Este producto no es compatible con el sitio Datadog seleccionado. ().
Disponible para:
Logs
This processor samples your logging traffic for a representative subset at the rate that you define, dropping the remaining logs. As an example, you can use this processor to sample 20% of logs from a noisy non-critical service.
The sampling only applies to logs that match your filter query and does not impact other logs. If a log is dropped at this processor, none of the processors below receives that log.
To set up the sample processor:
Define a filter query. Only logs that match the specified filter query are sampled at the specified retention rate below. The sampled logs and the logs that do not match the filter query are sent to the next step in the pipeline.
Enter your desired sampling rate in the Retain field. For example, entering 2 means 2% of logs are retained out of all the logs that match the filter query.
Optionally, enter a Group By field to create separate sampling groups for each unique value for that field. For example, status:error and status:info are two unique field values. Each bucket of events with the same field is sampled independently. Click Add Field if you want to add more fields to partition by. See the group-by example.
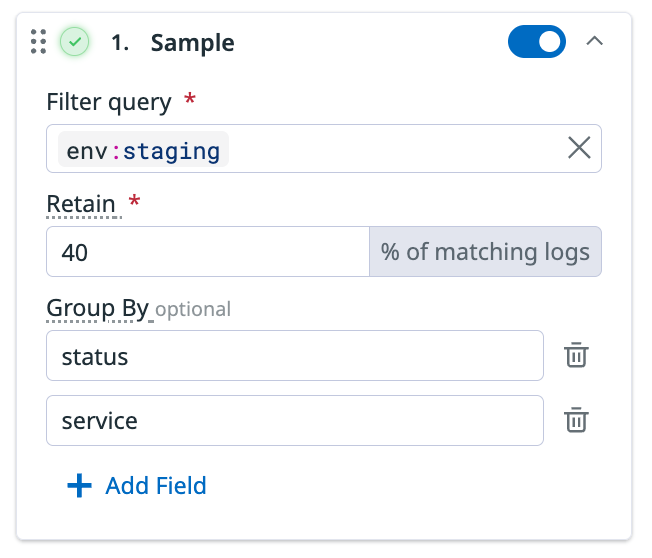
Group-by example
If you have the following setup for the sample processor:
Filter query: env:staging
Retain: 40% of matching logs
Group by: status and service
Then, 40% of logs for each unique combination of status and service from env:staging is retained. For example:
40% of logs with status:info and service:networks are retained.
40% of logs with status:info and service:core-web are retained.
40% of logs with status:error and service:networks are retained.
40% of logs with status:error and service:core-web are retained.
Filter query syntax
Each processor has a corresponding filter query in their fields. Processors only process logs that match their filter query. And for all processors except the Filter processor, logs that do not match the query are sent to the next step of the pipeline. For the Filter processor, logs that do not match the query are dropped.
The following are logs filter query examples:
NOT (status:debug): This filters for logs that do not have the status DEBUG.
status:ok service:flask-web-app: This filters for all logs with the status OK from your flask-web-app service.
This query can also be written as: status:ok AND service:flask-web-app.
host:COMP-A9JNGYK OR host:COMP-J58KAS: This filter query only matches logs from the labeled hosts.
user.status:inactive: This filters for logs with the status inactive nested under the user attribute.
http.status:[200 TO 299] or http.status:{300 TO 399}: These two filters represent the syntax to query a range for http.status. Ranges can be used across any attribute.