Cette page n'est pas encore disponible en français, sa traduction est en cours.
Si vous avez des questions ou des retours sur notre projet de traduction actuel,
n'hésitez pas à nous contacter.
Live Processes and Live Process Monitoring are included in the Enterprise plan. For all other plans, contact your account representative or
success@datadoghq.com to request this feature.
Introduction
Datadog’s Live Processes gives you real-time visibility into the processes running on your infrastructure. Use Live Processes to:
- View all of your running processes in one place
- Break down the resource consumption on your hosts and containers at the process level
- Query for processes running on a specific host, in a specific zone, or running a specific workload
- Monitor the performance of the internal and third-party software you run using system metrics at two-second granularity
- Add context to your dashboards and notebooks
Installation
If you are using Agent 5, follow this specific installation process. If you are using Agent 6 or 7, see the instructions below.
Once the Datadog Agent is installed, enable Live Processes collection by editing the Agent main configuration file by setting the following parameter to true:
process_config:
process_collection:
enabled: true
Additionally, some configuration options may be set as environment variables.
Note: Options set as environment variables override the settings defined in the configuration file.
After configuration is complete, restart the Agent.
Follow the instructions for the Docker Agent, passing in the following attributes, in addition to any other custom settings as appropriate:
-v /etc/passwd:/etc/passwd:ro
-e DD_PROCESS_CONFIG_PROCESS_COLLECTION_ENABLED=true
Note:
- To collect container information in the standard install, the
dd-agent user must have permissions to access docker.sock. - Running the Agent as a container still allows you to collect host processes.
Update your datadog-values.yaml file with the following process collection configuration:
datadog:
# (...)
processAgent:
enabled: true
processCollection: true
Then, upgrade your Helm chart:
helm upgrade -f datadog-values.yaml <RELEASE_NAME> datadog/datadog
Note: Running the Agent as a container still allows you to collect host processes.
In your datadog-agent.yaml, set features.liveProcessCollection.enabled to true.
apiVersion: datadoghq.com/v2alpha1
kind: DatadogAgent
metadata:
name: datadog
spec:
global:
credentials:
apiKey: <DATADOG_API_KEY>
features:
liveProcessCollection:
enabled: true
After making your changes, apply the new configuration by using the following command:
kubectl apply -n $DD_NAMESPACE -f datadog-agent.yaml
Note: Running the Agent as a container still allows you to collect host processes.
In the datadog-agent.yaml manifest used to create the DaemonSet, add the following environmental variables, volume mount, and volume:
env:
- name: DD_PROCESS_CONFIG_PROCESS_COLLECTION_ENABLED
value: "true"
volumeMounts:
- name: passwd
mountPath: /etc/passwd
readOnly: true
volumes:
- hostPath:
path: /etc/passwd
name: passwd
See the standard DaemonSet installation and the Docker Agent information pages for further documentation.
Note: Running the Agent as a container still allows you to collect host processes.
You can view your ECS Fargate processes in Datadog. To see their relationship to ECS Fargate containers, use the Datadog Agent v7.50.0 or later.
In order to collect processes, the Datadog Agent must be running as a container within the task.
To enable process monitoring in ECS Fargate, set the DD_PROCESS_AGENT_PROCESS_COLLECTION_ENABLED environment variable to true in the Datadog Agent container definition within the task definition.
For example:
{
"taskDefinitionArn": "...",
"containerDefinitions": [
{
"name": "datadog-agent",
"image": "public.ecr.aws/datadog/agent:latest",
...
"environment": [
{
"name": "DD_PROCESS_AGENT_PROCESS_COLLECTION_ENABLED",
"value": "true"
}
...
]
...
}
]
...
}
To start collecting process information in ECS Fargate, add the pidMode parameter to the Task Definition and set it to task as follows:
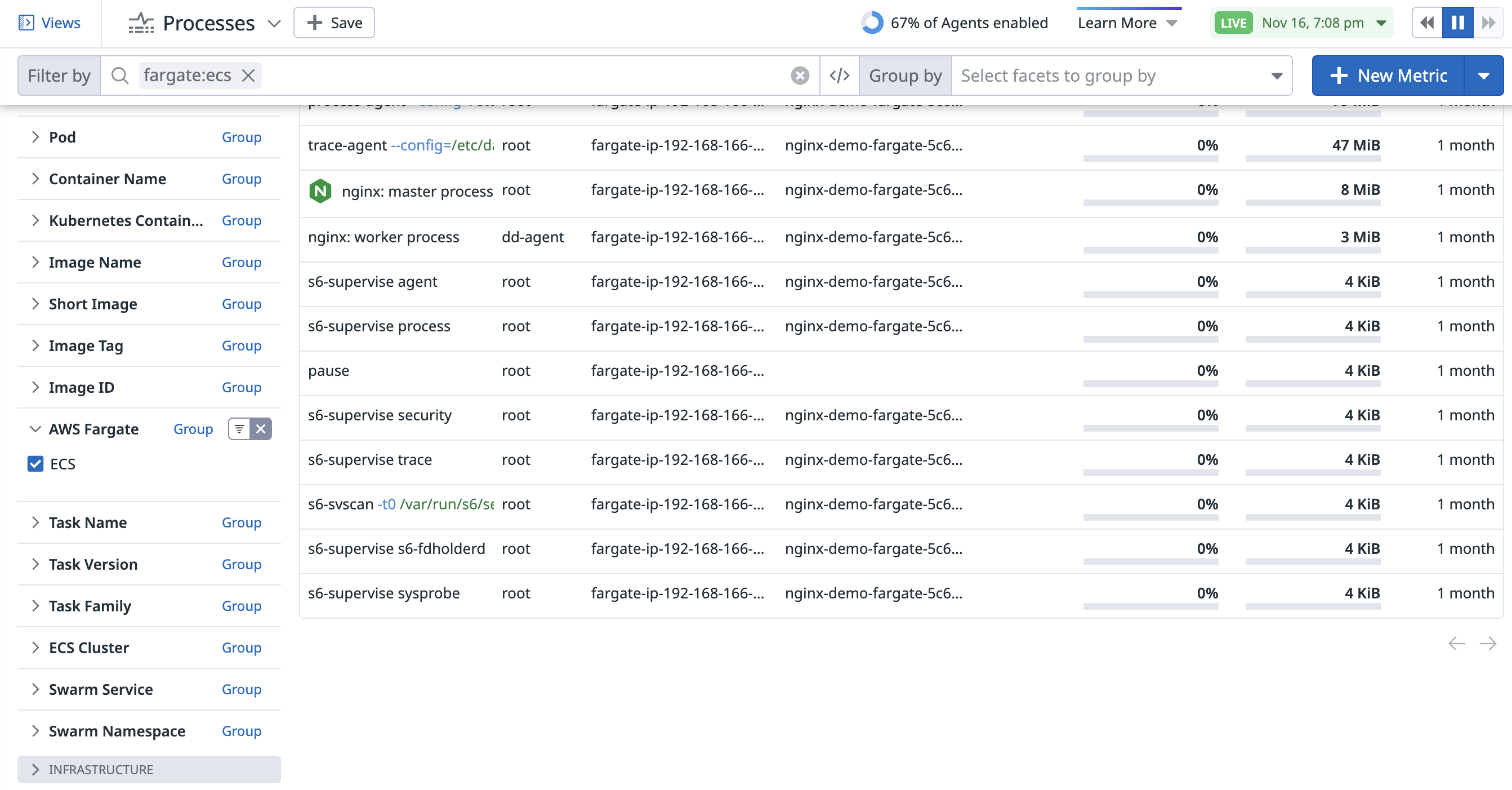
Once enabled, use the AWS Fargate Containers facet on the Live Processes page to filter for processes running in ECS, or enter fargate:ecs in the search query.
For more information about installing the Datadog Agent with AWS ECS Fargate, see the ECS Fargate integration documentation.
I/O stats
I/O and open files stats can be collected by the Datadog system-probe, which runs with elevated privileges. To collect these stats, enable the process module of the system-probe:
Copy the system-probe example configuration:
sudo -u dd-agent install -m 0640 /etc/datadog-agent/system-probe.yaml.example /etc/datadog-agent/system-probe.yaml
Edit /etc/datadog-agent/system-probe.yaml to enable the process module:
system_probe_config:
process_config:
enabled: true
Restart the Agent:
sudo systemctl restart datadog-agent
Note: If the systemctl command is not available on your system, run the following command instead: sudo service datadog-agent restart
As of Agent v7.65.0, container and process collection run in the core Datadog Agent by default on Linux, reducing the Agent’s overall footprint.
For verification, you can explicitly enable this feature.
Add the runInCoreAgent configuration to your datadog-values.yaml file:
datadog:
processAgent:
runInCoreAgent: true
Add the DD_PROCESS_CONFIG_RUN_IN_CORE_AGENT_ENABLED configuration in your datadog-agent.yaml file:
apiVersion: datadoghq.com/v2alpha1
kind: DatadogAgent
metadata:
name: datadog
spec:
override:
nodeAgent:
env:
- name: DD_PROCESS_CONFIG_RUN_IN_CORE_AGENT_ENABLED
value: "true"
If you are running the Agent outside of containers on Linux, add the run_in_core_agent flag in your datadog.yaml file:
process_config:
run_in_core_agent:
enabled: true
Explicitly setting the config flag to false will cause container and process collection to run in the separate Process Agent. Note that container and process collection always run in the separate Process Agent in non-Linux environments.
Process arguments scrubbing
In order to hide sensitive data on the Live Processes page, the Agent scrubs sensitive arguments from the process command line. This feature is enabled by default and any process argument that matches one of the following words has its value hidden.
"password", "passwd", "mysql_pwd", "access_token", "auth_token", "api_key", "apikey", "secret", "credentials", "stripetoken"
Note: The matching is case insensitive.
Define your own list to be merged with the default one, using the custom_sensitive_words field in datadog.yaml file under the process_config section. Use wildcards (*) to define your own matching scope. However, a single wildcard ('*') is not supported as a sensitive word.
process_config:
scrub_args: true
custom_sensitive_words: ['personal_key', '*token', 'sql*', '*pass*d*']
Note: Words in custom_sensitive_words must contain only alphanumeric characters, underscores, or wildcards ('*'). A wildcard-only sensitive word is not supported.
The next image shows one process on the Live Processes page whose arguments have been hidden by using the configuration above.
Set scrub_args to false to completely disable the process arguments scrubbing.
You can also scrub all arguments from processes by enabling the strip_proc_arguments flag in your datadog.yaml configuration file:
process_config:
strip_proc_arguments: true
You can use the Helm chart to define your own list, which is merged with the default one. Add the environment variables DD_SCRUB_ARGS and DD_CUSTOM_SENSITIVE_WORDS to your datadog-values.yaml file, and upgrade your Datadog Helm chart:
datadog:
# (...)
processAgent:
enabled: true
processCollection: true
agents:
containers:
processAgent:
env:
- name: DD_SCRUB_ARGS
value: "true"
- name: DD_CUSTOM_SENSITIVE_WORDS
value: "personal_key,*token,*token,sql*,*pass*d*"
Use wildcards (*) to define your own matching scope. However, a single wildcard ('*') is not supported as a sensitive word.
Set DD_SCRUB_ARGS to false to completely disable the process arguments scrubbing.
Alternatively, you can scrub all arguments from processes by enabling the DD_STRIP_PROCESS_ARGS variable in your datadog-values.yaml file:
datadog:
# (...)
processAgent:
enabled: true
processCollection: true
agents:
containers:
processAgent:
env:
- name: DD_STRIP_PROCESS_ARGS
value: "true"
Queries
Scoping processes
Processes are, by nature, extremely high cardinality objects. To refine your scope to view relevant processes, you can use text and tag filters.
Text filters
When you input a text string into the search bar, fuzzy string search is used to query processes containing that text string in their command lines or paths. Enter a string of two or more characters to see results. Below is Datadog’s demo environment, filtered with the string postgres /9..
Note: /9. has matched in the command path, and postgres matches the command itself.
To combine multiple string searches into a complex query, use any of the following Boolean operators:
AND- Intersection: both terms are in the selected events (if nothing is added, AND is taken by default)
Example: java AND elasticsearch OR- Union: either term is contained in the selected events
Example: java OR python NOT / !- Exclusion: the following term is NOT in the event. You may use the word
NOT or ! character to perform the same operation
Example: java NOT elasticsearch or java !elasticsearch
Use parentheses to group operators together. For example, (NOT (elasticsearch OR kafka) java) OR python .
Tag filters
You can also filter your processes using Datadog tags, such as host, pod, user, and service. Input tag filters directly into the search bar, or select them in the facet panel on the left of the page.
Datadog automatically generates a command tag, so that you can filter for:
- Third-party software, for example:
command:mongod, command:nginx - Container management software, for example:
command:docker, command:kubelet - Common workloads, for example:
command:ssh, command:CRON
Furthermore, processes in ECS containers are also tagged by:
task_nametask_versionecs_cluster
Processes in Kubernetes containers are tagged by:
pod_namekube_servicekube_namespacekube_replica_setkube_daemon_setkube_jobkube_deploymentkube_cluster_name
If you have configuration for Unified Service Tagging in place, env, service, and version are picked up automatically.
Having these tags available lets you tie together APM, logs, metrics, and process data.
Note: This setup applies to containerized environments only.
You can create rule definitions to add manual tags to processes based on the command line.
- On the Manage Process Tags tab, select the New Process Tag Rule button
- Select a process to use as a reference
- Define the parsing and match criteria for your tag
- If validation passes, create a new rule
After a rule is created, tags are available for all process command line values that match the rule criteria. These tags are available in search and can be used in the definition of Live Process Monitors and Custom Metrics.
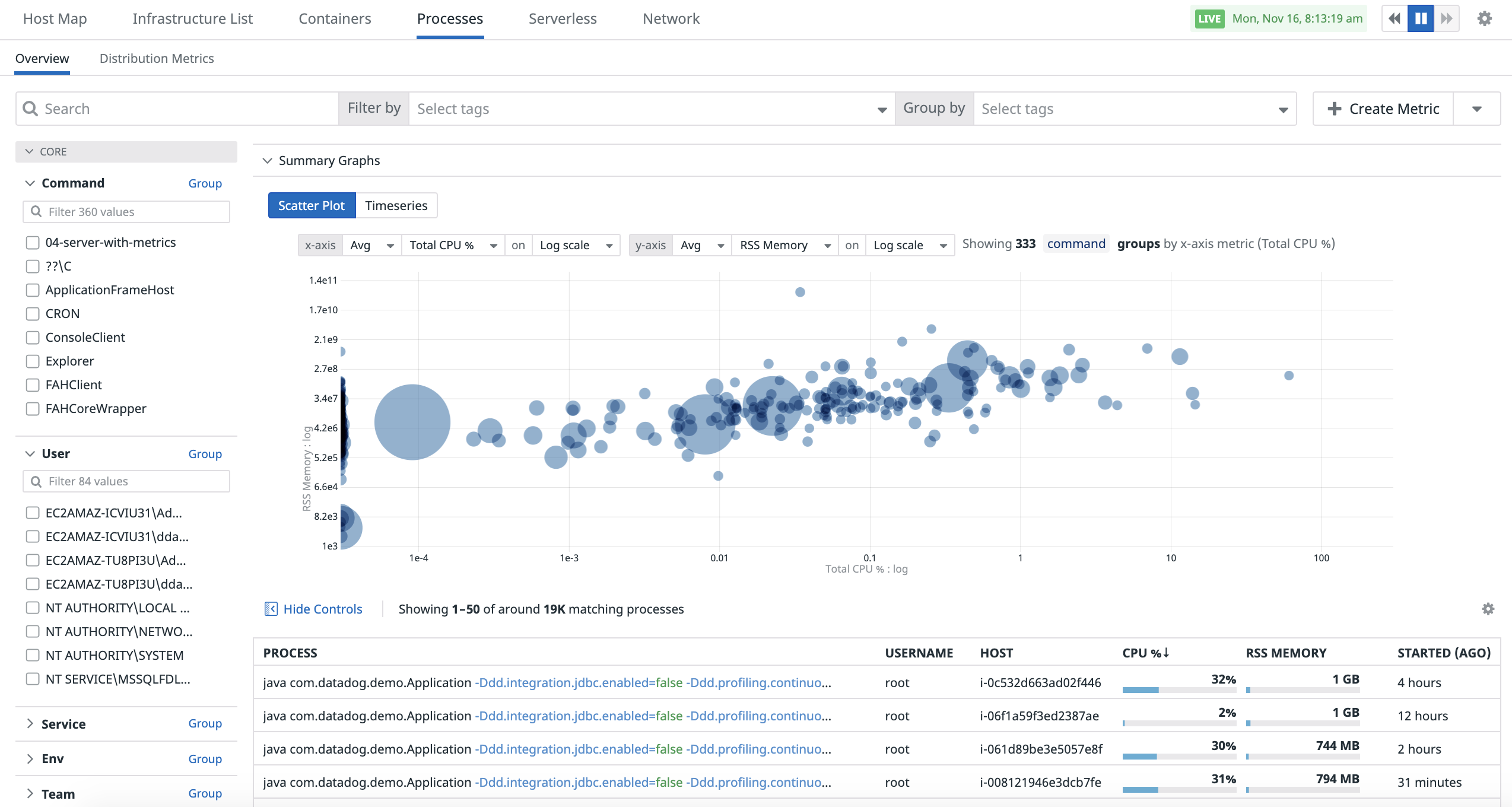
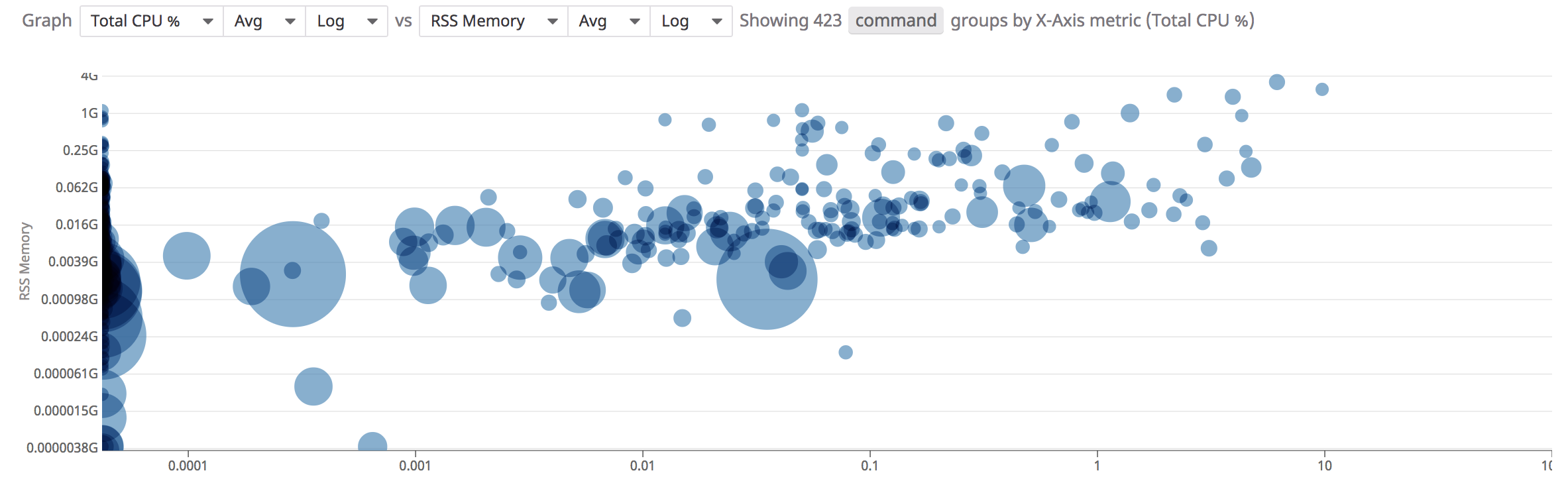
Scatter plot
Use the scatter plot analytic to compare two metrics with one another in order to better understand the performance of your containers.
To access the scatter plot analytic in the Processes page click on the Show Summary graph button then select the “Scatter Plot” tab:
By default, the graph groups by the command tag key. The size of each dot represents the number of processes in that group, and clicking on a dot displays the individual processes and containers that contribute to the group.
The options at the top of the graph allow you to control your scatter plot analytic:
- Selection of metrics to display.
- Selection of the aggregation method for both metrics.
- Selection of the scale of both X and Y axis (Linear/Log).
Process monitors
Use the Live Process Monitor to generate alerts based on the count of any group of processes across hosts or tags. You can configure process alerts in the Monitors page. To learn more, see the Live Process Monitor documentation.
Processes in dashboards and notebooks
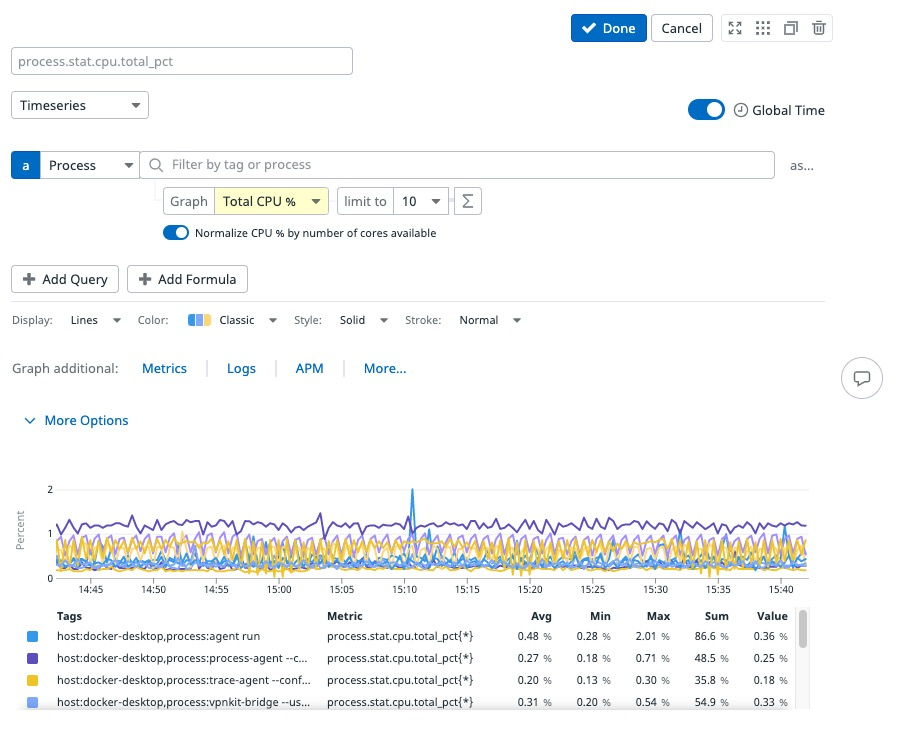
You can graph process metrics in dashboards and notebooks using the Timeseries widget. To configure:
- Select Processes as a data source
- Filter using text strings in the search bar
- Select a process metric to graph
- Filter using tags in the
From field
Monitoring third-party software
Autodetected integrations
Datadog uses process collection to autodetect the technologies running on your hosts. This identifies Datadog integrations that can help you monitor these technologies. These auto-detected integrations are displayed in the Integrations search:
Each integration has one of two status types:
- + Detected: This integration is not enabled on any host(s) running it.
- ✓ Partial Visibility: This integration is enabled on some, but not all relevant hosts are running it.
Hosts that are running the integration, but where the integration is not enabled, can be found in the Hosts tab of the integrations tile.
Integration views
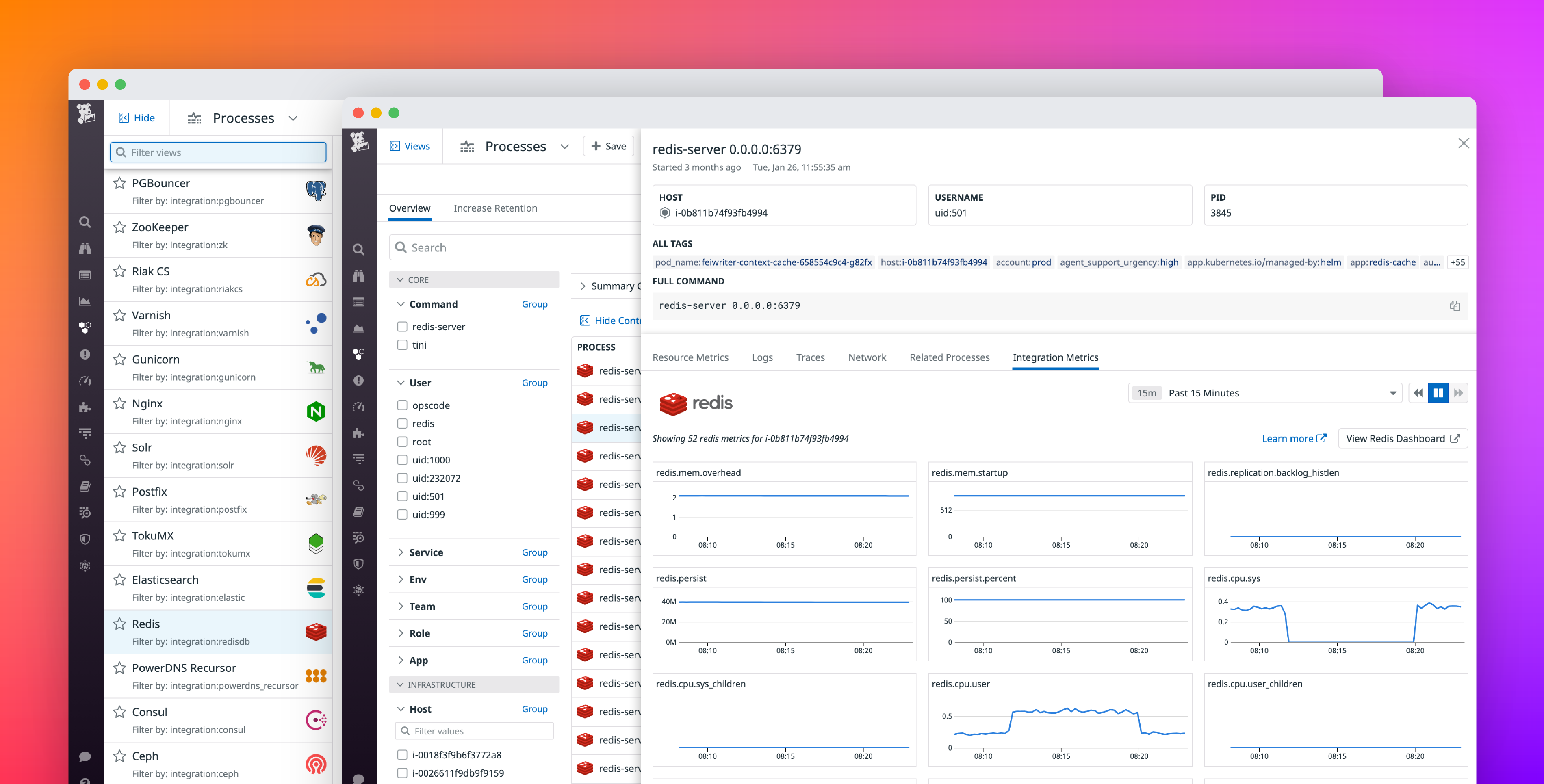
After a third-party software has been detected, Live Processes helps to analyze the performance of that software.
- To start, click on Views at the top right of the page to open a list of pre-set options, including Nginx, Redis, and Kafka.
- Select a view to scope the page to only the processes running that software.
- When inspecting a heavy process, shift to the Integration Metrics tab to analyze the health of the software on the underlying host. If you have already enabled the relevant Datadog integration, you can view all performance metrics collected from the integration to distinguish between a host-level and software-level issue. For instance, seeing correlated spikes in process CPU and MySQL query latency may indicate that an intensive operation, such as a full table scan, is delaying the execution of other MySQL queries relying on the same underlying resources.
You can customize integration views (for example, when aggregating a query for Nginx processes by host) and other custom queries by clicking the +Save button at the top of the page. This saves your query, table column selections, and visualization settings. Create saved views for quick access to the processes you care about without addition configuration, and to share process data with your teammates.
Live Containers
Live Processes adds extra visibility to your container deployments by monitoring the processes running on each of your containers. Click on a container in the Live Containers page to view its process tree, including the commands it is running and their resource consumption. Use this data alongside other container metrics to determine the root cause of failing containers or deployments.
APM
In APM Traces, you can click on a service’s span to see the processes running on its underlying infrastructure. A service’s span processes are correlated with the hosts or pods on which the service runs at the time of the request. Analyze process metrics such as CPU and RSS memory alongside code-level errors to distinguish between application-specific and wider infrastructure issues. Clicking on a process brings you to the Live Processes page. Related processes are not supported for serverless and browser traces.
Cloud Network Monitoring
When you inspect a dependency in the Network Analytics page, you can view processes running on the underlying infrastructure of the endpoints such as services communicating with one another. Use process metadata to determine whether poor network connectivity (indicated by a high number of TCP retransmits) or high network call latency (indicated by high TCP round-trip time) could be due to heavy workloads consuming those endpoints’ resources, and thus, affecting the health and efficiency of their communication.
Real-time monitoring
Processes are normally collected at 10s resolution. While actively working with the Live Processes page, metrics are collected at 2s resolution and displayed in real time, which is important for volatile metrics such as CPU. However, for historical context, metrics are ingested at the default 10s resolution.
- Real-time (2s) data collection is turned off after 30 minutes. To resume real-time collection, refresh the page.
- In container deployments, the
/etc/passwd file mounted into the docker-dd-agent is necessary to collect usernames for each process. This is a public file and the Process Agent does not use any fields except the username. If the Agent is running unprivileged, the mount does not occur. Even without access to the /etc/passwd file, all features except the user metadata field still function. Note: Live Processes only uses the host passwd file and does not perform username resolution for users created within containers.
Further Reading
Documentation, liens et articles supplémentaires utiles: