Crea reglas de Grok personalizadas para analizar el mensaje completo o un atributo específico de tu evento sin formato. Como práctica recomendada, se sugiere utilizar un máximo de 10 reglas de parseo en un procesador de Grok.
Haz clic en Parse My Events (Analizar mis eventos) a fin de iniciar un conjunto de tres reglas de parseo para los eventos que fluyen a través del pipeline subyacente. Refina la denominación de atributos allí y añade reglas nuevas para otro tipo de eventos si es necesario. Esta característica requiere que los eventos correspondientes se indexen y realmente fluyan. Puedes desactivar o reducir de manera temporal los filtros de exclusión para que funcione.
Selecciona una muestra al hacer clic sobre ella para activar su evaluación con respecto a la regla de parseo y mostrar el resultado en la parte inferior de la pantalla.
Se pueden guardar hasta cinco muestras con el procesador, y cada muestra puede tener hasta 5000 caracteres de longitud. Todas las muestras presentan un estado (coincide o no coincide), que resalta si una de las reglas de parseo del analizador de Grok coincide con la muestra.
Sintaxis de Grok
El analizador de Grok extrae atributos de mensajes de texto semiestructurados. Grok cuenta con patrones reutilizables para analizar enteros, direcciones IP, nombres de host y más. Estos valores se deben enviar al analizador de Grok como cadenas.
Puedes escribir reglas de parseo con la sintaxis %{MATCHER:EXTRACT:FILTER}:
Matcher (Comparador): una regla (posiblemente una referencia a otra regla de token) que describe qué esperar (número, palabra, notSpace, etc.).
Extract (Extracto, es opcional): identificador que representa el destino de captura del fragmento de texto coincidente con el Matcher (Comparador).
Filter (Filtro, es opcional): un posprocesador de la coincidencia para transformarla.
Ejemplo de un evento clásico no estructurado:
john connected on 11/08/2017
Con la siguiente regla de parseo:
MyParsingRule %{word:user} connected on %{date("MM/dd/yyyy"):date}
Después del procesamiento, se genera el siguiente evento estructurado:
Nota:
Si tienes varias reglas de parseo en un único analizador de Grok:
Solo una puede coincidir con cualquier evento. La primera que coincida, de arriba abajo, es la que realiza el parseo.
Cada regla puede hacer referencia a reglas de parseo definidas por encima de esta misma en la lista.
Debes tener nombres de regla únicos dentro del mismo analizador de Grok.
El nombre de la regla solo debe contener: caracteres alfanuméricos, _ y .. Debe comenzar con un carácter alfanumérico.
Las propiedades con valores nulos o vacíos no se muestran.
El comparador de expresiones regulares aplica un ^ implícito, para hacer coincidir el inicio de una cadena, y un $, para el final.
Algunos eventos pueden producir grandes espacios en blanco. Utiliza \n y \s+ para tener en cuenta las líneas nuevas y los espacios en blanco.
Comparador y filtro
En esta lista encontrarás todos los comparadores y filtros implementados de forma nativa por Datadog:
Compara cualquier cadena hasta el siguiente espacio.
boolean("truePattern", "falsePattern")
Compara un booleano y lo analiza, definiendo de manera opcional los patrones true y false (por defecto true y false, ignorando mayúsculas y minúsculas).
numberStr
Compara un número decimal de coma flotante y lo analiza como una cadena.
number
Compara un número decimal de coma flotante y lo analiza como un número de doble precisión.
numberExtStr
Compara un número de coma flotante (con soporte de notación científica) y lo analiza como una cadena.
numberExt
Compara un número de coma flotante (con soporte de notación científica) y lo analiza como un número de doble precisión.
integerStr
Compara un número entero y lo analiza como una cadena.
integer
Compara un número entero y lo analiza como un número entero.
integerExtStr
Compara un número entero (con soporte de notación científica) y lo analiza como una cadena.
integerExt
Compara un número entero (con soporte de notación científica) y lo analiza como un número entero.
word
Compara caracteres de a-z, A-Z, 0-9, incluido el carácter _ (guion bajo).
doubleQuotedString
Compara una cadena entre comillas dobles.
singleQuotedString
Compara una cadena entre comillas simples.
quotedString
Compara una cadena entre comillas dobles o simples.
uuid
Compara un UUID.
mac
Compara una dirección MAC.
ipv4
Compara un IPV4.
ipv6
Compara un IPV6.
ip
Compara un IP (v4 o v6).
hostname
Compara un nombre de host.
ipOrHost
Compara un nombre de host o IP.
port
Compara un número de puerto.
data
Compara cualquier cadena, incluidos espacios y líneas nuevas. Equivale a .* en la expresión regular. Utilízalo cuando ninguno de los patrones anteriores sea apropiado.
number
Analiza una coincidencia como un número de doble precisión.
integer
Analiza una coincidencia como un número entero.
boolean
Analiza cadenas ’true’ y ‘false’ como booleanos ignorando mayúsculas y minúsculas.
nullIf("value")
Devuelve un valor nulo si la coincidencia es igual al valor proporcionado.
json
Analiza un JSON con el formato adecuado.
rubyhash
Analiza un hash de Ruby con el formato adecuado, como por ejemplo {name => "John", "job" => {"company" => "Big Company", "title" => "CTO"}}
useragent([decodeuricomponent:true/false])
Analiza un Agent de usuario y devuelve un objeto JSON que contiene el dispositivo, el sistema operativo y el navegador representado por el Agent. [Verifica el procesador de Agents de usuario][1].
querystring
Extrae todos los pares clave-valor de una cadena de consulta de URL coincidente (por ejemplo, ?productId=superproduct&promotionCode=superpromo).
decodeuricomponent
Descodifica los componentes de URI. Por ejemplo, transforma %2Fservice%2Ftest en /service/test.
Analiza una secuencia de cadena de tokens y la devuelve como una matriz. Consulta el ejemplo de lista a matriz.
url
Analiza una URL y devuelve todos los miembros tokenizados (dominio, parámetros de consulta, puerto, etc.) en un objeto JSON.
Configuración avanzada
En la parte inferior de los cuadros de tu procesador de Grok, se encuentra la sección Advanced Settings (Configuración avanzada):
Parseo de un atributo de texto específico
Utiliza el campo Extract from (Extraer de) para aplicar tu procesador de Grok en un atributo de texto determinado en lugar del atributo message predeterminado.
Por ejemplo, considera un evento que contiene un atributo command.line que se debe analizar como una clave-valor. Podrías analizar este evento de la siguiente manera:
Uso de las reglas de ayuda para factorizar varias reglas de parseo
Utiliza el campo Helper Rules (Reglas de ayuda) a fin de definir tokens para tus reglas de parseo. Las reglas de ayuda te permiten factorizar patrones de Grok en las reglas de parseo. Esto es útil cuando tienes varias reglas en el mismo analizador de Grok que utilizan los mismos tokens.
Ejemplo de un evento clásico no estructurado:
john id:12345 connected on 11/08/2017 on server XYZ in production
Utiliza la siguiente regla de parseo:
MyParsingRule %{user} %{connection} %{server}
Con las siguientes reglas de ayuda:
user %{word:user.name} id:%{integer:user.id}
connection connected on %{date("MM/dd/yyyy"):connect_date}
server on server %{notSpace:server.name} in %{notSpace:server.env}
Ejemplos
Algunos ejemplos que demuestran cómo utilizar los analizadores:
Este es el filtro principal de clave-valor: keyvalue([separatorStr[, characterAllowList[, quotingStr[, delimiter]]]]) donde:
separatorStr: define el separador entre la clave y los valores. Por defecto es =.
characterAllowList: define caracteres de valor de no escape adicionales a los \\w.\\-_@ predeterminados. Solo se utiliza para valores que no están entre comillas (por ejemplo, key=@valueStr).
quotingStr: define las comillas y sustituye la detección de comillas predeterminada: <>, "", ''.
delimiter: define el separador entre los distintos pares clave-valor (por ejemplo, | es el delimitador en key1=value1|key2=value2). Por defecto es (normal space), , and ;.
Utiliza filtros como keyvalue a fin de asignar con mayor facilidad cadenas a atributos para formatos keyvalue o logfmt:
No es necesario que especifiques el nombre de tus parámetros, puesto que ya se encuentran en el evento.
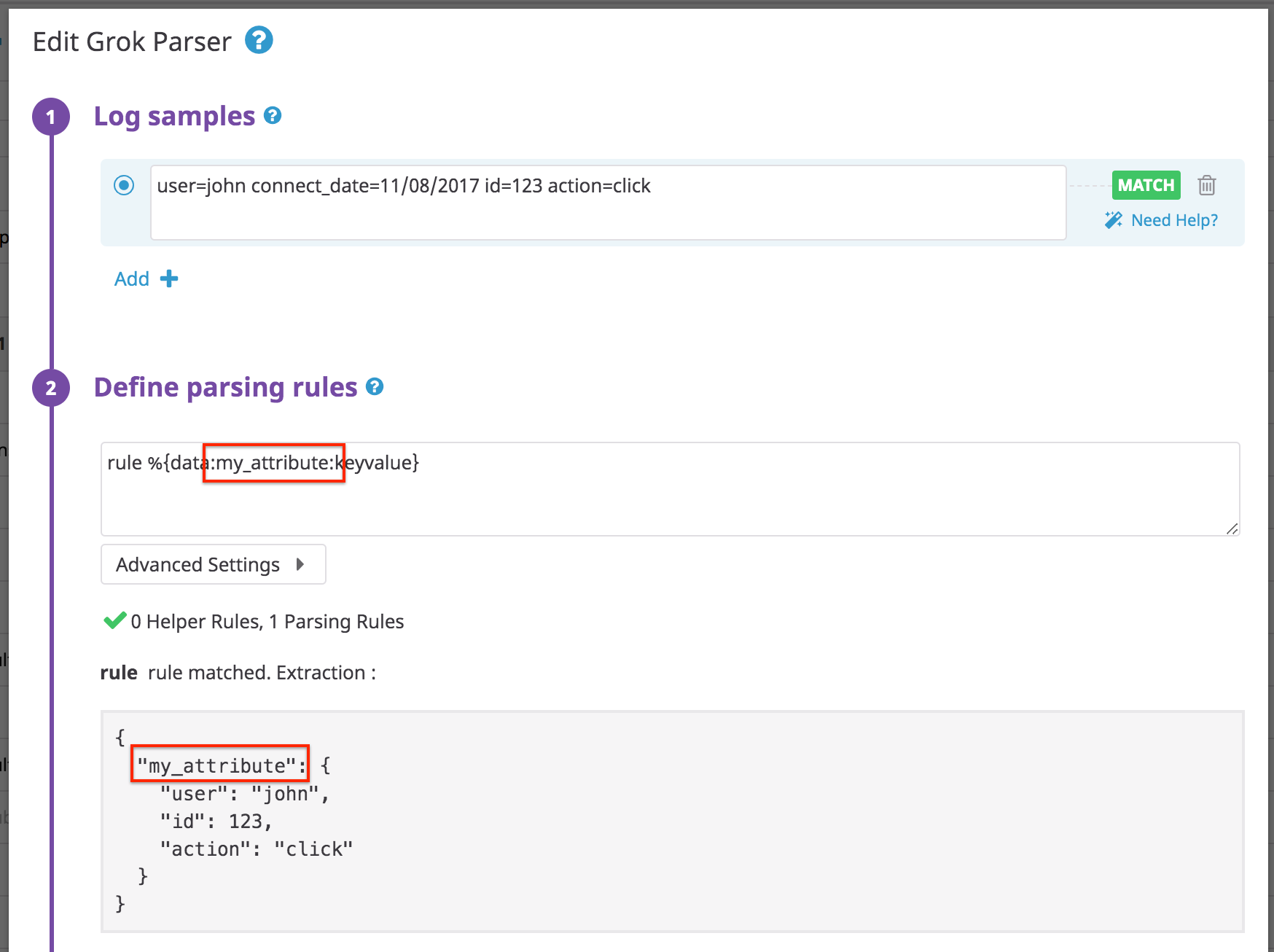
Si añades un atributo de extracciónmy_attribute en tu patrón de reglas verás:
Si = no es el separador predeterminado entre la clave y los valores, añade un parámetro en la regla de parseo con un separador.
Evento:
user: john connect_date: 11/08/2017 id: 123 action: click
Regla:
rule %{data::keyvalue(": ")}
Si el evento contiene caracteres especiales en un valor de atributo, como / en una URL por ejemplo, añádelo a la lista de permitidos en la regla de parseo:
Ejemplo de varias cadenas de comillas: cuando se definen varias cadenas de comillas, el comportamiento predeterminado se reemplaza con un carácter de comillas definido.
La clave-valor siempre coincide con las entradas sin comillas, independientemente de lo que se especifique en quotingStr. Cuando se utilizan caracteres de comillas, se ignora characterAllowList ya que se extrae todo lo que se encuentra entre los caracteres de comillas.
Los valores vacíos (key=) o los valores null (key=null) no se muestran en el JSON de salida.
Si defines un filtro keyvalue en un objeto data, y este filtro no coincide, se devuelve un JSON {} vacío (por ejemplo, entrada: key:=valueStr, regla de parseo: rule_test %{data::keyvalue("=")}, salida: {}).
Definir "" como quotingStr mantiene la configuración predeterminada para las citas.
Parseo de fechas
El comparador de fechas transforma tu marca de tiempo en el formato EPOCH (unidad de medida en milisegundos).
1 Utiliza el parámetro timezone si realizas tus propias localizaciones y tus marcas de tiempo no están en UTC.
Los formatos compatibles para las zonas horarias son:
GMT, UTC, UT o Z
+h, +hh, +hh:mm, -hh:mm, +hhmm, -hhmm, +hh:mm:ss, -hh:mm:ss, +hhmmss o -hhmmss . El rango máximo admitido es de +18:00 a -18:00 inclusive.
Zonas horarias que comienzan por UTC+, UTC-, GMT+, GMT-, UT+ o UT-. El rango máximo admitido es de +18:00 a -18:00 inclusive.
Los ID de zona horaria extraídos de la base de datos TZ. Para obtener más información, consulta los Nombres de bases de datos TZ.
Nota: Analizar una fecha no establece su valor como la fecha oficial del evento. Para ello utiliza el reasignador de fechas de eventos en un procesador posterior.
Patrón alternado
Si tienes eventos con dos formatos posibles que solo difieren en un atributo, establece una única regla alternando con (<REGEX_1>|<REGEX_2>). Esta regla equivale a un OR booleano.
Evento:
john connected on 11/08/2017
12345 connected on 11/08/2017
Regla:
ten en cuenta que «id» es un número entero y no una cadena.
MyParsingRule (%{integer:user.id}|%{word:user.firstname}) connected on %{date("MM/dd/yyyy"):connect_date}
Resultados:
Atributo opcional
Algunos eventos contienen valores que solo aparecen una parte del tiempo. En este caso, haz que la extracción de atributos sea opcional con ()?.
Evento:
john 1234 connected on 11/08/2017
Regla:
MyParsingRule %{word:user.firstname} (%{integer:user.id} )?connected on %{date("MM/dd/yyyy"):connect_date}
Nota: Una regla no coincidirá si incluyes un espacio después de la primera palabra en la sección opcional.
JSON anidado
Utiliza el filtro json para analizar un objeto JSON anidado tras un prefijo de texto sin formato:
Utiliza el filtro array([[openCloseStr, ] separator][, subRuleOrFilter) para extraer un lista en una matriz en un solo atributo. El subRuleOrFilter es opcional y acepta estos filtros.
Evento:
Users [John, Oliver, Marc, Tom] have been added to the database
Regla:
myParsingRule Users %{data:users:array("[]",",")} have been added to the database
Evento:
Users {John-Oliver-Marc-Tom} have been added to the database
Regla:
myParsingRule Users %{data:users:array("{}","-")} have been added to the database
Regla que utiliza subRuleOrFilter:
myParsingRule Users %{data:users:array("{}","-", uppercase)} have been added to the database
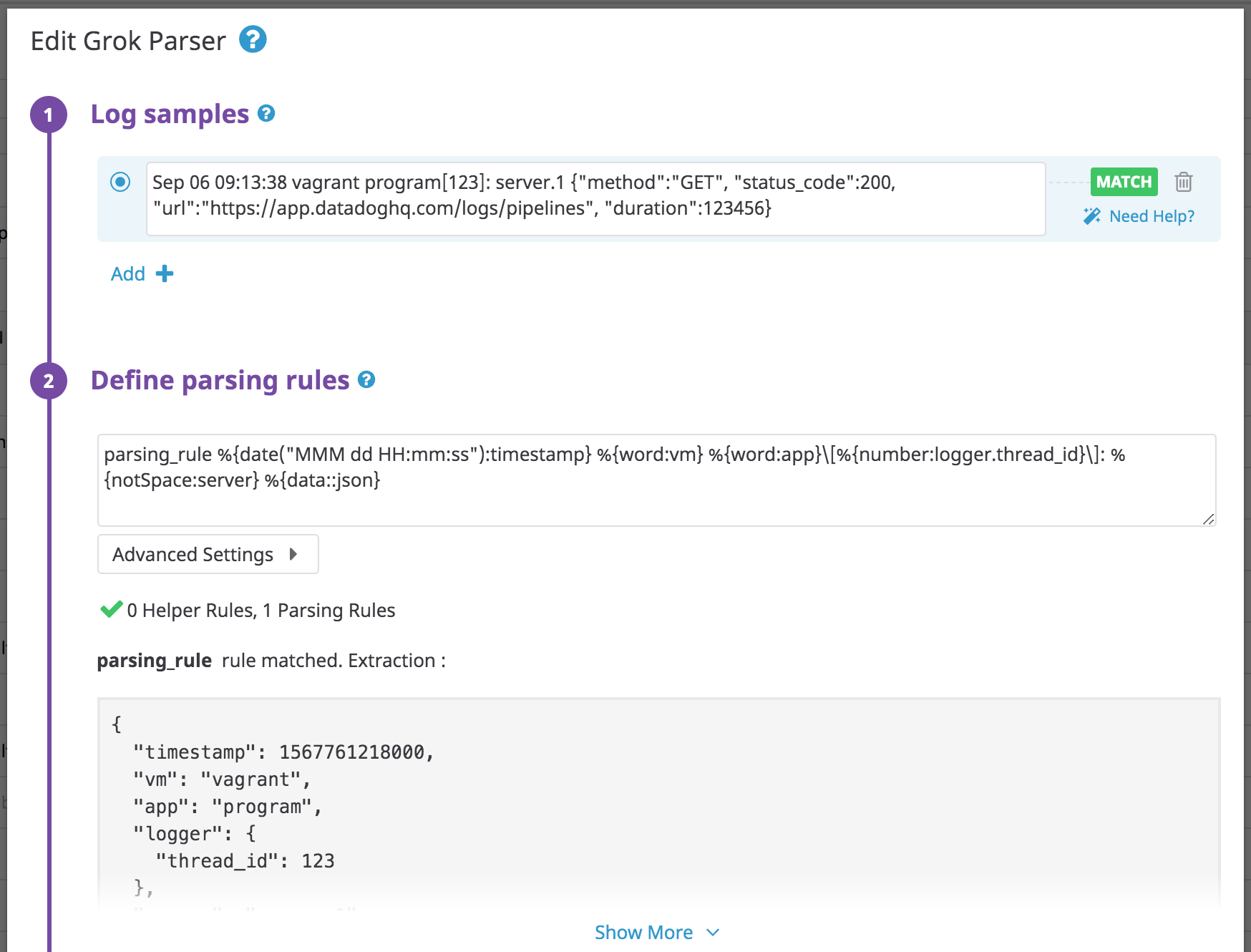
Formato Glog
A veces los componentes de Kubernetes se registran en el formato glog; este ejemplo es del elemento del programador de Kubernetes en la librería de pipelines.
Evento de ejemplo:
W0424 11:47:41.605188 1 authorization.go:47] Authorization is disabled
{"level":"W","timestamp":1587728861605,"logger":{"thread_id":1,"name":"authorization.go"},"lineno":47,"msg":"Authorization is disabled"}
Parseo de XML
El analizador de XML transforma los mensajes con formato XML en JSON.
Evento:
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
</book>
Regla:
rule %{data::xml}
Resultado:
{"book":{"year":"2005","author":"J K. Rowling","category":"CHILDREN","title":{"lang":"en","value":"Harry Potter"}}}
Notas:
Si el XML contiene etiquetas que tienen un atributo y un valor de cadena entre las dos etiquetas, se genera un atributo value. Por ejemplo: <title lang="en">Harry Potter</title> se convierte en {"title": {"lang": "en", "value": "Harry Potter" } }
Las etiquetas repetidas se convierten de manera automática en matrices. Por ejemplo: <bookstore><book>Harry Potter</book><book>Everyday Italian</book></bookstore> se convierte en { "bookstore": { "book": [ "Harry Potter", "Everyday Italian" ] } }
Parseo de CSV
Utiliza el filtro CSV para asignar cadenas a atributos con mayor facilidad cuando estén separadas por un carácter determinado (, por defecto).
El filtro CSV se define como csv(headers[, separator[, quotingcharacter]]) donde:
headers: define el nombre de las claves separadas por ,. Los nombres de las claves deben empezar por un carácter alfabético y pueden contener cualquier carácter alfanumérico además de _.
separator: define los separadores que se utilizan para separar los distintos valores. Solo se acepta un carácter. Por defecto: ,. Nota: Utiliza tab a fin de que el separator represente el carácter de tabulación para los TSV.
quotingcharacter: define el carácter de comillas. Solo se acepta un carácter. Por defecto: "
Nota:
Los valores que contienen un carácter separador se deben colocar entre comillas.
Los valores entre comillas que contienen un carácter de comillas deben tener caracteres de escape entre comillas. Por ejemplo, "" dentro de un valor entre comillas representa ".
Si el evento no contiene el mismo número de valores que el número de claves del encabezado, el analizador de CSV coincidirá con los primeros.
Los números enteros y dobles se convierten de manera automática, si es posible.
Utilizar el comparador de datos para descartar el texto innecesario
Si tienes un evento en el que después de haber analizado lo que se necesita sabes que es seguro descartar el texto posterior a ese punto, puedes utilizar el comparador de datos para hacerlo. Para el siguiente ejemplo de evento, puedes utilizar el comparador de data a fin de descartar el % al final.
Si tus eventos contienen caracteres de control ASCII, se serializarán al ingerirlos. Estos se pueden gestionar escapando de manera explícita del valor serializado dentro de tu analizador de Grok.
1
2
rulesets:- %!s(<nil>) # Rules to enforce .
Solicitar una demostración personalizada
Empezando con Datadog
Ask AI
AI-generated responses may be inaccurate. Verify important info.