*Spring Boot 3.3.x et spring-kafka 3.2.x utilisent kafka-clients 3.7.x, qui ne prend pas en charge la génération de lag. Pour résoudre ce problème, mettez à jour votre version de kafka-clients vers la version 3.8.0 ou ultérieure.
Kafka Streams est partiellement pris en charge pour Java et peut entraîner des lacunes dans les mesures de latence.
Déploiements Kafka pris en charge
L’instrumentation de vos consommateurs et producteurs avec Data Streams Monitoring vous permet de visualiser votre topologie et de suivre vos pipelines avec des métriques prêtes à l’emploi, quel que soit le mode de déploiement de Kafka. De plus, les déploiements Kafka suivants bénéficient d’une intégration plus poussée, offrant davantage d’informations sur l’état de votre cluster Kafka :
Data Streams Monitoring uses message headers to propagate context through Kafka streams. If log.message.format.version is set in the Kafka broker configuration, it must be set to 0.11.0.0 or higher. Data Streams Monitoring is not supported for versions lower than this.
Surveillance des connecteurs
Connecteurs Confluent Cloud
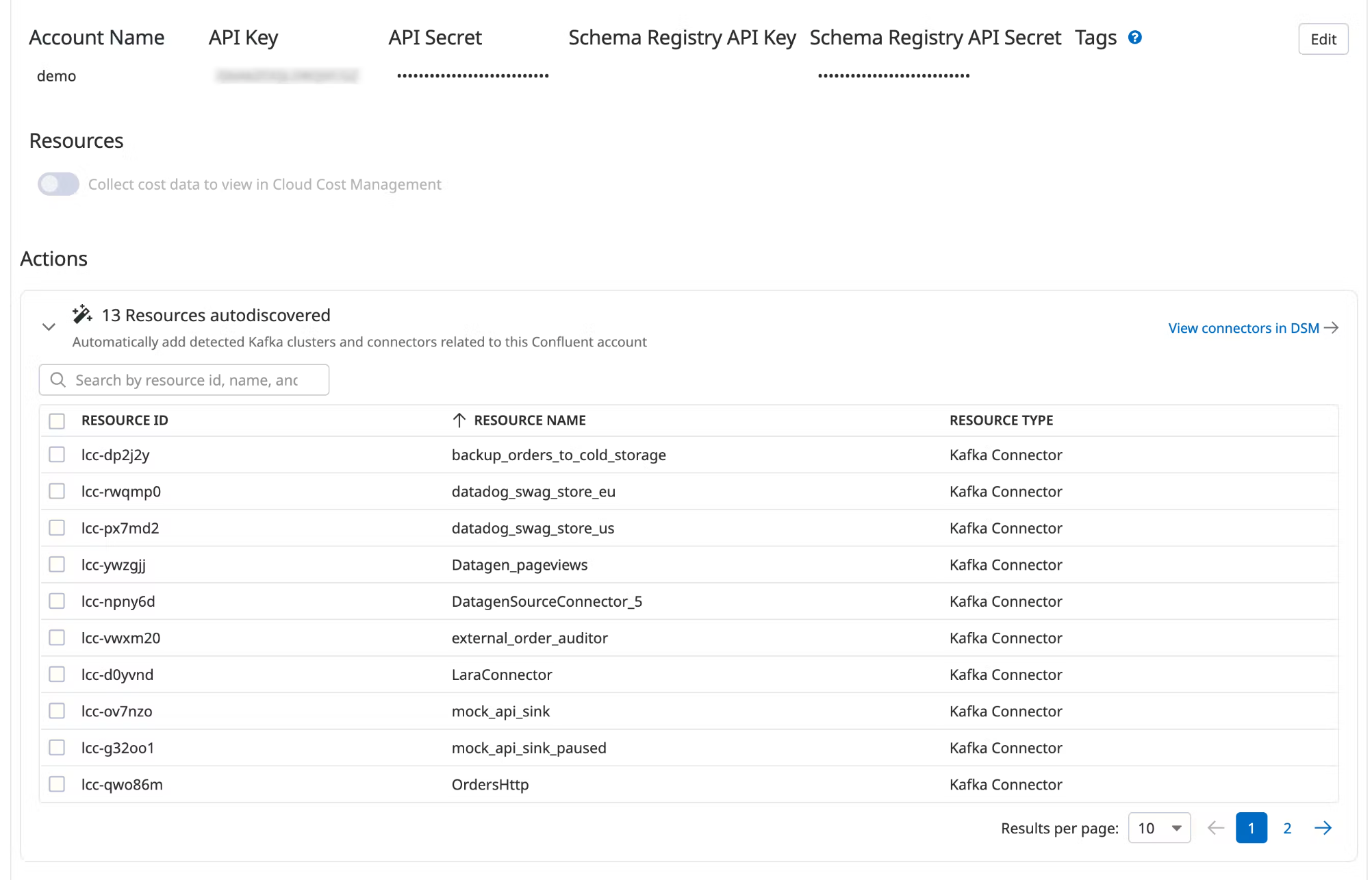
Data Streams Monitoring can automatically discover your Confluent Cloud connectors and visualize them within the context of your end-to-end streaming data pipeline.
Under Actions, a list of resources populates with detected clusters and connectors. Datadog attempts to discover new connectors every time you view this integration tile.
Select the resources you want to add.
Click Add Resources.
Navigate to Data Streams Monitoring to visualize the connectors and track connector status and throughput.
Data Streams Monitoring peut collecter des informations à partir de vos connecteurs Kafka auto-hébergés. Dans Datadog, ces connecteurs apparaissent sous forme de services connectés à des topics Kafka. Datadog collecte le débit vers et depuis tous les topics Kafka. Datadog ne collecte pas le statut des connecteurs ni les sinks et sources des connecteurs Kafka auto-hébergés.
Configuration
Assurez-vous que l’Agent Datadog est en cours d’exécution sur vos workers Kafka Connect.
Vérifiez que dd-trace-java est installé sur vos workers Kafka Connect.
Modifiez vos options Java pour inclure dd-trace-java sur vos nœuds worker Kafka Connect. Par exemple, sur Strimzi, modifiez STRIMZI_JAVA_OPTS pour ajouter -javaagent:/path/to/dd-java-agent.jar.
1
2
rulesets:- %!s(<nil>) # Rules to enforce .
Request a personalized demo
Commencer avec Datadog
Datadog Docs AIYour use of this AI-powered assistant is subject to our Privacy Policy. Please do not submit sensitive or personal information.