, l’opérateur AND est défini par défaut)
Exemple : java AND elasticsearch OR- Union : un des deux termes figure dans les événements sélectionnés
Exemple : java OR python NOT / !- Exclusion : le terme suivant ne figure PAS dans l’événement. Vous pouvez utiliser le mot
NOT ou le caractère ! pour effectuer la même opération
Exemple : java NOT elasticsearch ou java !elasticsearch
Utilisez des parenthèses pour regrouper les opérateurs. Par exemple, (NOT (elasticsearch OR kafka) java) OR python .
Filtres de tag
Vous pouvez également filtrer vos processus à l’aide de tags Datadog comme host, pod, user et service. Saisissez des filtres de tag directement dans la barre de recherche ou sélectionnez-les dans le volet des facettes, situé sur la gauche de la page.
Datadog génère automatiquement un tag command, afin que vous puissiez appliquer un filtre basé sur les éléments suivants :
- Les logiciels tiers, par exemple :
command:mongod ou command:nginx - Les logiciels de gestion de conteneurs, par exemple :
command:docker ou command:kubelet - Les workloads standard, par exemple :
command:ssh ou command:CRON
En outre, les processus des conteneurs ECS se voient appliquer les tags suivants :
task_nametask_versionecs_cluster
Les processus des conteneurs Kubernetes se voient appliquer les tags suivants :
pod_namekube_servicekube_namespacekube_replica_setkube_daemon_setkube_jobkube_deploymentkube_cluster_name
Si vous avez configuré le tagging de service unifié, les tags env, service, et version sont recueillis automatiquement. L’utilisation de ces tags vous permet de lier entre elles les données de l’APM, des logs, des métriques et des processus. Remarque : cette configuration s’applique uniquement aux environnements conteneurisés.
Vous pouvez créer des définitions de règles pour ajouter manuellement des tags aux processus en fonction de la ligne de commande.
- Dans l’onglet Manage Process Tags, sélectionnez le bouton New Process Tag Rule
- Sélectionner un processus à utiliser comme référence
- Définir les critères d’analyse et de correspondance pour votre tag
- Si la validation est réussie, créez une nouvelle règle
Une fois la règle créée, les tags sont appliqués à toutes les lignes de commande de processus correspondant aux critères de la règle. Ces tags sont disponibles dans la recherche et peuvent être utilisés dans la définition de monitors Live Process et de métriques custom.
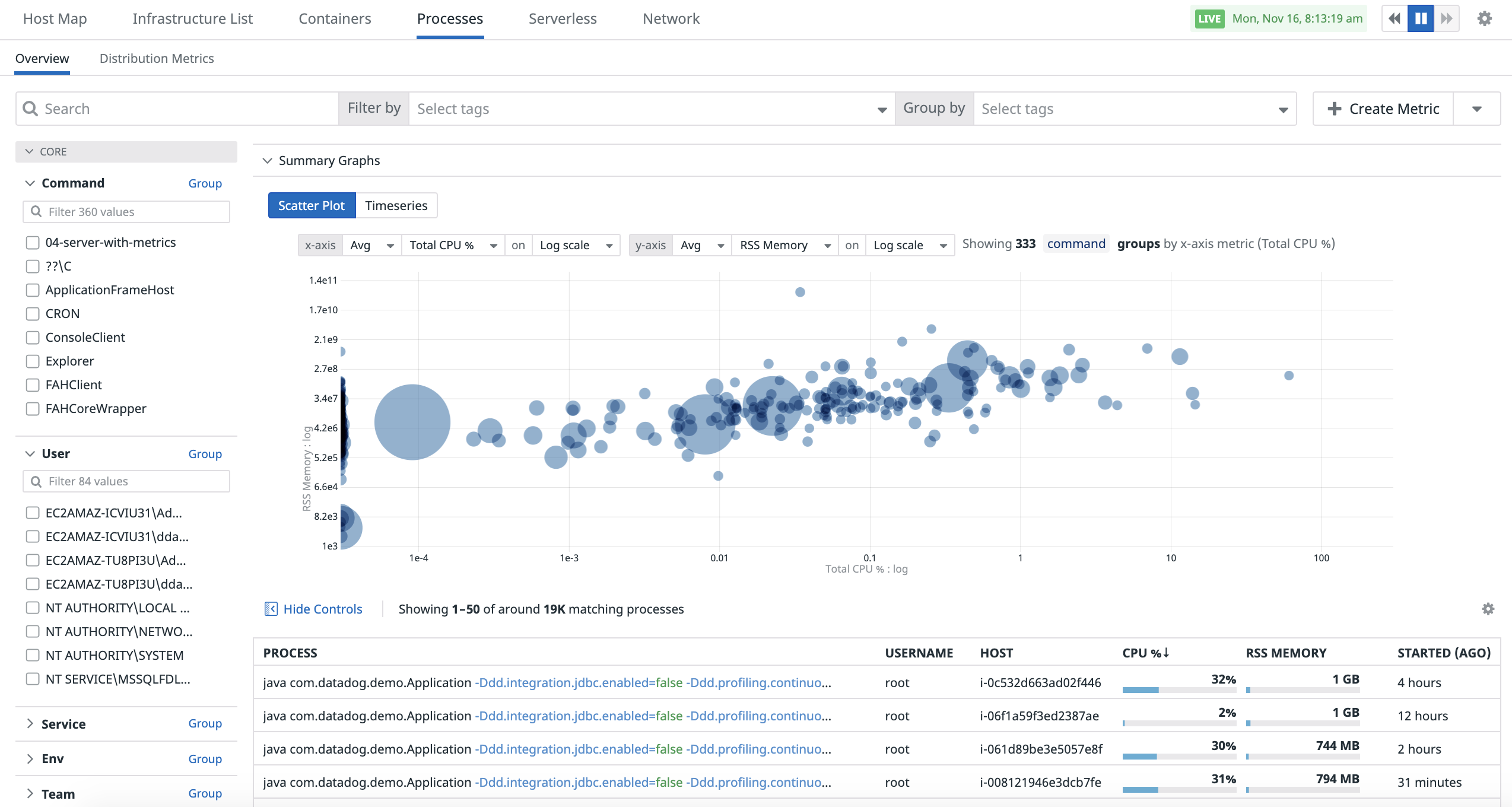
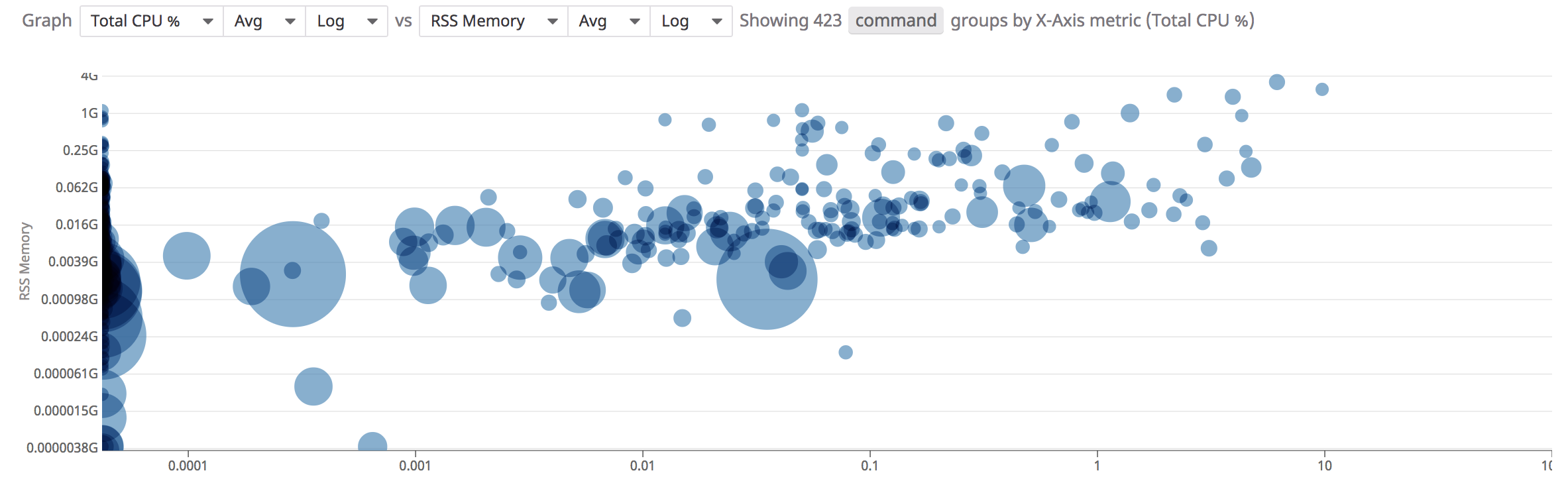
Nuage de points
Utilisez l’analyse de nuage de points pour comparer deux métriques entre elles et ainsi mieux comprendre les performances de vos conteneurs.
Pour accéder à l’analyse de nuage de points dans la page Processes, cliquez sur le bouton Show Summary graph, puis sélectionnez l’onglet « Scatter Plot » :
Par défaut, le graphique regroupe la clé de tag command. La taille de chaque point représente le nombre de processus dans ce groupe. Lorsque vous cliquez sur un point, les processus et les conteneurs qui contribuent au groupe s’affichent.
Les options situées en haut du graphique vous permettent de contrôler votre analyse en nuage de points :
- Choisissez les métriques à afficher.
- Choisissez la méthode d’agrégation des deux métriques.
- Choisissez l’échelle pour l’axe des X et des Y (Linear ou Log).
Monitors de processus
Utilisez le monitor de live processes pour générer des alertes en fonction du nombre de valeurs d’un groupe de processus sur l’ensemble des hosts ou des tags. Vous pouvez configurer les alertes des processus depuis la page Monitors. Pour en savoir plus, consultez la section Monitor de Live Processes.
Processus dans les dashboards et les notebooks
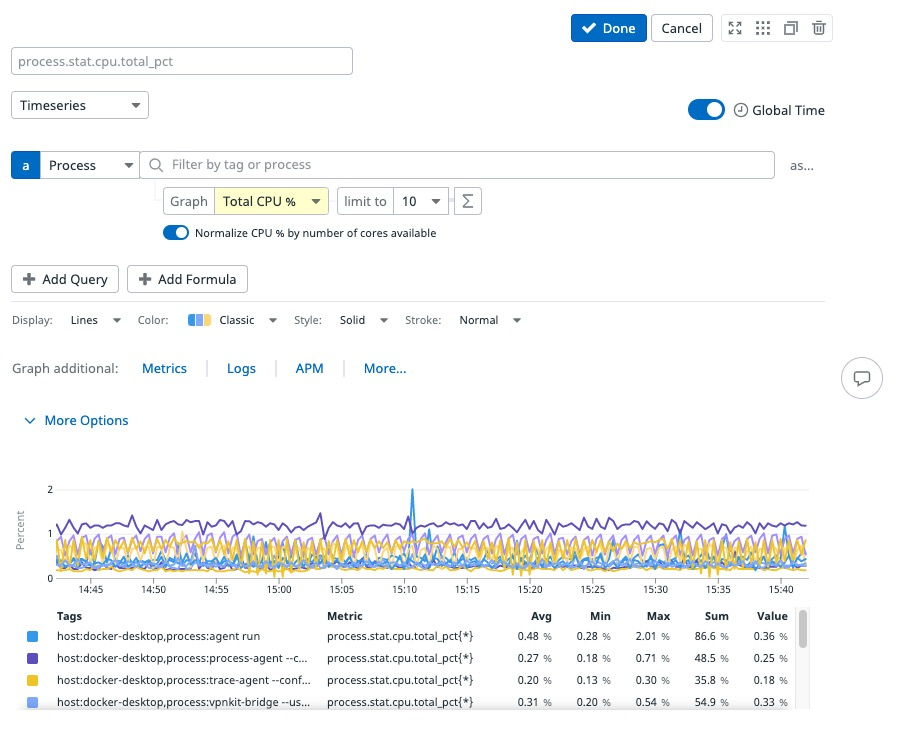
Vous pouvez représenter graphiquement des métriques de processus dans des dashboards et des notebooks à l’aide du widget Série temporelle. Pour configurer les paramètres, procédez comme suit :
- Sélectionnez Processus comme source de données
- Appliquez un filtre à l’aide de chaînes de texte dans la barre de recherche.
- Sélectionnez une métrique de processus à représenter.
- Appliquez un filtre à l’aide des tags du champ
From.
Surveiller des logiciels tiers
Intégrations détectées automatiquement
Datadog utilise la collecte de processus pour détecter automatiquement les technologies qui s’exécutent sur vos hosts. Cette opération permet d’identifier les intégrations Datadog qui peuvent vous aider à surveiller ces technologies. Les intégrations détectées automatiquement s’affichent dans la recherche d’intégrations :
Chaque intégration possède l’un des deux types de statuts suivants :
- + Detected : cette intégration n’est activée sur aucun host qui l’exécute.
- ✓ Partial Visibility : cette intégration est activée sur certains hosts, mais les hosts pertinents ne l’exécutent pas tous.
Les hosts qui exécutent l’intégration, mais sur lesquels l’intégration n’est pas activée, se trouvent dans l’onglet Hosts du carré de l’intégration.
Vues d’intégration
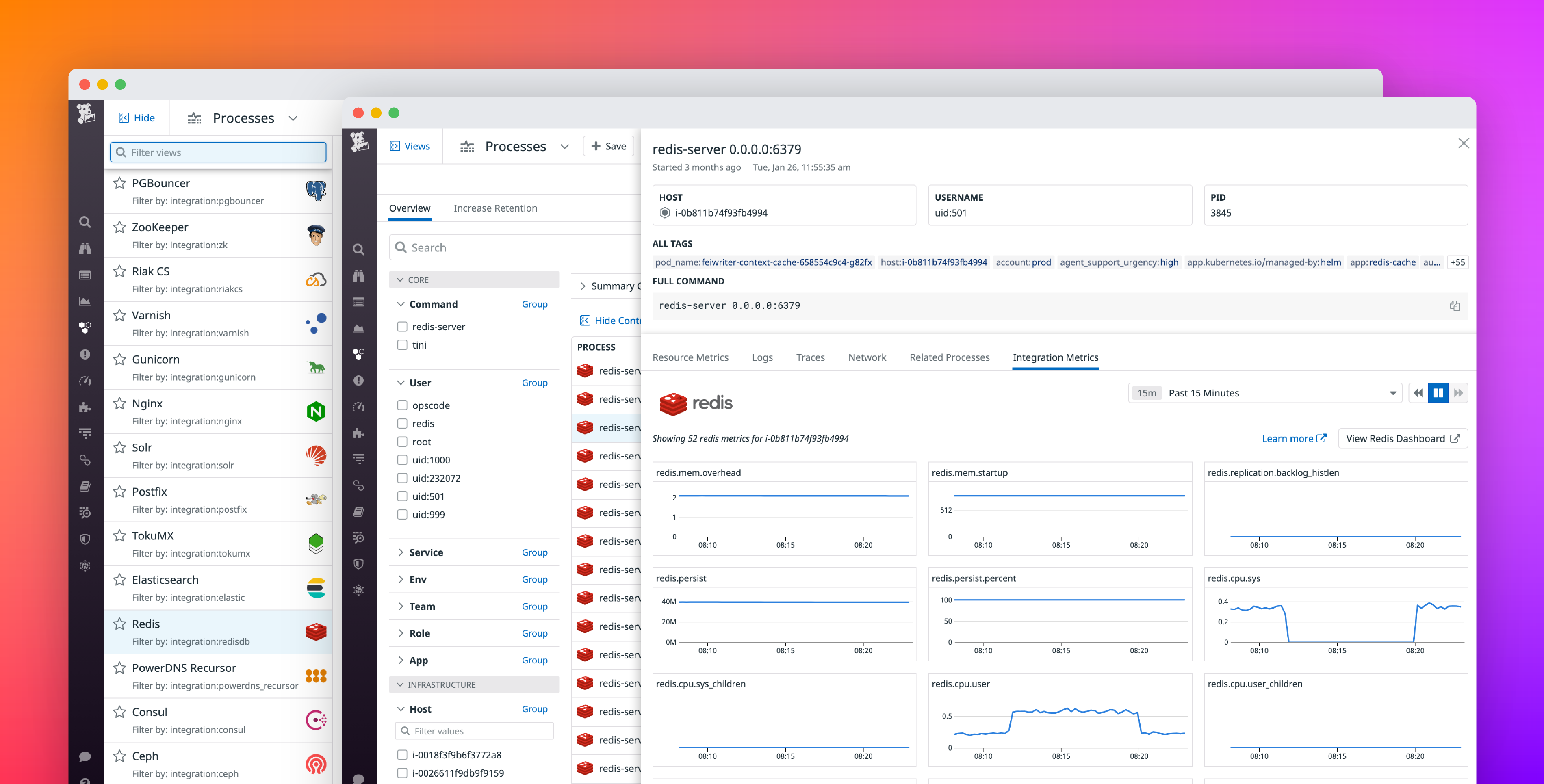
Une fois qu’un logiciel tiers a été détecté, les live processes vous permettent d’analyser les performances de ce logiciel.
- Pour commencer, cliquez sur Views en haut à droite de la page afin d’ouvrir la liste des options prédéfinies, y compris Nginx, Redis et Kafka.
- Sélectionnez une vue pour afficher uniquement les processus qui exécutent ce logiciel.
- Lorsque vous inspectez un processus lourd, passez à l’onglet Integration Metrics pour analyser l’état du logiciel sur le host sous-jacent. Si vous avez déjà activé l’intégration Datadog pertinente, vous pouvez visualiser toutes les métriques de performance recueillies via l’intégration afin de déterminer si le problème est lié au host ou au logiciel. Par exemple, si vous constatez que les pics d’utilisation du CPU par le processus correspondent aux pics de latence des requêtes MySQL, cela peut indiquer qu’une opération intensive, comme l’analyse d’une table complète, retarde l’exécution d’autres requêtes MySQL reposant sur les mêmes ressources sous-jacentes.
Vous pouvez personnaliser les vues d’intégration (par exemple, lors de l’agrégation d’une requête pour les processus Nginx par host) et d’autres requêtes personnalisées en cliquant sur le bouton +Save en haut de la page. Votre requête, les colonnes sélectionnées et les paramètres de visualisation sont alors enregistrés. Créez des vues enregistrées pour accéder rapidement aux processus qui vous intéressent sans avoir à modifier la configuration et pour partager des données de processus avec votre équipe.
Live containers
Les live processes vous aident à gagner en visibilité sur les déploiements de vos conteneurs, en surveillant les processus en cours d’exécution sur chacun de vos conteneurs. Cliquez sur un conteneur depuis la page Live Containers pour afficher l’arborescence des processus, y compris les commandes en cours d’exécution et leur consommation de ressources. Lorsqu’elles sont utilisées conjointement à d’autres métriques de conteneur, ces données vous permettent de déterminer l’origine des échecs de conteneurs ou de déploiement.
APM
Dans les traces APM, vous pouvez cliquer sur la span d’un service pour afficher les processus qui s’exécutent sur son infrastructure sous-jacente. Les processus de span d’un service sont mis en corrélation avec les hosts ou pods sur lesquels le service s’exécute au moment de la requête. Vous pouvez analyser des métriques de processus, comme le processeur et la mémoire RSS, en consultant parallèlement les erreurs au niveau du code. Vous pouvez ainsi distinguer les problèmes spécifiques à l’application des problèmes d’infrastructure globaux. Lorsque vous cliquez sur un processus, vous êtes redirigé vers la page Live Processes. Les traces Browser et sans serveur ne proposent actuellement pas de processus connexes.
Surveillance du réseau cloud
Lorsque vous inspectez une dépendance dans la page Network Analytics, vous pouvez consulter les processus exécutés sur l’infrastructure sous-jacente des endpoints, tels que des services, qui communiquent entre eux. Utilisez les métadonnées des processus pour déterminer si une mauvaise connexion réseau (caractérisée par un nombre élevé de retransmissions TCP) ou une forte latence des appels réseau (caractérisée par une longue durée d’aller-retour TCP) peut être causée par le fait que des workloads importants utilisent les ressources de ces endpoints. Un tel dysfonctionnement peut nuire à l’intégrité et à l’efficacité des communications.
Surveillance en temps réel
Les processus sont normalement collectés avec une résolution de 10 secondes. Lors de l’utilisation active de la page Live Processes, les métriques sont collectées avec une résolution de 2 secondes et affichées en temps réel, ce qui est important pour les métriques volatiles comme l’utilisation CPU. Cependant, pour le contexte historique, les métriques sont ingérées avec la résolution par défaut de 10 secondes.
- La collecte de données en temps réel (toutes les 2 s) est désactivée après 30 minutes. Pour reprendre la collecte en temps réel, actualisez la page.
- Dans les déploiements en conteneur, le fichier
/etc/passwd monté dans le docker-dd-agent est nécessaire pour collecter les noms d’utilisateur associés à chaque processus. Ce fichier est public et l’Agent de processus n’utilise aucun champ en dehors du nom d’utilisateur. Si l’Agent s’exécute sans privilèges, le montage n’a pas lieu. Même sans accès au fichier /etc/passwd, toutes les fonctionnalités restent disponibles, à l’exception du champ de métadonnées user.
Remarque : Live Processes utilise uniquement le fichier passwd du host et ne résout pas les noms d’utilisateur créés à l’intérieur des conteneurs.
Pour aller plus loin
Documentation, liens et articles supplémentaires utiles: