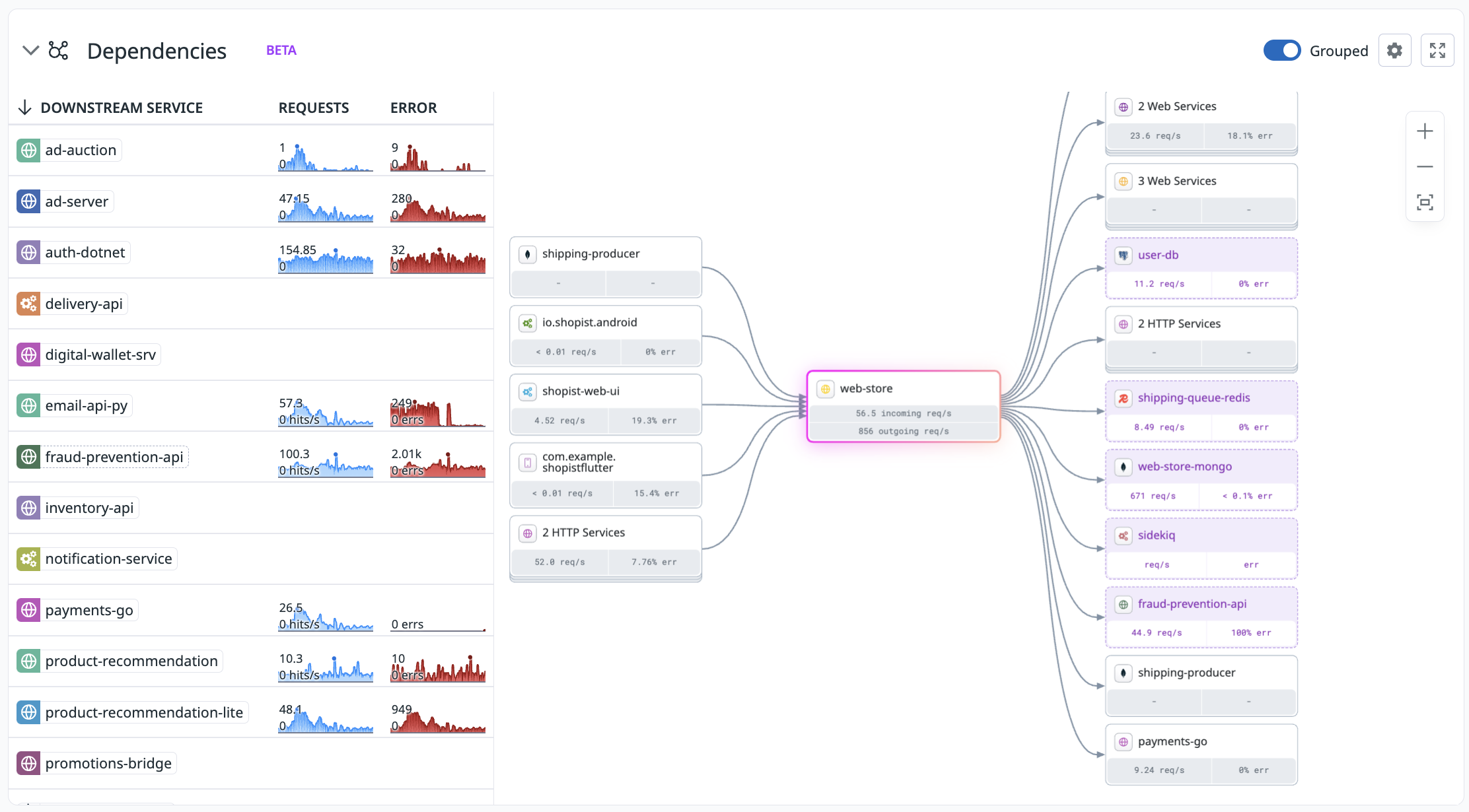
Datadog detecta automáticamente las dependencias de un servicio instrumentado, como bases de datos, colas o API de terceros, incluso si esas dependencias no se instrumentaron directamente. A través del análisis de las solicitudes salientes de tus servicios instrumentados, Datadog infiere la presencia de las dependencias y recopila las métricas de rendimiento asociadas.
Explora los servicios inferidos en el Catálogo de software, filtrando las entradas por tipo de entidad, como bases de datos, colas o API de terceros. Cada página de servicios se ajusta al tipo de servicio que estás investigando. Por ejemplo, las páginas de servicios de bases de datos muestran información específica de las bases de datos y, si estás utilizando Database Monitoring, incluyen datos de monitorización de estas bases de datos.
Configurar servicios inferidos
A partir de la versión 7.60.0 del Datadog Agent, no se necesita ninguna configuración manual para ver servicios inferidos. Las configuraciones necesarias —apm_config.compute_stats_by_span_kind y apm_config.peer_tags_aggregation— están activadas por defecto.
Para las versiones 7.55.1 a 7.59.1 del Datadog Agent, añade lo siguiente a tu archivo de configuración datadog.yaml:
Si utilizas Helm, incluye estas variables de entorno en tu archivovalues.yaml.
Para OpenTelemetry Collector, la versión mínima recomendada es v0.95.0 o posterior de opentelemetry-collector-contrib. En ese caso, actualiza esta configuración:
Para determinar los nombres y tipos de las dependencias de servicio inferidas, Datadog utiliza atributos estándar de tramo y los asigna a atributos de peer.*. Por ejemplo, las API externas inferidas utilizan el esquema de nomenclatura predeterminado net.peer.name como api.stripe.com, api.twilio.com y us6.api.mailchimp.com. Las bases de datos inferidas utilizan el esquema de nomenclatura predeterminado db.instance. Puedes renombrar entidades inferidas creando reglas de renombrado.
Nota: Los valores de atributos pares que coinciden con formatos de direcciones IP (por ejemplo, 127.0.0.1) se modifican y ofuscan con blocked-ip-address para evitar ruidos innecesarios y el etiquetado de métricas con dimensiones de alta cardinalidad. Como resultado, es posible que veas que algunos servicios blocked-ip-address aparecen como dependencias descendentes de tus servicios instrumentados.
Prioridad de etiquetas pares
Para asignar el nombre a las entidades inferidas, Datadog utiliza un orden específico de prioridad entre etiquetas pares, cuando las entidades se definen mediante una combinación de varias etiquetas.
Si la etiqueta con mayor prioridad, como peer.db.name, no se detecta como parte de la instrumentación, Datadog utiliza la segunda etiqueta con mayor prioridad, como peer.hostname, y continúa en ese orden.
Nota: Datadog nunca define el peer.service para bases de datos y colas inferidas. peer.service es el atributo par con mayor prioridad. Si se define, tiene prioridad sobre todos los demás atributos.
Migración a la nomenclatura global de servicios por defecto
Con los servicios inferidos, las dependencias de servicios se detectan automáticamente a partir de los atributos de tramo existentes. Como resultado, no es necesario cambiar los nombres de los servicios (utilizando la etiqueta service) para identificar estas dependencias.
Habilita DD_TRACE_REMOVE_INTEGRATION_SERVICE_NAMES_ENABLED para asegurarte de que ninguna integración Datadog defina nombres de servicios diferentes del nombre global del servicio por defecto. Esto también mejora la forma en que las conexiones servicio-a-servicio y los servicios inferidos son representados en las visualizaciones de Datadog, a través de todos los lenguajes de bibliotecas de rastreo e integraciones compatibles.
La activación de esta opción puede afectar a las métricas existentes de APM, las métricas personalizadas de tramo, los análisis de traza, los filtros de retención, los escaneos de datos confidenciales, los monitores, los dashboards o los notebooks que hacen referencia a los antiguos nombres de servicio. Actualiza estos activos para utilizar la etiqueta de servicio global predeterminada(service:<DD_SERVICE>).
Para obtener instrucciones sobre cómo eliminar servicios anulados y migrar a servicios inferidos, consulta la guía Anulación de servicios.
La función de servicios inferidos no está disponible por defecto en tu centro de datos. Rellena este formulario para solicitar acceso.